

Latent Supervised Learning
- PMID: 24319303
- PMCID: PMC3848255
- DOI: 10.1080/01621459.2013.789695
Latent Supervised Learning
Abstract
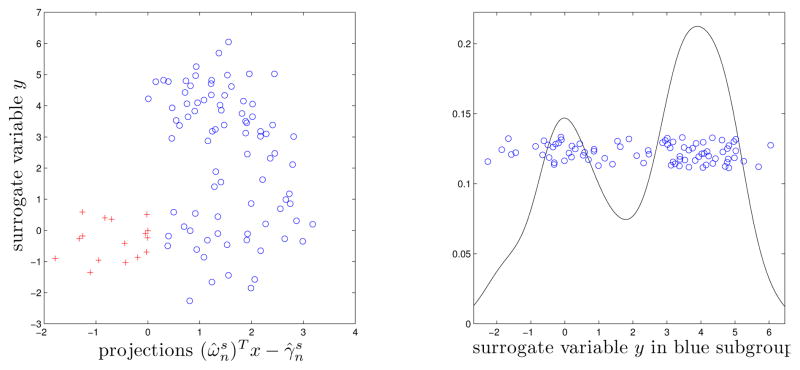
A new machine learning task is introduced, called latent supervised learning, where the goal is to learn a binary classifier from continuous training labels which serve as surrogates for the unobserved class labels. A specific model is investigated where the surrogate variable arises from a two-component Gaussian mixture with unknown means and variances, and the component membership is determined by a hyperplane in the covariate space. The estimation of the separating hyperplane and the Gaussian mixture parameters forms what shall be referred to as the change-line classification problem. A data-driven sieve maximum likelihood estimator for the hyperplane is proposed, which in turn can be used to estimate the parameters of the Gaussian mixture. The estimator is shown to be consistent. Simulations as well as empirical data show the estimator has high classification accuracy.
Keywords: Classification and Clustering; Glivenko-Cantelli classes; Sieve Maximum Likelihood Estimation; Sliced Inverse Regression; Statistical Learning.
Figures





References
-
- Carlstein E, Müller H, Siegmund D. Number v. 23 in Lecture notes-monograph series. Institute of Mathematical Statistics; 1994. Change-Point Problems.
-
- Fleming TR. Surrogate Endpoints And FDA’s Accelerated Approval Process. Health A3. 2005;24(1):67–78. - PubMed
-
- Frank A, Asuncion A. UCI machine learning repository. 2010.
-
- Geman S, Hwang CR. Nonparametric Maximum Likelihood Estimation by the Method of Sieves. The Annals of Statistics. 1982;10(2):401–414.
-
- Grenander U. Abstract Inference. Wiley; 1981.
Publication types
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources