

Latent memory of unattended stimuli reactivated by practice: an FMRI study on the role of consciousness and attention in learning
- PMID: 24603676
- PMCID: PMC3946088
- DOI: 10.1371/journal.pone.0090098
Latent memory of unattended stimuli reactivated by practice: an FMRI study on the role of consciousness and attention in learning
Abstract
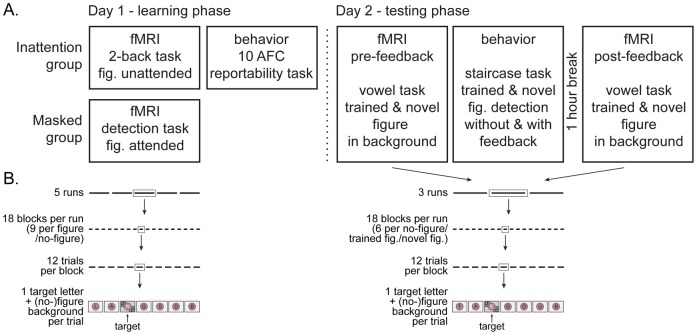
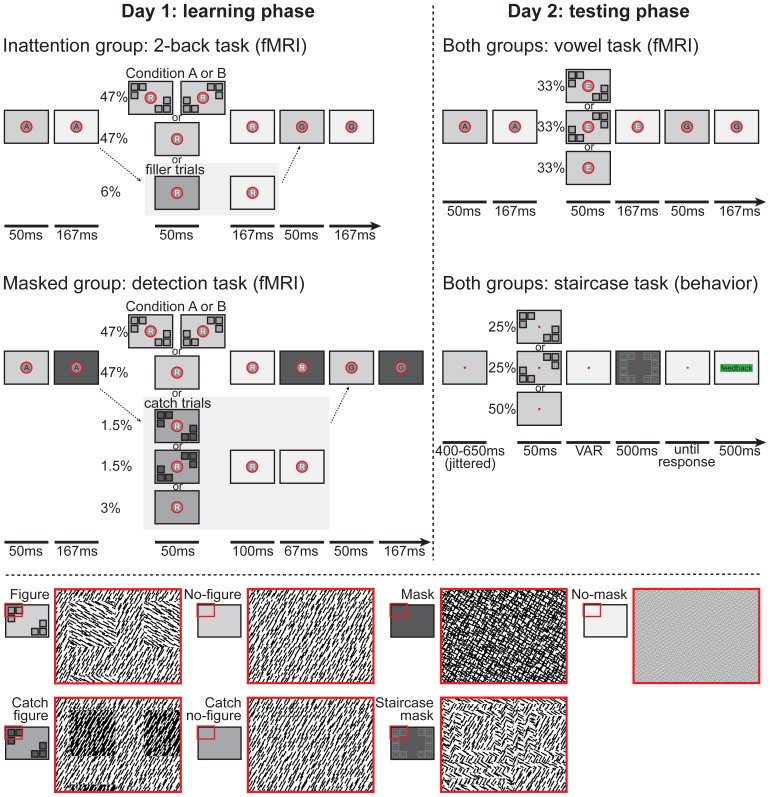
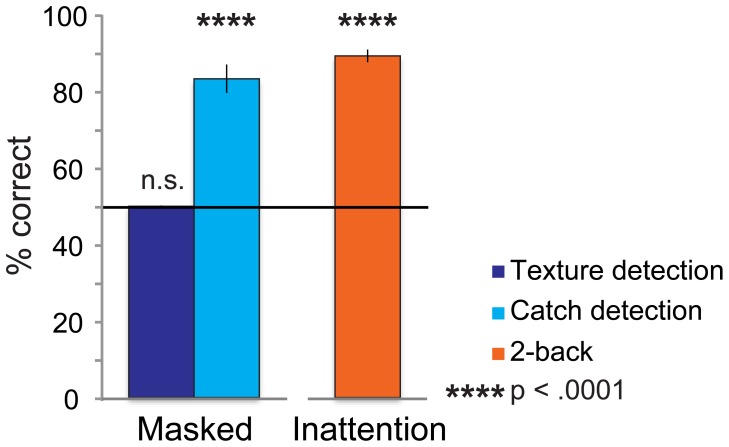
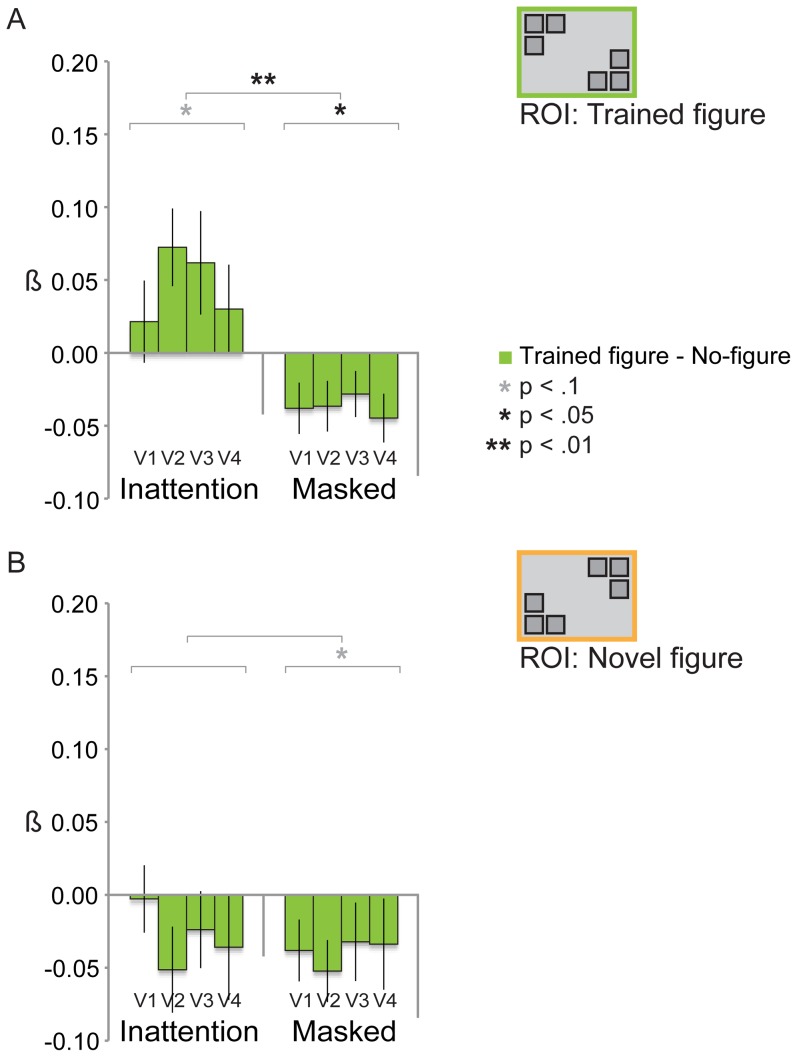
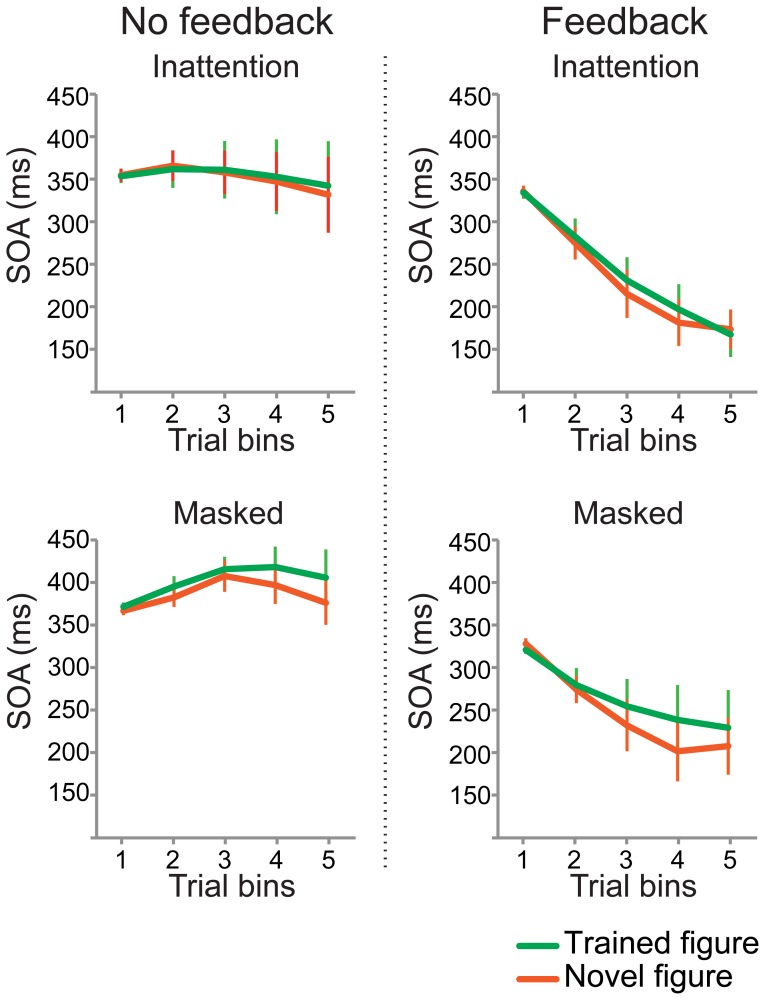
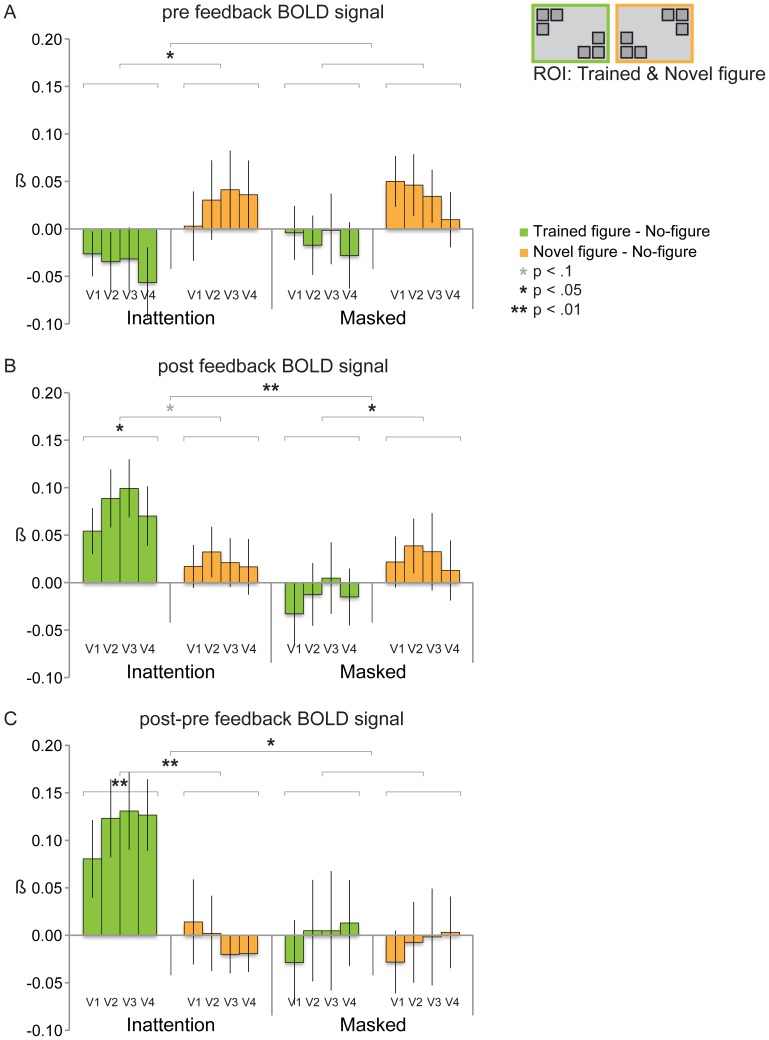
Although we can only report about what is in the focus of our attention, much more than that is actually processed. And even when attended, stimuli may not always be reportable, for instance when they are masked. A stimulus can thus be unreportable for different reasons: the absence of attention or the absence of a conscious percept. But to what extent does the brain learn from exposure to these unreportable stimuli? In this fMRI experiment subjects were exposed to textured figure-ground stimuli, of which reportability was manipulated either by masking (which only interferes with consciousness) or with an inattention paradigm (which only interferes with attention). One day later learning was assessed neurally and behaviorally. Positive neural learning effects were found for stimuli presented in the inattention paradigm; for attended yet masked stimuli negative adaptation effects were found. Interestingly, these inattentional learning effects only became apparent in a second session after a behavioral detection task had been administered during which performance feedback was provided. This suggests that the memory trace that is formed during inattention is latent until reactivated by behavioral practice. However, no behavioral learning effects were found, therefore we cannot conclude that perceptual learning has taken place for these unattended stimuli.
Conflict of interest statement
Figures
Similar articles
-
Does perceptual learning require consciousness or attention?J Cogn Neurosci. 2013 Oct;25(10):1579-96. doi: 10.1162/jocn_a_00424. Epub 2013 May 22. J Cogn Neurosci. 2013. PMID: 23691987
-
Selective attention modulates neural substrates of repetition priming and "implicit" visual memory: suppressions and enhancements revealed by FMRI.J Cogn Neurosci. 2005 Aug;17(8):1245-60. doi: 10.1162/0898929055002409. J Cogn Neurosci. 2005. PMID: 16197681 Clinical Trial.
-
Learning rapidly about the relevance of visual cues requires conscious awareness.Q J Exp Psychol (Hove). 2018 Aug;71(8):1698-1713. doi: 10.1080/17470218.2017.1373834. Epub 2018 Jan 1. Q J Exp Psychol (Hove). 2018. PMID: 30027836
-
From brain synapses to systems for learning and memory: Object recognition, spatial navigation, timed conditioning, and movement control.Brain Res. 2015 Sep 24;1621:270-93. doi: 10.1016/j.brainres.2014.11.018. Epub 2014 Nov 20. Brain Res. 2015. PMID: 25446436 Review.
-
Towards an animal model of consciousness based on the platform theory.Behav Brain Res. 2022 Feb 15;419:113695. doi: 10.1016/j.bbr.2021.113695. Epub 2021 Nov 29. Behav Brain Res. 2022. PMID: 34856300 Review.
References
-
- Rock I, Linnett CM, Grant P, Mack A (1992) Perception without attention—results of a new method. Cogn Psychol 502–534. - PubMed
-
- Simons DJ, Chabris CF (1999) Gorillas in our midst: sustained inattentional blindness for dynamic events. Perception 28: 1059–1074. - PubMed
-
- Pitts MA, Martínez A, Hillyard SA (2012) Visual Processing of Contour Patterns under Conditions of Inattentional Blindness. Journal of cognitive neuroscience 24: 287–303. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
