

RefSeq: an update on mammalian reference sequences
- PMID: 24259432
- PMCID: PMC3965018
- DOI: 10.1093/nar/gkt1114
RefSeq: an update on mammalian reference sequences
Abstract
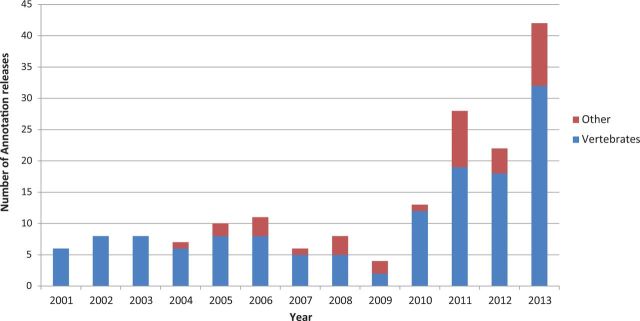
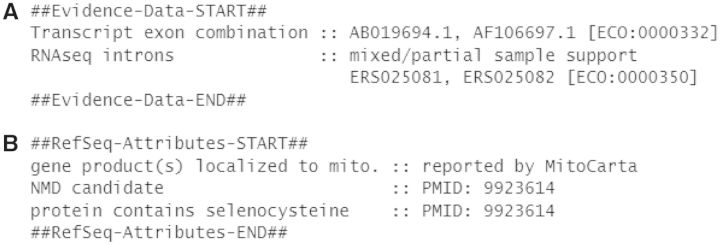
The National Center for Biotechnology Information (NCBI) Reference Sequence (RefSeq) database is a collection of annotated genomic, transcript and protein sequence records derived from data in public sequence archives and from computation, curation and collaboration (http://www.ncbi.nlm.nih.gov/refseq/). We report here on growth of the mammalian and human subsets, changes to NCBI's eukaryotic annotation pipeline and modifications affecting transcript and protein records. Recent changes to NCBI's eukaryotic genome annotation pipeline provide higher throughput, and the addition of RNAseq data to the pipeline results in a significant expansion of the number of transcripts and novel exons annotated on mammalian RefSeq genomes. Recent annotation changes include reporting supporting evidence for transcript records, modification of exon feature annotation and the addition of a structured report of gene and sequence attributes of biological interest. We also describe a revised protein annotation policy for alternatively spliced transcripts with more divergent predicted proteins and we summarize the current status of the RefSeqGene project.
Figures

References
-
- Pruitt KD, Katz KS, Sicotte H, Maglott DR. Introducing RefSeq and LocusLink: curated human genome resources at the NCBI. Trends Genet. 2000;16:44–47. - PubMed
-
- Karro JE, Yan Y, Zheng D, Zhang Z, Carriero N, Cayting P, Harrrison P, Gerstein M. Pseudogene.org: a comprehensive database and comparison platform for pseudogene annotation. Nucleic Acids Res. 2007;35:D55–D60. - PMC - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
