

Decoding neural responses to temporal cues for sound localization
- PMID: 24302571
- PMCID: PMC3844708
- DOI: 10.7554/eLife.01312
Decoding neural responses to temporal cues for sound localization
Abstract
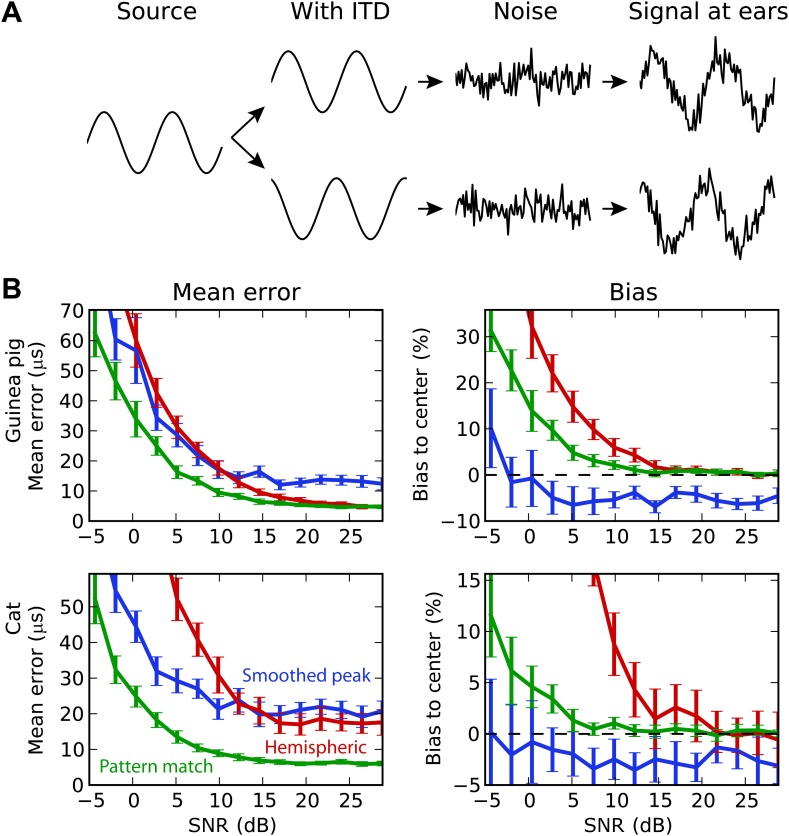
The activity of sensory neural populations carries information about the environment. This may be extracted from neural activity using different strategies. In the auditory brainstem, a recent theory proposes that sound location in the horizontal plane is decoded from the relative summed activity of two populations in each hemisphere, whereas earlier theories hypothesized that the location was decoded from the identity of the most active cells. We tested the performance of various decoders of neural responses in increasingly complex acoustical situations, including spectrum variations, noise, and sound diffraction. We demonstrate that there is insufficient information in the pooled activity of each hemisphere to estimate sound direction in a reliable way consistent with behavior, whereas robust estimates can be obtained from neural activity by taking into account the heterogeneous tuning of cells. These estimates can still be obtained when only contralateral neural responses are used, consistently with unilateral lesion studies. DOI: http://dx.doi.org/10.7554/eLife.01312.001.
Keywords: audition; neural coding; sound localization.
Conflict of interest statement
The authors declare that no competing interests exist.
Figures








References
-
- Aitkin LM, Pettigrew JD, Calford MB, Phillips SC, Wise LZ. 1985. Representation of stimulus azimuth by low-frequency neurons in inferior colliculus of the cat. J Neurophysiol 53:43–59 - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
