

A modified generalized Fisher method for combining probabilities from dependent tests
- PMID: 24600471
- PMCID: PMC3929847
- DOI: 10.3389/fgene.2014.00032
A modified generalized Fisher method for combining probabilities from dependent tests
Abstract
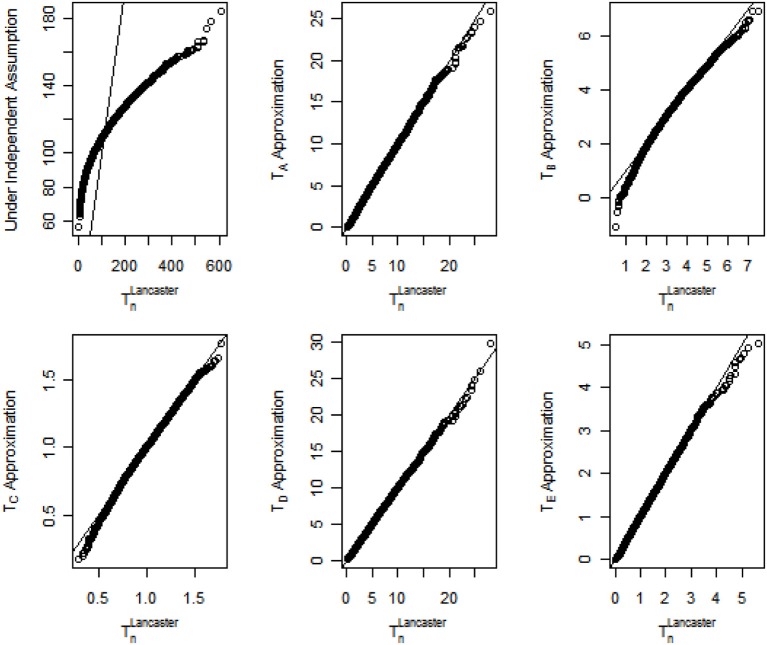
Rapid developments in molecular technology have yielded a large amount of high throughput genetic data to understand the mechanism for complex traits. The increase of genetic variants requires hundreds and thousands of statistical tests to be performed simultaneously in analysis, which poses a challenge to control the overall Type I error rate. Combining p-values from multiple hypothesis testing has shown promise for aggregating effects in high-dimensional genetic data analysis. Several p-value combining methods have been developed and applied to genetic data; see Dai et al. (2012b) for a comprehensive review. However, there is a lack of investigations conducted for dependent genetic data, especially for weighted p-value combining methods. Single nucleotide polymorphisms (SNPs) are often correlated due to linkage disequilibrium (LD). Other genetic data, including variants from next generation sequencing, gene expression levels measured by microarray, protein and DNA methylation data, etc. also contain complex correlation structures. Ignoring correlation structures among genetic variants may lead to severe inflation of Type I error rates for omnibus testing of p-values. In this work, we propose modifications to the Lancaster procedure by taking the correlation structure among p-values into account. The weight function in the Lancaster procedure allows meaningful biological information to be incorporated into the statistical analysis, which can increase the power of the statistical testing and/or remove the bias in the process. Extensive empirical assessments demonstrate that the modified Lancaster procedure largely reduces the Type I error rates due to correlation among p-values, and retains considerable power to detect signals among p-values. We applied our method to reassess published renal transplant data, and identified a novel association between B cell pathways and allograft tolerance.
Keywords: correlated p-values; generalized Fisher method (Lancaster procedure); high dimensional genetic data; multiple hypothesis testing; weight function.
Figures
References
-
- Bahadur R. R. (1967). Rates of convergence of estimates and test statistics. Ann. Math. Stat. 38, 303–324 10.1214/aoms/1177698949 - DOI
-
- Benjamini Y., Hochberg Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Stat. Soc. B 57, 289–833 10.2307/2346101 - DOI
-
- Benjamini Y., Hochberg Y. (1997). Multiple hypothesis testing with weights. Scand. J. Stat. 24, 407–417 10.1111/1467-9469.00072 - DOI
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials