

Subtelomeric CTCF and cohesin binding site organization using improved subtelomere assemblies and a novel annotation pipeline
- PMID: 24676094
- PMCID: PMC4032850
- DOI: 10.1101/gr.166983.113
Subtelomeric CTCF and cohesin binding site organization using improved subtelomere assemblies and a novel annotation pipeline
Abstract
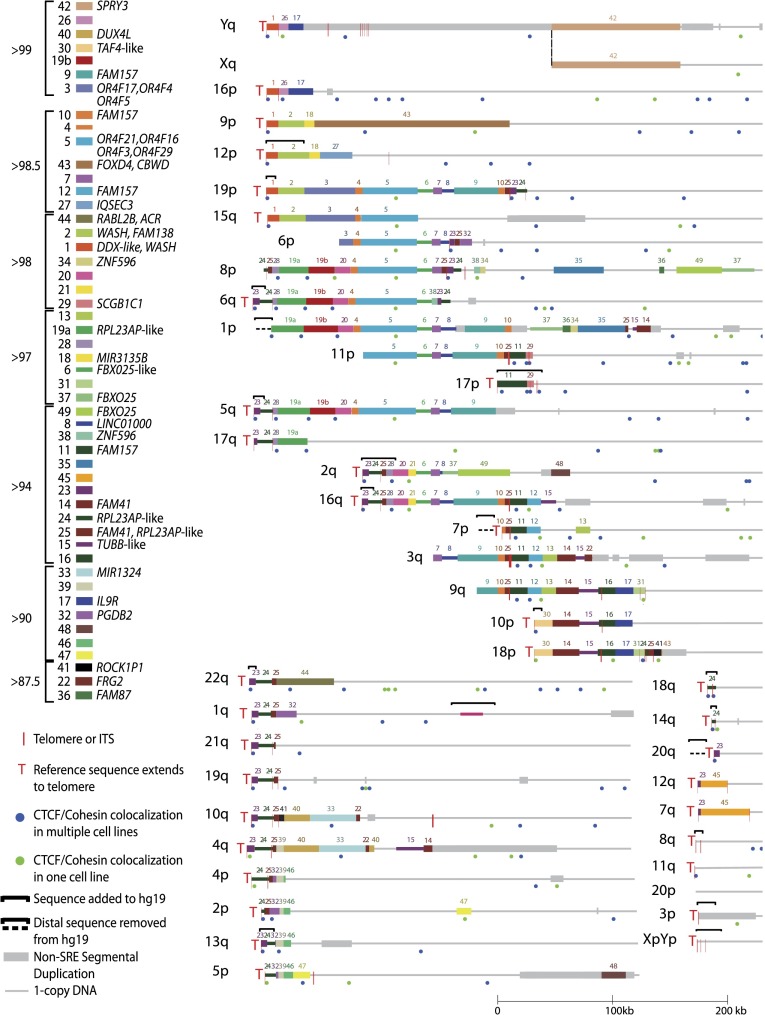
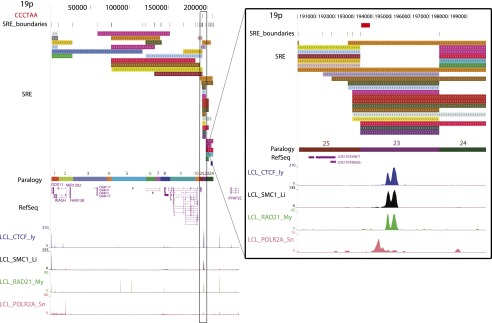
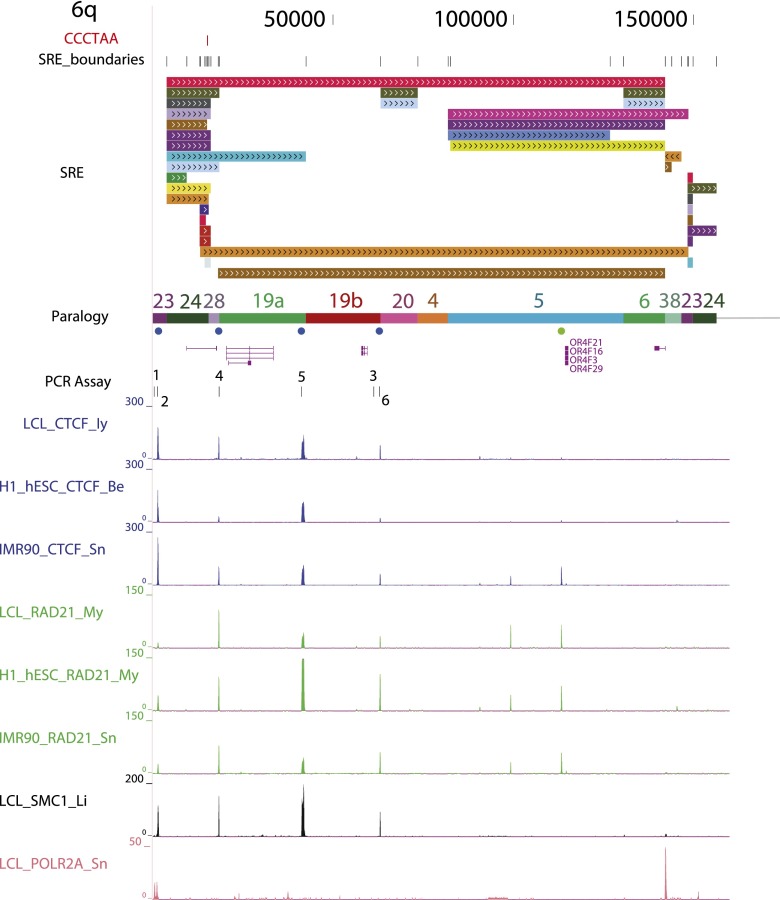
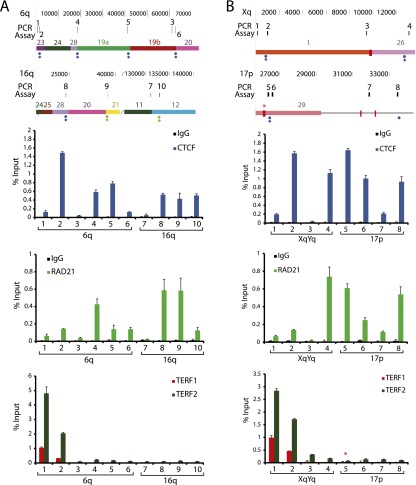
Mapping genome-wide data to human subtelomeres has been problematic due to the incomplete assembly and challenges of low-copy repetitive DNA elements. Here, we provide updated human subtelomere sequence assemblies that were extended by filling telomere-adjacent gaps using clone-based resources. A bioinformatic pipeline incorporating multiread mapping for annotation of the updated assemblies using short-read data sets was developed and implemented. Annotation of subtelomeric sequence features as well as mapping of CTCF and cohesin binding sites using ChIP-seq data sets from multiple human cell types confirmed that CTCF and cohesin bind within 3 kb of the start of terminal repeat tracts at many, but not all, subtelomeres. CTCF and cohesin co-occupancy were also enriched near internal telomere-like sequence (ITS) islands and the nonterminal boundaries of subtelomere repeat elements (SREs) in transformed lymphoblastoid cell lines (LCLs) and human embryonic stem cell (ES) lines, but were not significantly enriched in the primary fibroblast IMR90 cell line. Subtelomeric CTCF and cohesin sites predicted by ChIP-seq using our bioinformatics pipeline (but not predicted when only uniquely mapping reads were considered) were consistently validated by ChIP-qPCR. The colocalized CTCF and cohesin sites in SRE regions are candidates for mediating long-range chromatin interactions in the transcript-rich SRE region. A public browser for the integrated display of short-read sequence-based annotations relative to key subtelomere features such as the start of each terminal repeat tract, SRE identity and organization, and subtelomeric gene models was established.
© 2014 Stong et al.; Published by Cold Spring Harbor Laboratory Press.
Figures
References
-
- Arnoult N, Van Beneden A, Decottignies A 2012. Telomere length regulates TERRA levels through increased trimethylation of telomeric H3K9 and HP1α. Nat Struct Mol Biol 19: 948–956 - PubMed
-
- Azzalin CM, Reichenbach P, Khoriauli L, Giulotto E, Lingner J 2007. Telomeric repeat containing RNA and RNA surveillance factors at mammalian chromosome ends. Science 318: 798–801 - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
- Actions
Grants and funding
- R21 CA143349/CA/NCI NIH HHS/United States
- P30 CA010815/CA/NCI NIH HHS/United States
- R21 HG007205/HG/NHGRI NIH HHS/United States
- P30 CA060553/CA/NCI NIH HHS/United States
- F31 HG006395/HG/NHGRI NIH HHS/United States
- R01CA140652/CA/NCI NIH HHS/United States
- P30 CA10815/CA/NCI NIH HHS/United States
- U54 HG003079/HG/NHGRI NIH HHS/United States
- R01 CA140652/CA/NCI NIH HHS/United States
- P01 HG004120/HG/NHGRI NIH HHS/United States
- R21CA143349/CA/NCI NIH HHS/United States
- R01 LM011297/LM/NLM NIH HHS/United States
- R21HG007205/HG/NHGRI NIH HHS/United States
- R01LM011297/LM/NLM NIH HHS/United States
- HG004120/HG/NHGRI NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases