

Orbitofrontal cortex as a cognitive map of task space
- PMID: 24462094
- PMCID: PMC4001869
- DOI: 10.1016/j.neuron.2013.11.005
Orbitofrontal cortex as a cognitive map of task space
Abstract
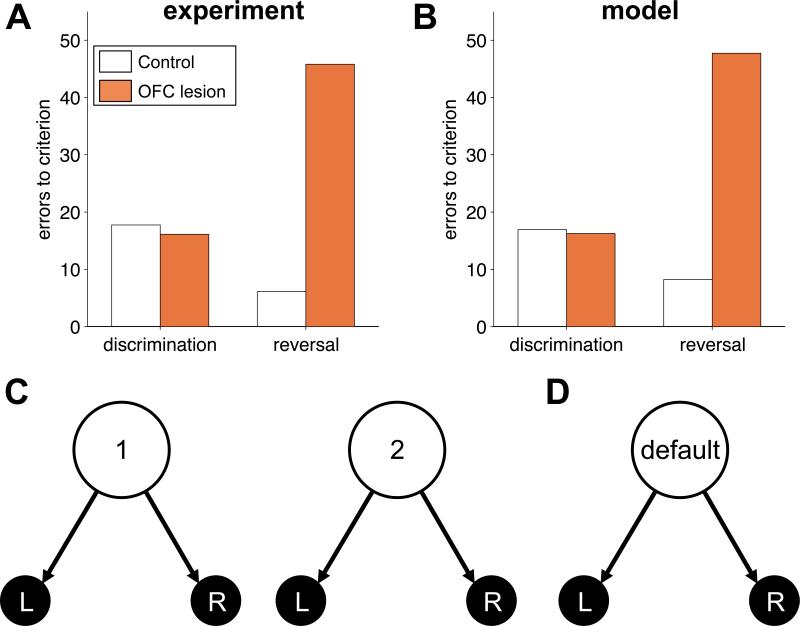
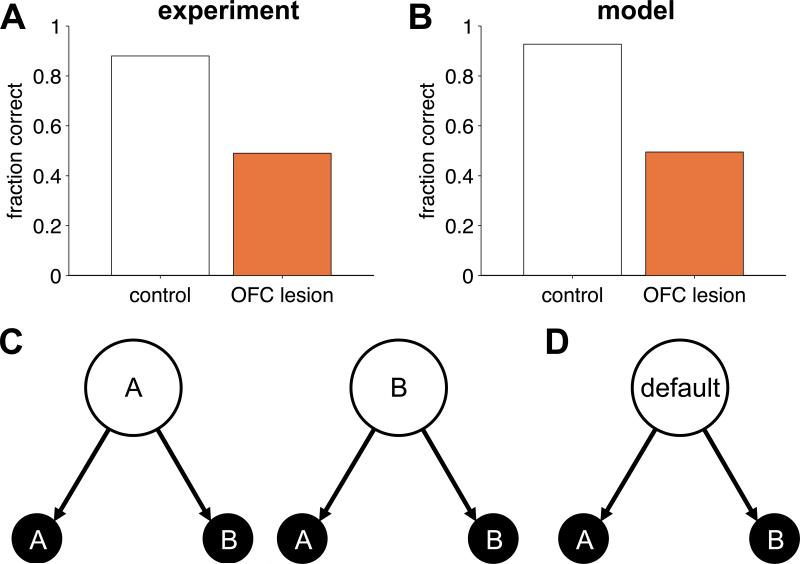
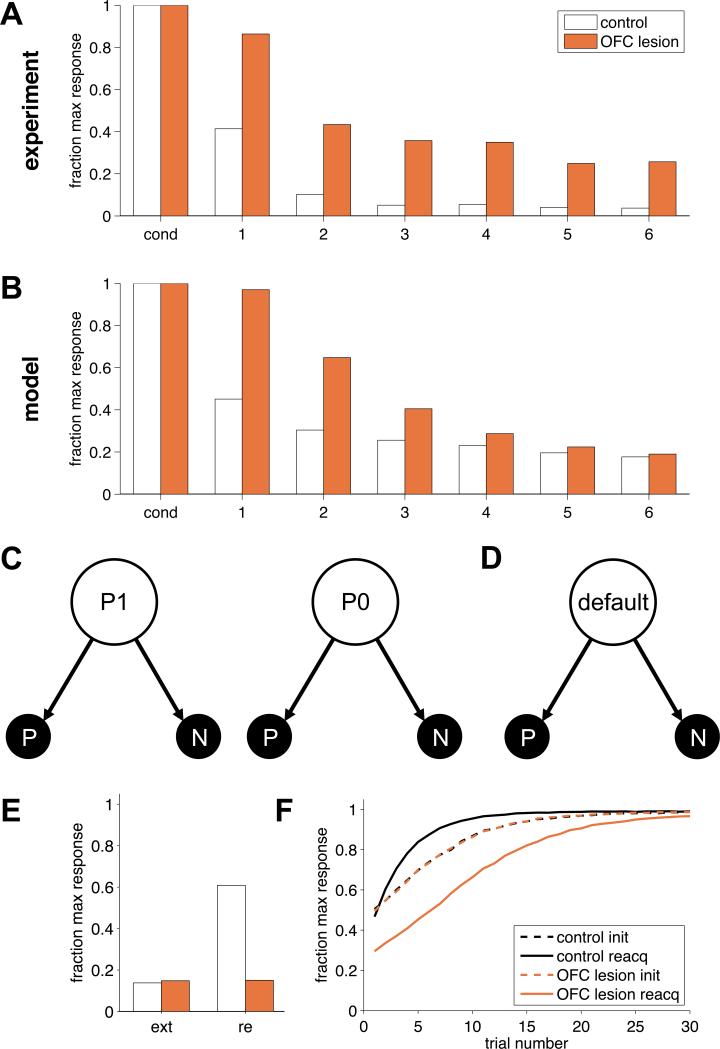
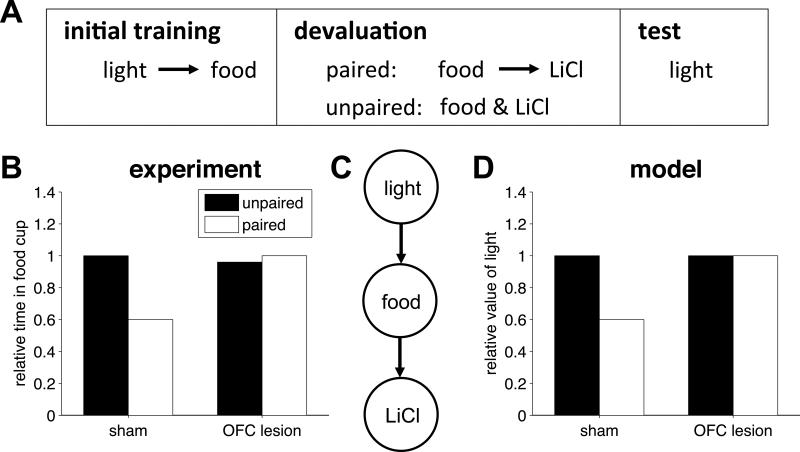
Orbitofrontal cortex (OFC) has long been known to play an important role in decision making. However, the exact nature of that role has remained elusive. Here, we propose a unifying theory of OFC function. We hypothesize that OFC provides an abstraction of currently available information in the form of a labeling of the current task state, which is used for reinforcement learning (RL) elsewhere in the brain. This function is especially critical when task states include unobservable information, for instance, from working memory. We use this framework to explain classic findings in reversal learning, delayed alternation, extinction, and devaluation as well as more recent findings showing the effect of OFC lesions on the firing of dopaminergic neurons in ventral tegmental area (VTA) in rodents performing an RL task. In addition, we generate a number of testable experimental predictions that can distinguish our theory from other accounts of OFC function.
Copyright © 2014 Elsevier Inc. All rights reserved.
Figures
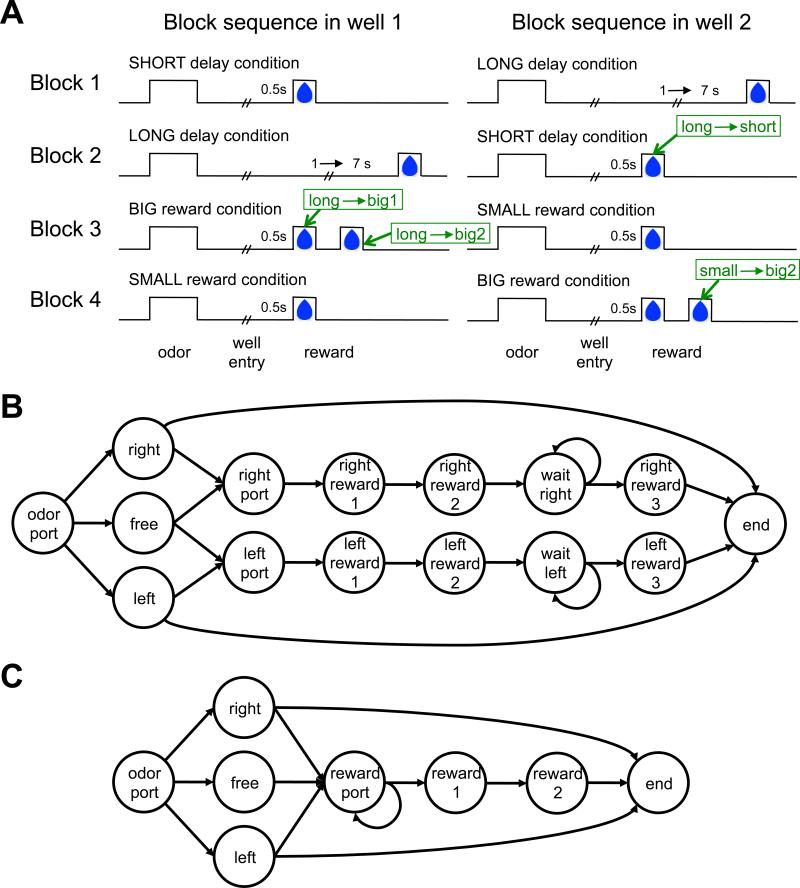
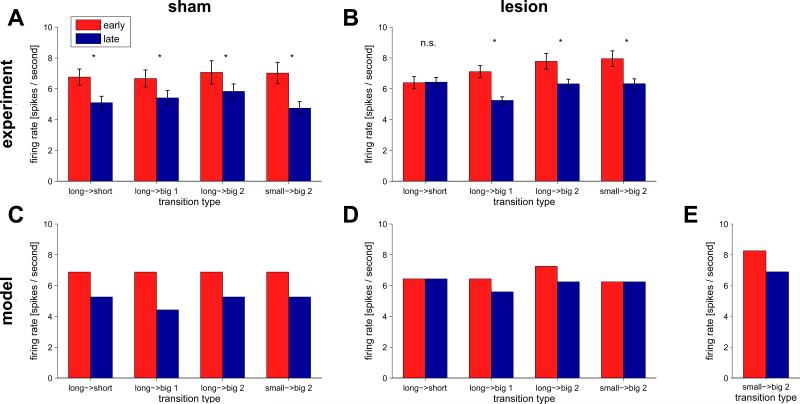
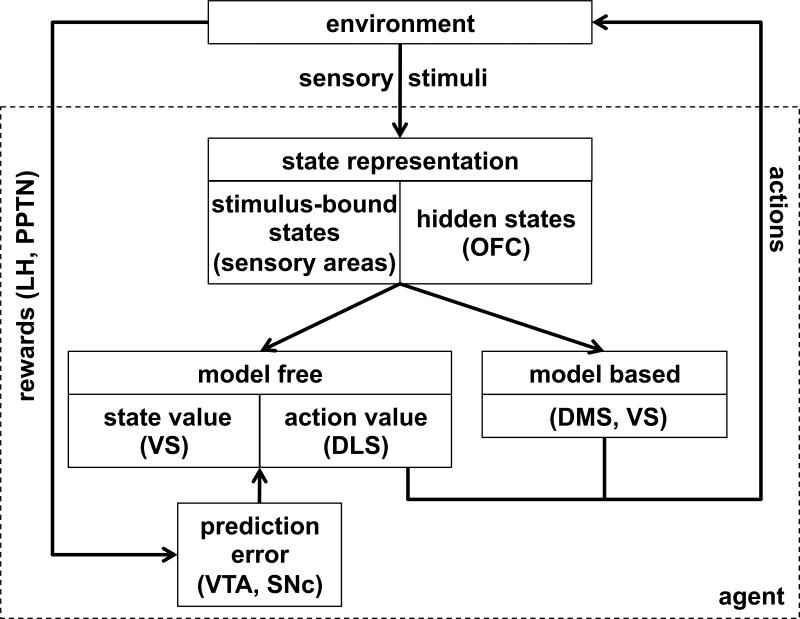
References
-
- Araujo IE, de Gutierrez R, Oliveira-Maia AJ, Pereira A, Jr, Nicolelis MAL, Simon SA. Neural ensemble coding of satiety states. Neuron. 2006;51(4):483–94. - PubMed
-
- Balleine BW, Dickinson A. Goal-directed instrumental action: contingency and incentive learning and their cortical substrates. Neuropharmacology. 1998;37:407–419. - PubMed
-
- Banich MT, Milham MP, Atchley RA, Cohen NJ, Webb A, Wszalek T, Kramer AF, Liang Z, Barad V, Gullett D, Shah C, Brown C. The prefrontal regions play a predominant role in imposing an attentional ‘set’: evidence from fMRI. Cogn Brain Res. 2000;10:1–9. - PubMed
-
- Bohn I, Giertler C, Hauber W. Orbital prefrontal cortex and guidance of instrumental behaviour in rats under reversal conditions. Behav Brain Res. 2003;143:49–56. - PubMed
-
- Bouton ME. Context and behavioral processes in extinction. Learn Mem. 2004;11:485–94. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources