

A Computational Account of Bilingual Aphasia Rehabilitation
- PMID: 24600315
- PMCID: PMC3940390
- DOI: 10.1017/S1366728912000533
A Computational Account of Bilingual Aphasia Rehabilitation
Abstract
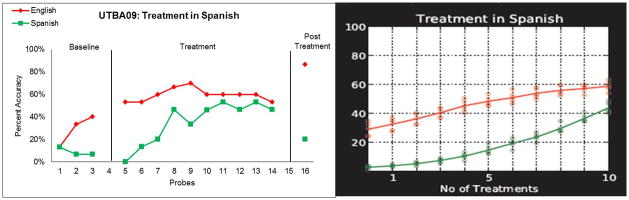
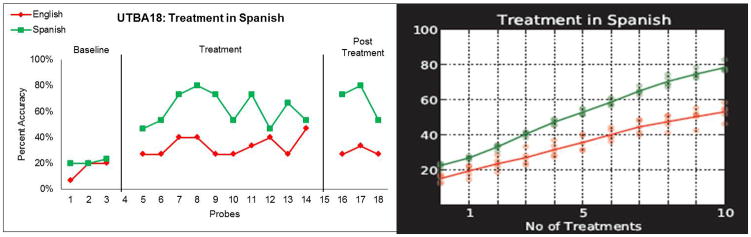
Current research on bilingual aphasia highlights the paucity in recommendations for optimal rehabilitation for bilingual aphasic patients (Roberts & Kiran, 2007; Edmonds & Kiran, 2006). In this paper, we have developed a computational model to simulate an English-Spanish bilingual language system in which language representations can vary by age of acquisition (AoA) and relative proficiency in the two languages to model individual participants. This model is subsequently lesioned by varying connection strengths between the semantic and phonological networks and retrained based on individual patient demographic information to evaluate whether or not the model's prediction of rehabilitation matched the actual treatment outcome. In most cases the model comes close to the target performance subsequent to language therapy in the language trained, indicating the validity of this model in simulating rehabilitation of naming impairment in bilingual aphasia. Additionally, the amount of cross-language transfer is limited both in the patient performance and in the model's predictions and is dependent on that specific patient's AoA, language exposure and language impairment. It also suggests how well alternative treatment scenarios would have fared, including some cases where the alternative would have done better. Overall, the study suggests how computational modeling could be used in the future to design customized treatment recipes that result in better recovery than is currently possible.
Figures





Similar articles
-
Development of a Free Online Interactive Naming Therapy for Bilingual Aphasia.Am J Speech Lang Pathol. 2020 Feb 7;29(1):20-29. doi: 10.1044/2019_AJSLP-19-0035. Epub 2019 Nov 5. Am J Speech Lang Pathol. 2020. PMID: 31689369
-
Predicting treatment outcomes for bilinguals with aphasia using computational modeling: Study protocol for the PROCoM randomised controlled trial.BMJ Open. 2020 Nov 18;10(11):e040495. doi: 10.1136/bmjopen-2020-040495. BMJ Open. 2020. PMID: 33208330 Free PMC article.
-
Understanding the relationship between language proficiency, language impairment and rehabilitation: Evidence from a case study.Clin Linguist Phon. 2011 Jun;25(6-7):565-83. doi: 10.3109/02699206.2011.566664. Epub 2011 Jun 1. Clin Linguist Phon. 2011. PMID: 21631305
-
Language processing in bilingual aphasia: a new insight into the problem.Wiley Interdiscip Rev Cogn Sci. 2016 May-Jun;7(3):180-96. doi: 10.1002/wcs.1384. Epub 2016 Mar 16. Wiley Interdiscip Rev Cogn Sci. 2016. PMID: 26990465 Review.
-
A note on aphasia in bilingual patients: Pitres' and Ribot's laws.Eur Neurol. 2005;54(3):127-31. doi: 10.1159/000089083. Eur Neurol. 2005. PMID: 16244484 Review.
Cited by
-
Self-organizing map models of language acquisition.Front Psychol. 2013 Nov 19;4:828. doi: 10.3389/fpsyg.2013.00828. Front Psychol. 2013. PMID: 24312061 Free PMC article. Review.
-
BiLex: A computational approach to the effects of age of acquisition and language exposure on bilingual lexical access.Brain Lang. 2019 Aug;195:104643. doi: 10.1016/j.bandl.2019.104643. Epub 2019 Jun 24. Brain Lang. 2019. PMID: 31247403 Free PMC article.
-
What Influences Language Impairment in Bilingual Aphasia? A Meta-Analytic Review.Front Psychol. 2019 Apr 4;10:445. doi: 10.3389/fpsyg.2019.00445. eCollection 2019. Front Psychol. 2019. PMID: 31024369 Free PMC article.
-
AI-assisted assessment and treatment of aphasia: a review.Front Public Health. 2024 Aug 29;12:1401240. doi: 10.3389/fpubh.2024.1401240. eCollection 2024. Front Public Health. 2024. PMID: 39281082 Free PMC article. Review.
-
Understanding, facilitating and predicting aphasia recovery after rehabilitation.Int J Speech Lang Pathol. 2022 Jun;24(3):248-259. doi: 10.1080/17549507.2022.2075036. Epub 2022 May 23. Int J Speech Lang Pathol. 2022. PMID: 35603543 Free PMC article. Review.
References
-
- Baron R, Hanley JR, Dell GS, Kay J. Testing single- and dual-route computational models of auditory repetition with new data from six aphasic patients. Aphasiology. 2008;22(1):1–15. doi: 10.1080/02687030600927092. - DOI
-
- Callan DE, Kent RD, Guenther FH, Vorperian HK. An auditory-feedback-based neural network model of speech production that is robust to developmental changes in the size and shape of the articulatory system. Journal of speech, language, and hearing research. 2000;43(3):721–736. - PubMed
Grants and funding
LinkOut - more resources
Full Text Sources