

Genetics of proteasome diseases
- PMID: 24490108
- PMCID: PMC3892944
- DOI: 10.1155/2013/637629
Genetics of proteasome diseases
Abstract
The proteasome is a large, multiple subunit complex that is capable of degrading most intracellular proteins. Polymorphisms in proteasome subunits are associated with cardiovascular diseases, diabetes, neurological diseases, and cancer. One polymorphism in the proteasome gene PSMA6 (-8C/G) is associated with three different diseases: type 2 diabetes, myocardial infarction, and coronary artery disease. One type of proteasome, the immunoproteasome, which contains inducible catalytic subunits, is adapted to generate peptides for antigen presentation. It has recently been shown that mutations and polymorphisms in the immunoproteasome catalytic subunit PSMB8 are associated with several inflammatory and autoinflammatory diseases including Nakajo-Nishimura syndrome, CANDLE syndrome, and intestinal M. tuberculosis infection. This comprehensive review describes the disease-related polymorphisms in proteasome genes associated with human diseases and the physiological modulation of proteasome function by these polymorphisms. Given the large number of subunits and the central importance of the proteasome in human physiology as well as the fast pace of detection of proteasome polymorphisms associated with human diseases, it is likely that other polymorphisms in proteasome genes associated with diseases will be detected in the near future. While disease-associated polymorphisms are now readily discovered, the challenge will be to use this genetic information for clinical benefit.
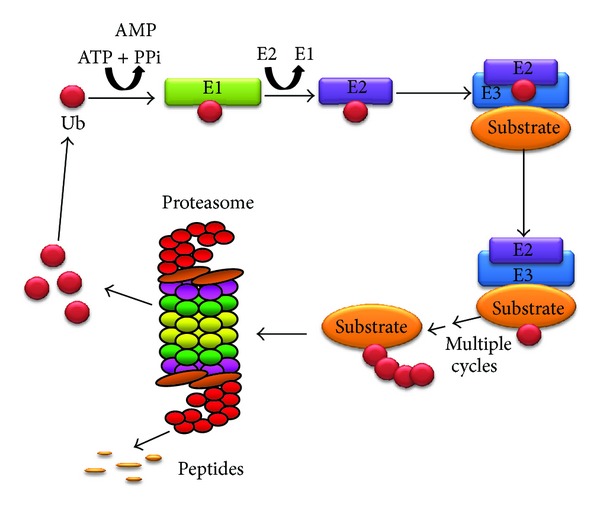
Figures












Similar articles
-
Nakajo-Nishimura syndrome and related proteasome-associated autoinflammatory syndromes.J Inflamm Res. 2019 Sep 17;12:259-265. doi: 10.2147/JIR.S194098. eCollection 2019. J Inflamm Res. 2019. PMID: 31576159 Free PMC article.
-
Induced pluripotent stem cells representing Nakajo-Nishimura syndrome.Inflamm Regen. 2019 May 23;39:11. doi: 10.1186/s41232-019-0099-8. eCollection 2019. Inflamm Regen. 2019. PMID: 31143302 Free PMC article. Review.
-
Proteasome assembly defect due to a proteasome subunit beta type 8 (PSMB8) mutation causes the autoinflammatory disorder, Nakajo-Nishimura syndrome.Proc Natl Acad Sci U S A. 2011 Sep 6;108(36):14914-9. doi: 10.1073/pnas.1106015108. Epub 2011 Aug 18. Proc Natl Acad Sci U S A. 2011. PMID: 21852578 Free PMC article.
-
Nakajo-Nishimura syndrome: an autoinflammatory disorder showing pernio-like rashes and progressive partial lipodystrophy.Allergol Int. 2012 Jun;61(2):197-206. doi: 10.2332/allergolint.11-RAI-0416. Epub 2012 Mar 25. Allergol Int. 2012. PMID: 22441638 Review.
-
A new infant case of Nakajo-Nishimura syndrome with a genetic mutation in the immunoproteasome subunit: an overlapping entity with JMP and CANDLE syndrome related to PSMB8 mutations.Dermatology. 2013;227(1):26-30. doi: 10.1159/000351323. Epub 2013 Aug 8. Dermatology. 2013. PMID: 23942189
Cited by
-
Major Histocompatibility Complex I Expression by Motor Neurons and Its Implication in Amyotrophic Lateral Sclerosis.Front Neurol. 2016 Jun 13;7:89. doi: 10.3389/fneur.2016.00089. eCollection 2016. Front Neurol. 2016. PMID: 27379008 Free PMC article. Review.
-
Drug Repositioning for Fabry Disease: Acetylsalicylic Acid Potentiates the Stabilization of Lysosomal Alpha-Galactosidase by Pharmacological Chaperones.Int J Mol Sci. 2022 May 4;23(9):5105. doi: 10.3390/ijms23095105. Int J Mol Sci. 2022. PMID: 35563496 Free PMC article.
-
DNA Methylation Mediates the Association Between Individual and Neighborhood Social Disadvantage and Cardiovascular Risk Factors.Front Cardiovasc Med. 2022 May 19;9:848768. doi: 10.3389/fcvm.2022.848768. eCollection 2022. Front Cardiovasc Med. 2022. PMID: 35665255 Free PMC article.
-
Immunoproteasome Function in Normal and Malignant Hematopoiesis.Cells. 2021 Jun 22;10(7):1577. doi: 10.3390/cells10071577. Cells. 2021. PMID: 34206607 Free PMC article. Review.
-
Loss of the novel Vcp (valosin containing protein) interactor Washc4 interferes with autophagy-mediated proteostasis in striated muscle and leads to myopathy in vivo.Autophagy. 2018;14(11):1911-1927. doi: 10.1080/15548627.2018.1491491. Epub 2018 Aug 16. Autophagy. 2018. PMID: 30010465 Free PMC article.
References
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
