

RepeatsDB: a database of tandem repeat protein structures
- PMID: 24311564
- PMCID: PMC3964956
- DOI: 10.1093/nar/gkt1175
RepeatsDB: a database of tandem repeat protein structures
Abstract
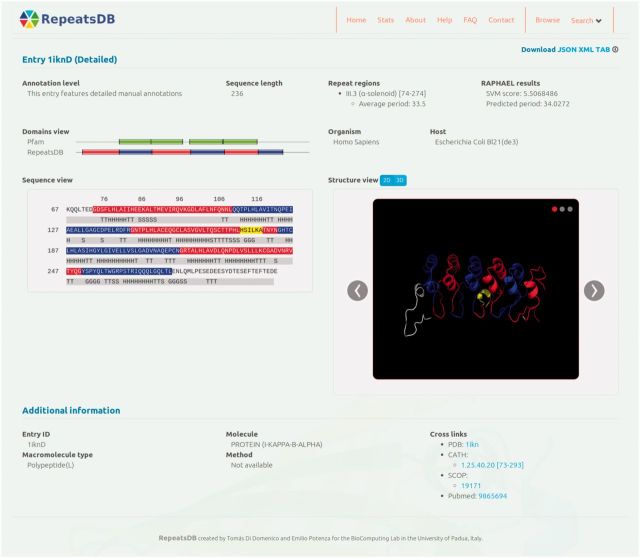
RepeatsDB (http://repeatsdb.bio.unipd.it/) is a database of annotated tandem repeat protein structures. Tandem repeats pose a difficult problem for the analysis of protein structures, as the underlying sequence can be highly degenerate. Several repeat types haven been studied over the years, but their annotation was done in a case-by-case basis, thus making large-scale analysis difficult. We developed RepeatsDB to fill this gap. Using state-of-the-art repeat detection methods and manual curation, we systematically annotated the Protein Data Bank, predicting 10,745 repeat structures. In all, 2797 structures were classified according to a recently proposed classification schema, which was expanded to accommodate new findings. In addition, detailed annotations were performed in a subset of 321 proteins. These annotations feature information on start and end positions for the repeat regions and units. RepeatsDB is an ongoing effort to systematically classify and annotate structural protein repeats in a consistent way. It provides users with the possibility to access and download high-quality datasets either interactively or programmatically through web services.
Figures
References
-
- Wootton JC. Non-globular domains in protein sequences: automated segmentation using complexity measures. Comput. Chem. 1994;18:269–285. - PubMed
-
- Jorda J, Kajava AV. Protein homorepeats sequences, structures, evolution, and functions. Adv. Protein Chem. Struct. Biol. 2010;79:59–88. - PubMed
-
- Biegert A, Söding J. De novo identification of highly diverged protein repeats by probabilistic consistency. Bioinformatics. 2008;24:807–814. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
