

GENERALIZED DOUBLE PARETO SHRINKAGE
Abstract
We propose a generalized double Pareto prior for Bayesian shrinkage estimation and inferences in linear models. The prior can be obtained via a scale mixture of Laplace or normal distributions, forming a bridge between the Laplace and Normal-Jeffreys' priors. While it has a spike at zero like the Laplace density, it also has a Student's t-like tail behavior. Bayesian computation is straightforward via a simple Gibbs sampling algorithm. We investigate the properties of the maximum a posteriori estimator, as sparse estimation plays an important role in many problems, reveal connections with some well-established regularization procedures, and show some asymptotic results. The performance of the prior is tested through simulations and an application.
Keywords: Heavy tails; LASSO; high-dimensional data; maximum a posteriori estimation; relevance vector machine; robust prior; shrinkage estimation.
Figures
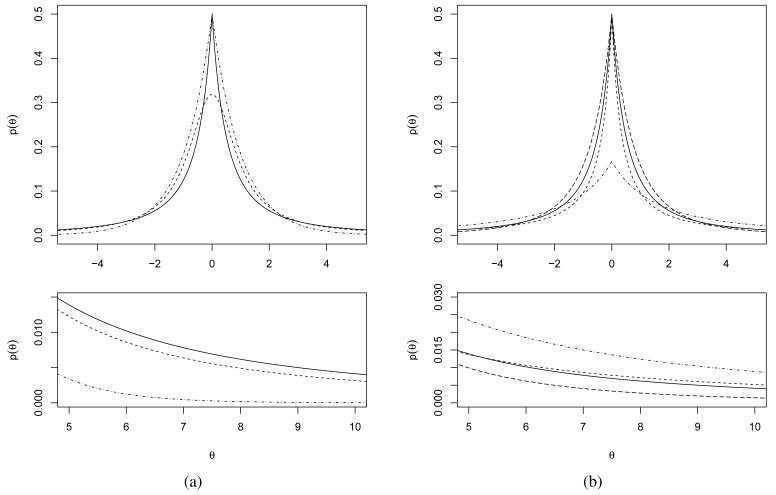
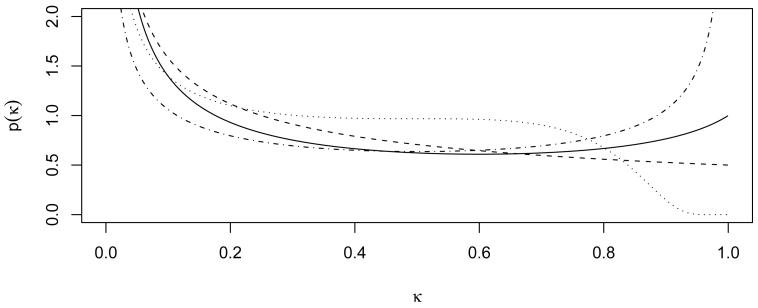
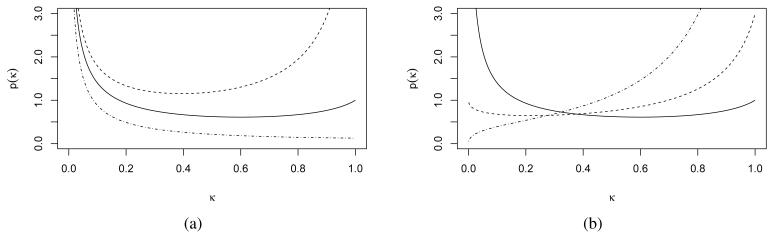
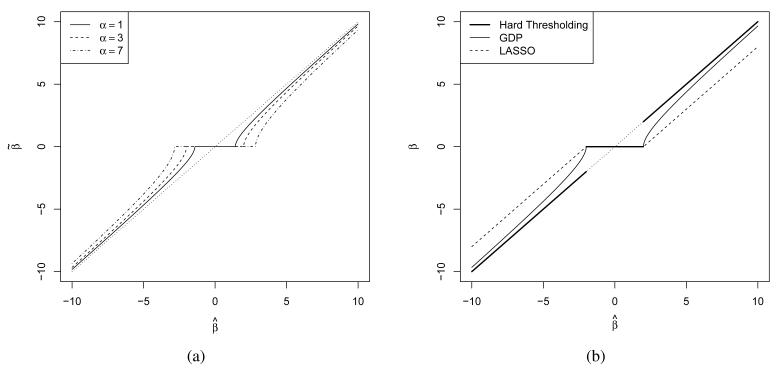
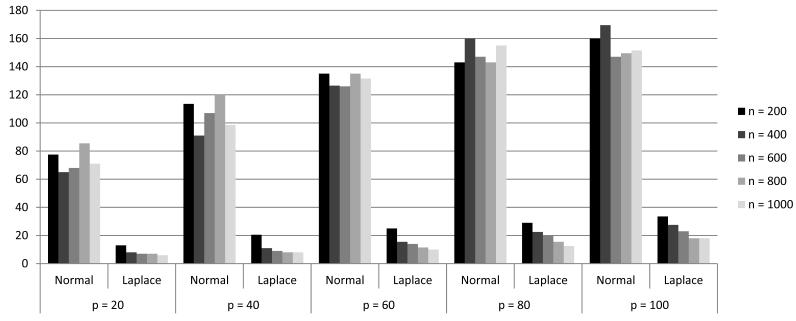
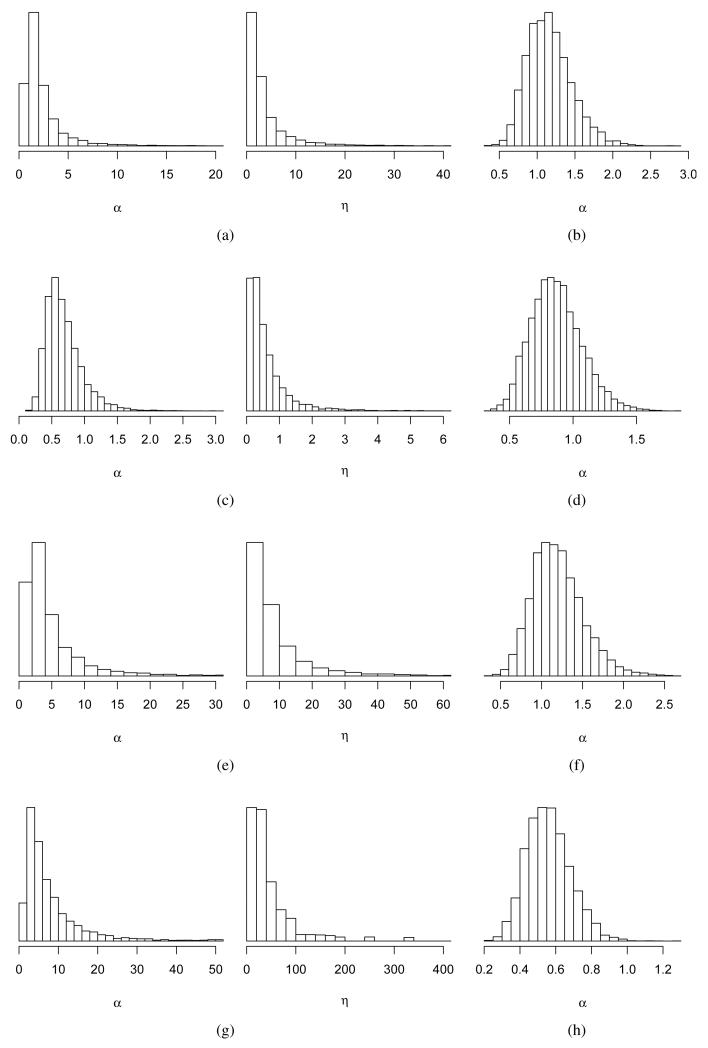

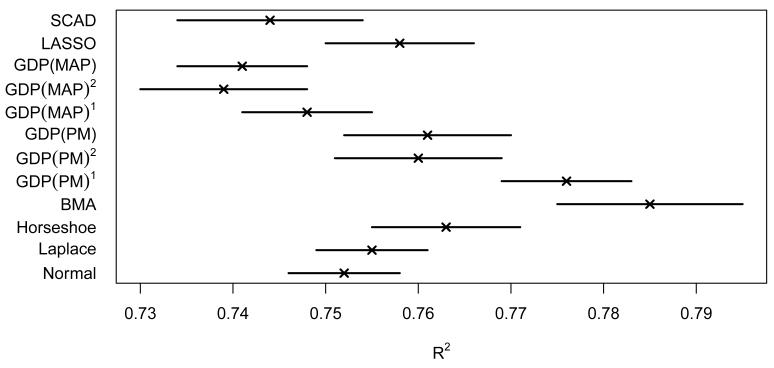
References
-
- Berger J. A robust generalized Bayes estimator and confidence region for a multivariate normal mean. The Annals of Statistics. 1980;8:716–761.
-
- Berger J. Statistical Decision Theory and Bayesian Analysis. Springer; New York: 1985.
-
- Breiman L. Heuristics of instability and stabilization in model selection. The Annals of Statistics. 1996;24:2350–2383.
-
- Breiman L, Friedman JH. Estimating optimal transformations for multiple regression and correlation. Journal of the American Statistical Association. 1985:80.
-
- Candes EJ, Wakin MB, Boyd SP. Enhancing sparsity by reweighted ℓ1 minimization. Journal of Fourier Analysis and Applications. 2008;14:877–905.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources