

Sparsity-regularized HMAX for visual recognition
- PMID: 24392078
- PMCID: PMC3879257
- DOI: 10.1371/journal.pone.0081813
Sparsity-regularized HMAX for visual recognition
Abstract
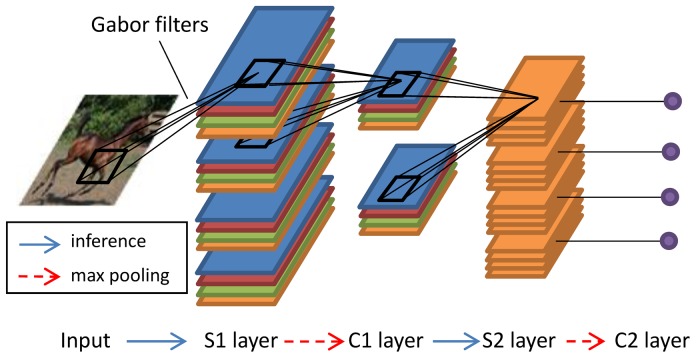
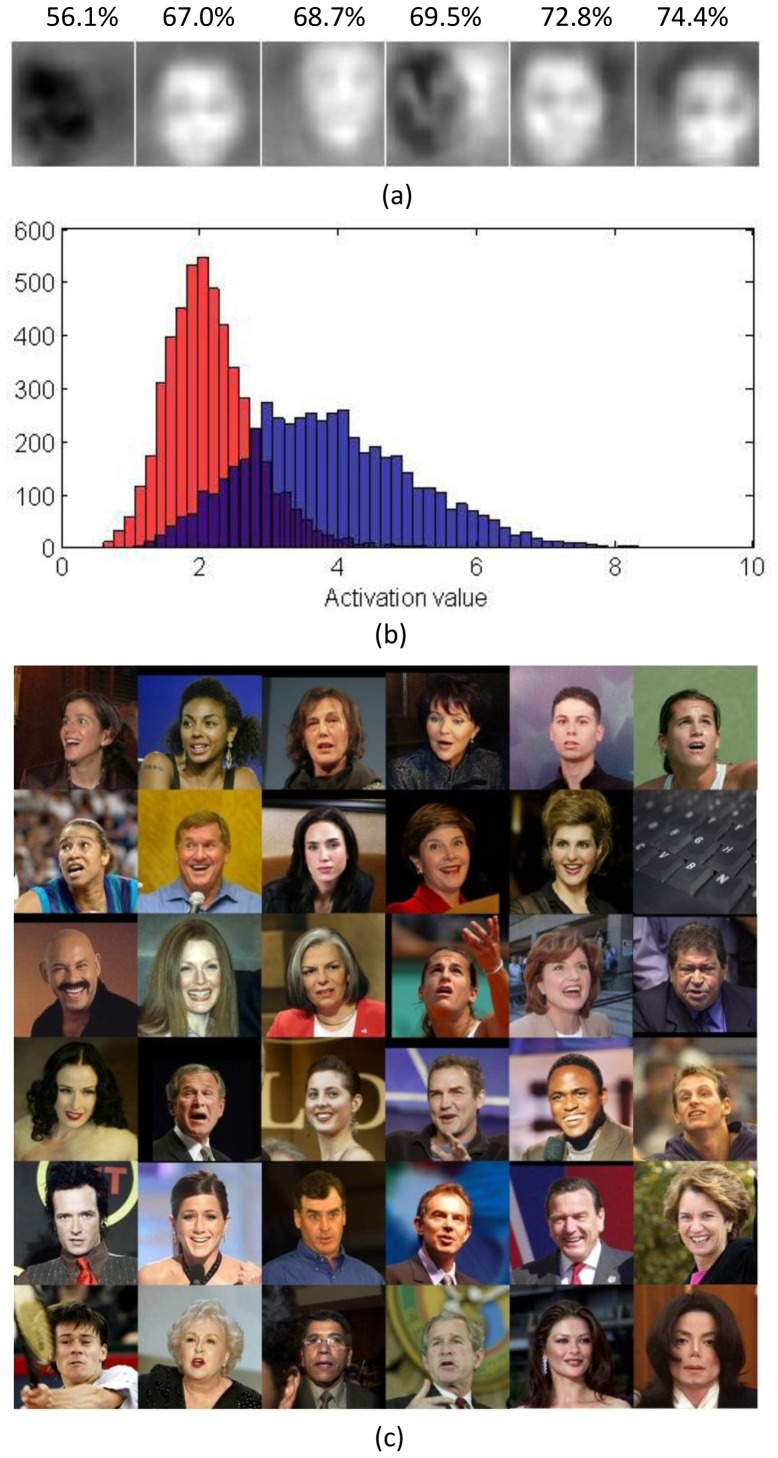
About ten years ago, HMAX was proposed as a simple and biologically feasible model for object recognition, based on how the visual cortex processes information. However, the model does not encompass sparse firing, which is a hallmark of neurons at all stages of the visual pathway. The current paper presents an improved model, called sparse HMAX, which integrates sparse firing. This model is able to learn higher-level features of objects on unlabeled training images. Unlike most other deep learning models that explicitly address global structure of images in every layer, sparse HMAX addresses local to global structure gradually along the hierarchy by applying patch-based learning to the output of the previous layer. As a consequence, the learning method can be standard sparse coding (SSC) or independent component analysis (ICA), two techniques deeply rooted in neuroscience. What makes SSC and ICA applicable at higher levels is the introduction of linear higher-order statistical regularities by max pooling. After training, high-level units display sparse, invariant selectivity for particular individuals or for image categories like those observed in human inferior temporal cortex (ITC) and medial temporal lobe (MTL). Finally, on an image classification benchmark, sparse HMAX outperforms the original HMAX by a large margin, suggesting its great potential for computer vision.
Conflict of interest statement
Figures


 between locations is
between locations is  pixels on the original image space. First row: results on the S1 layer in Figure 2. Second to fourth rows: results on the C1 layer in Figure 2 with max pooling, average pooling and square pooling, respectively, where the pooling ratio
pixels on the original image space. First row: results on the S1 layer in Figure 2. Second to fourth rows: results on the C1 layer in Figure 2 with max pooling, average pooling and square pooling, respectively, where the pooling ratio  . Fifth row: mean of the absolute values of correlation coefficients with respect to the pooling ratio
. Fifth row: mean of the absolute values of correlation coefficients with respect to the pooling ratio  , where the open circles, asterisks and squares denote max pooling, average pooling and square pooling, respectively.
, where the open circles, asterisks and squares denote max pooling, average pooling and square pooling, respectively.








 on the Caltech-101 dataset. The curve shows the average results over ten random splits of train/test samples and the error bars show the standard deviations. The x-axis is in the log scale.
on the Caltech-101 dataset. The curve shows the average results over ten random splits of train/test samples and the error bars show the standard deviations. The x-axis is in the log scale.Similar articles
-
Invariant visual object recognition: biologically plausible approaches.Biol Cybern. 2015 Oct;109(4-5):505-35. doi: 10.1007/s00422-015-0658-2. Epub 2015 Sep 3. Biol Cybern. 2015. PMID: 26335743 Free PMC article.
-
There Is a "U" in Clutter: Evidence for Robust Sparse Codes Underlying Clutter Tolerance in Human Vision.J Neurosci. 2015 Oct 21;35(42):14148-59. doi: 10.1523/JNEUROSCI.1211-15.2015. J Neurosci. 2015. PMID: 26490856 Free PMC article.
-
STDP-based spiking deep convolutional neural networks for object recognition.Neural Netw. 2018 Mar;99:56-67. doi: 10.1016/j.neunet.2017.12.005. Epub 2017 Dec 23. Neural Netw. 2018. PMID: 29328958
-
Invariant visual object recognition: a model, with lighting invariance.J Physiol Paris. 2006 Jul-Sep;100(1-3):43-62. doi: 10.1016/j.jphysparis.2006.09.004. Epub 2006 Oct 30. J Physiol Paris. 2006. PMID: 17071062 Review.
-
Visual Object Recognition: Do We (Finally) Know More Now Than We Did?Annu Rev Vis Sci. 2016 Oct 14;2:377-396. doi: 10.1146/annurev-vision-111815-114621. Epub 2016 Aug 3. Annu Rev Vis Sci. 2016. PMID: 28532357 Review.
Cited by
-
Deep Learning Predicts Correlation between a Functional Signature of Higher Visual Areas and Sparse Firing of Neurons.Front Comput Neurosci. 2017 Oct 30;11:100. doi: 10.3389/fncom.2017.00100. eCollection 2017. Front Comput Neurosci. 2017. PMID: 29163117 Free PMC article.
-
A hierarchical sparse coding model predicts acoustic feature encoding in both auditory midbrain and cortex.PLoS Comput Biol. 2019 Feb 11;15(2):e1006766. doi: 10.1371/journal.pcbi.1006766. eCollection 2019 Feb. PLoS Comput Biol. 2019. PMID: 30742609 Free PMC article.
-
Unsupervised invariance learning of transformation sequences in a model of object recognition yields selectivity for non-accidental properties.Front Comput Neurosci. 2015 Oct 7;9:115. doi: 10.3389/fncom.2015.00115. eCollection 2015. Front Comput Neurosci. 2015. PMID: 26500528 Free PMC article.
-
Learning a Model of Shape Selectivity in V4 Cells Reveals Shape Encoding Mechanisms in the Brain.J Neurosci. 2023 May 31;43(22):4129-4143. doi: 10.1523/JNEUROSCI.1467-22.2023. Epub 2023 Apr 25. J Neurosci. 2023. PMID: 37185098 Free PMC article.
References
-
- Pasupathy A, Connor CE (2002) Population coding of shape in area V4. Nature Neuroscience 5: 1332–1338. - PubMed
-
- Fukushima K (1980) Neocognitron: A self-organizing neural network model for a mechanism of pattern recognition unaffected by shift in position. Biological Cybernetics 36: 193–202. - PubMed
-
- Riesenhuber M, Poggio T (1999) Hierarchical models of object recognition in cortex. Nature Neuroscience 2: 1019–1025. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
Miscellaneous
