

"Plateau"-related summary statistics are uninformative for comparing working memory models
- PMID: 24719235
- PMCID: PMC4194187
- DOI: 10.3758/s13414-013-0618-7
"Plateau"-related summary statistics are uninformative for comparing working memory models
Abstract
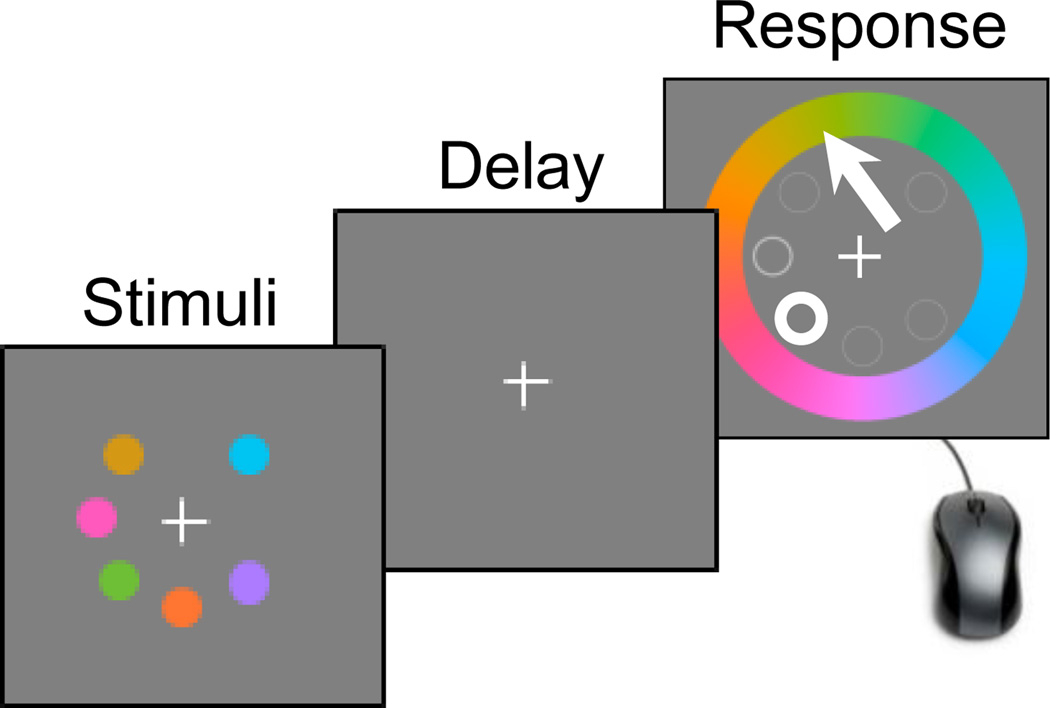
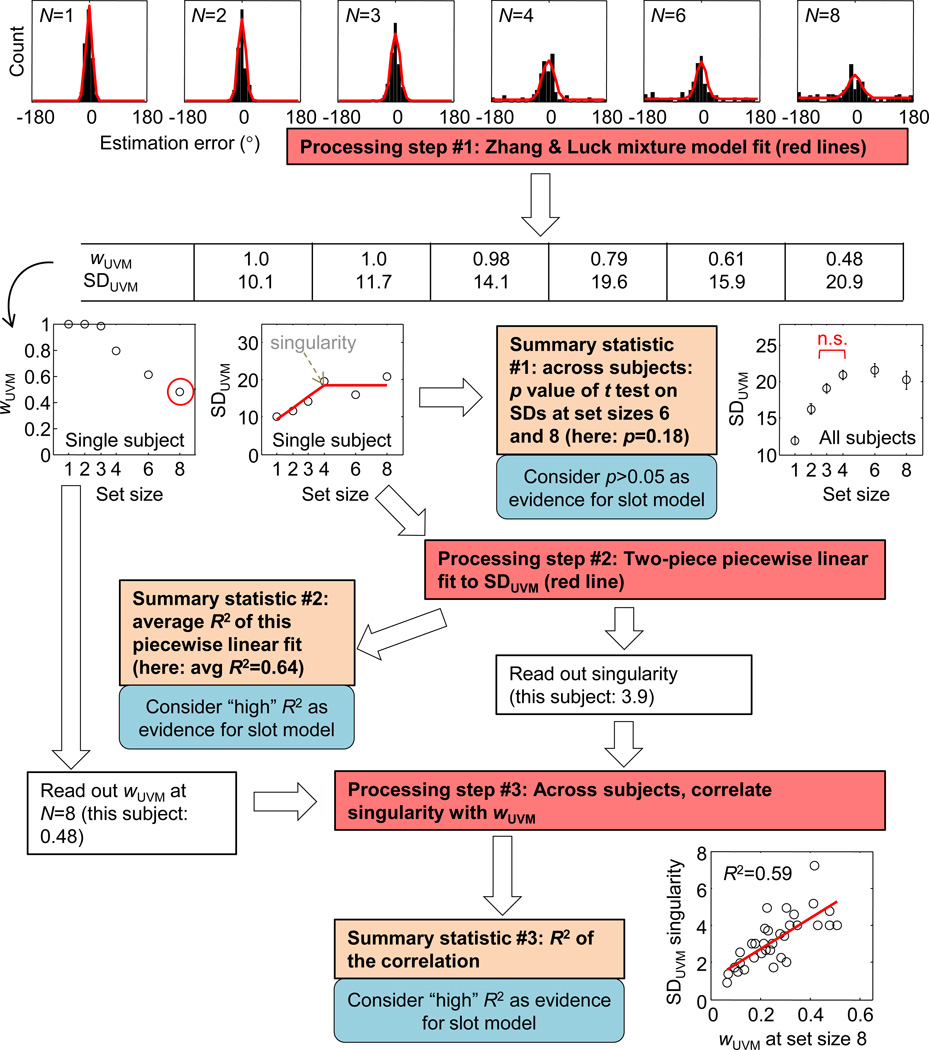
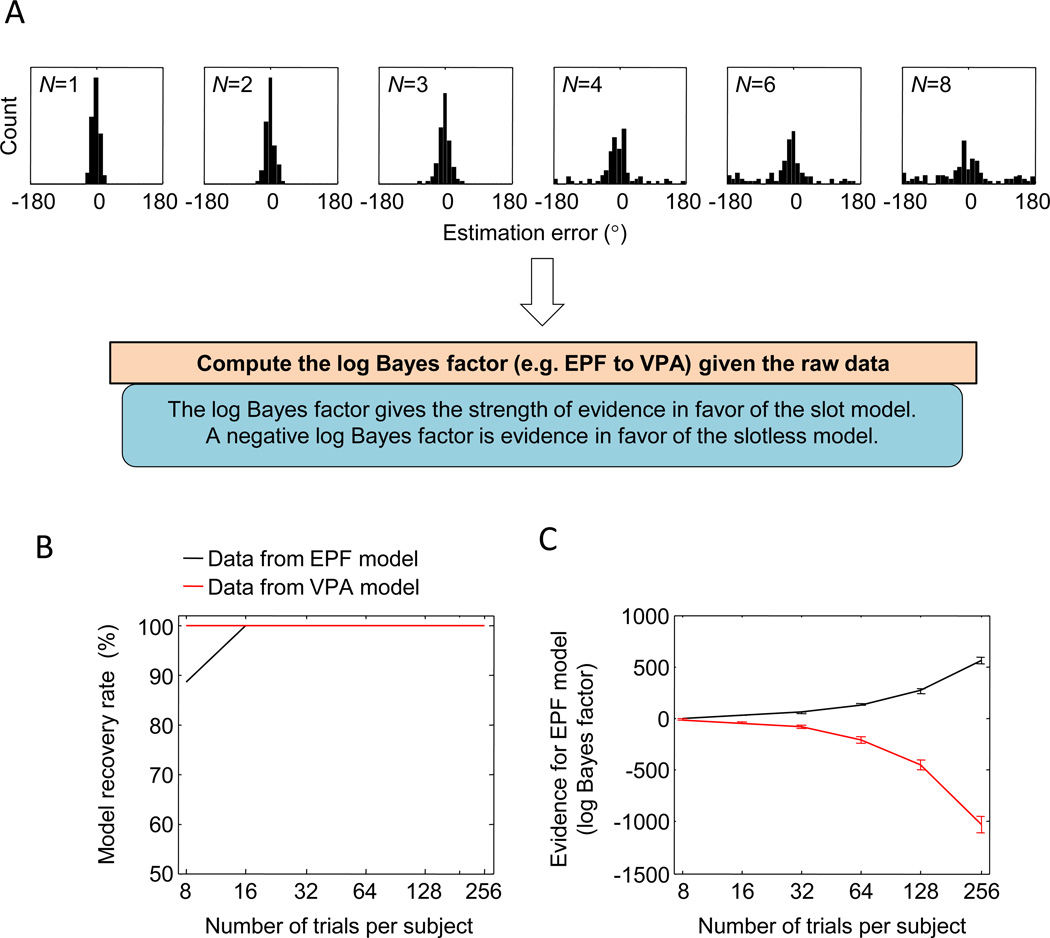
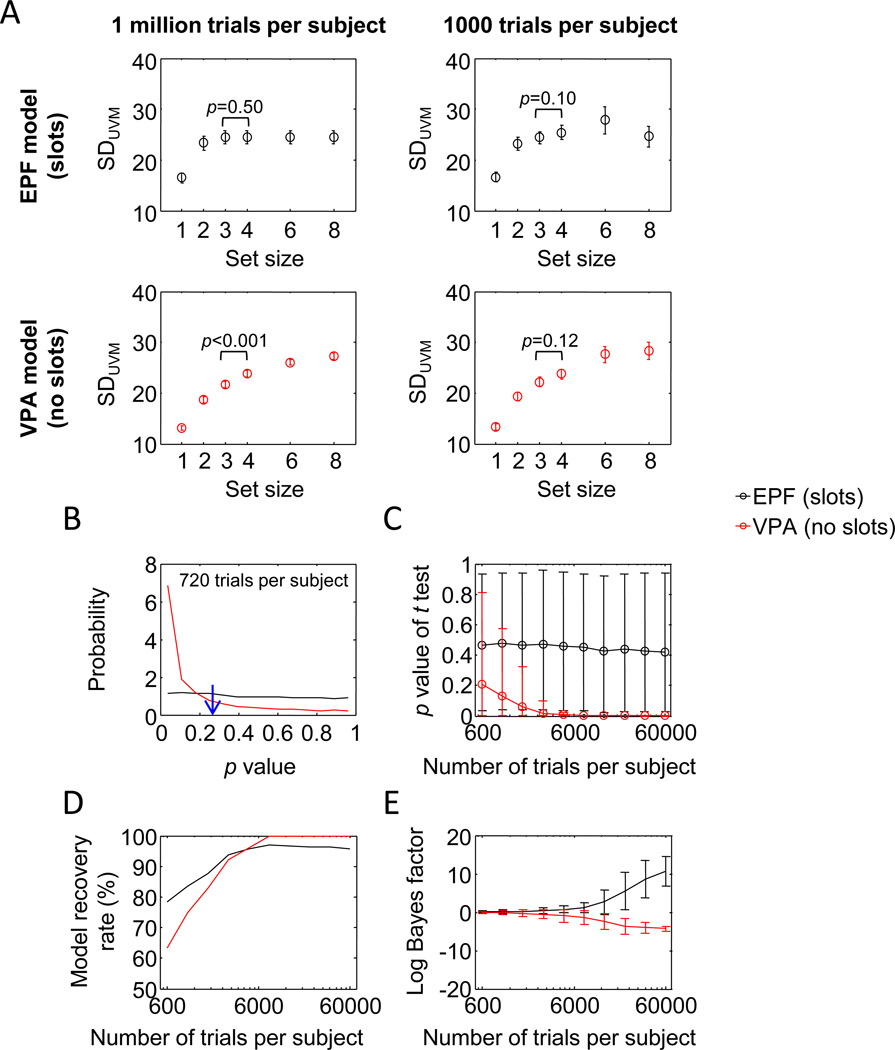
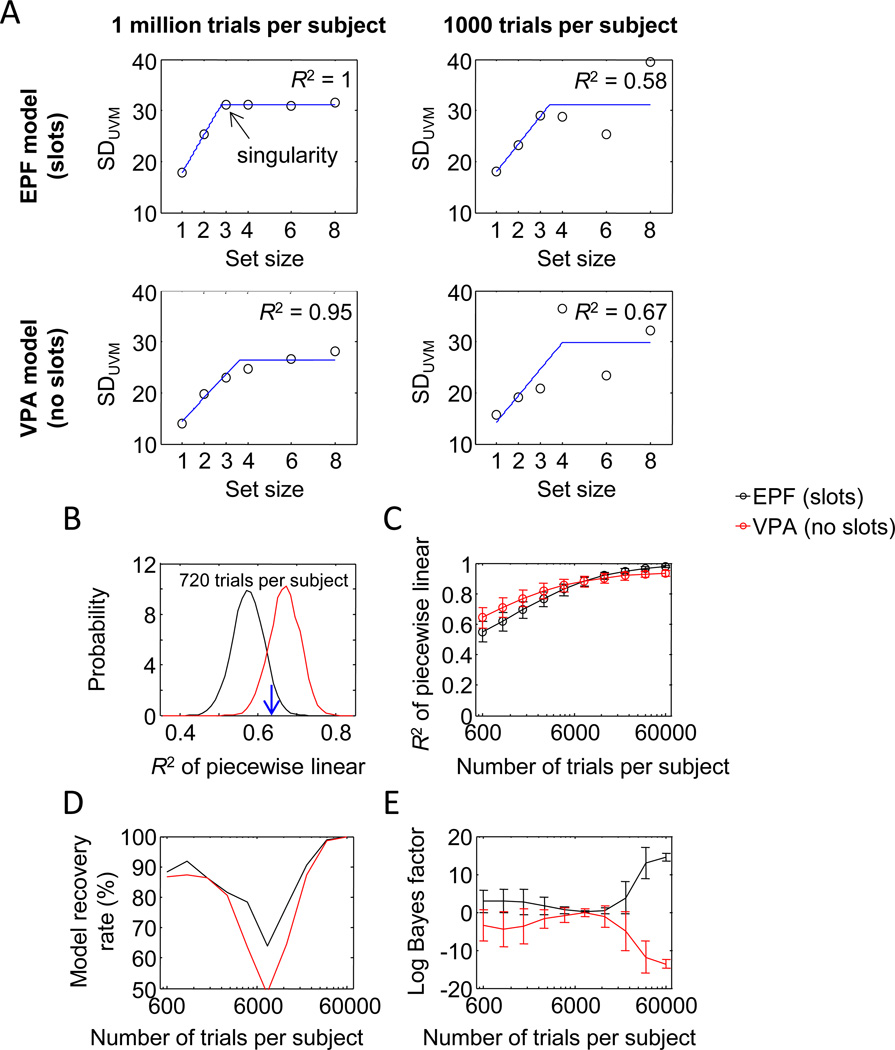
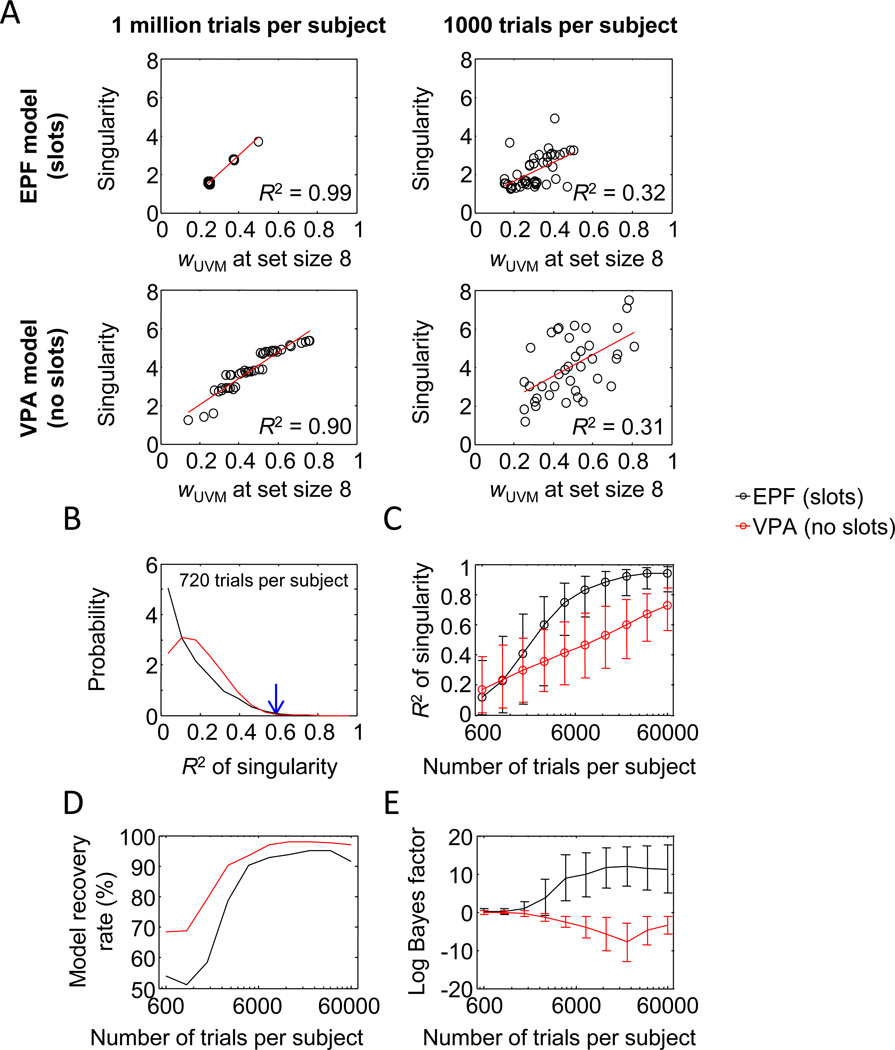
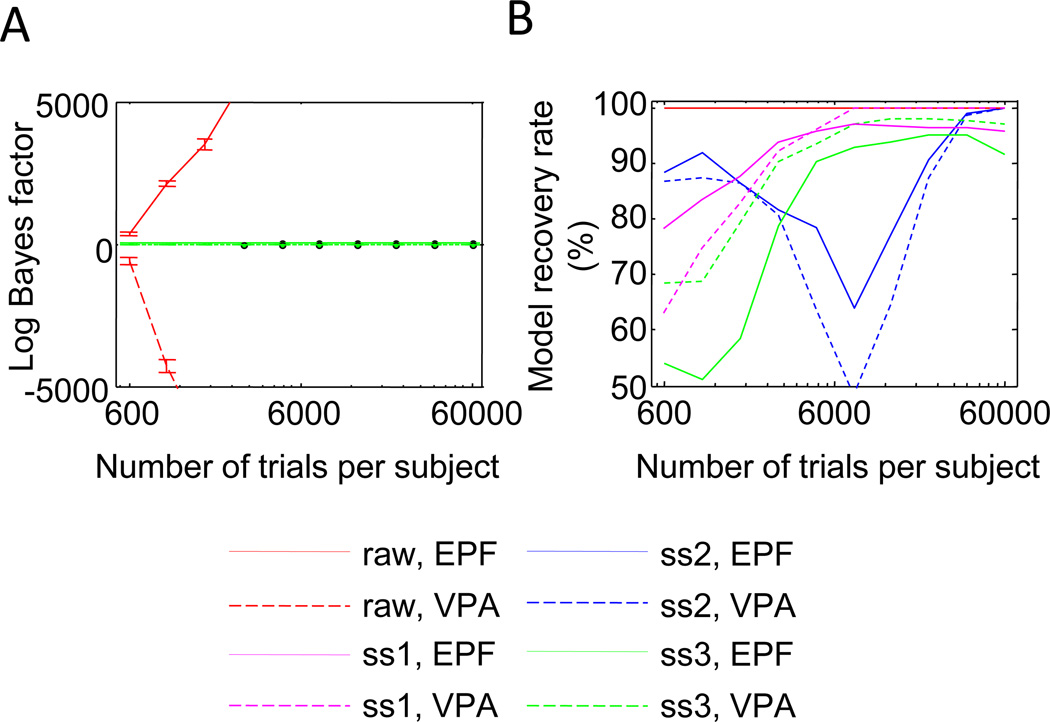
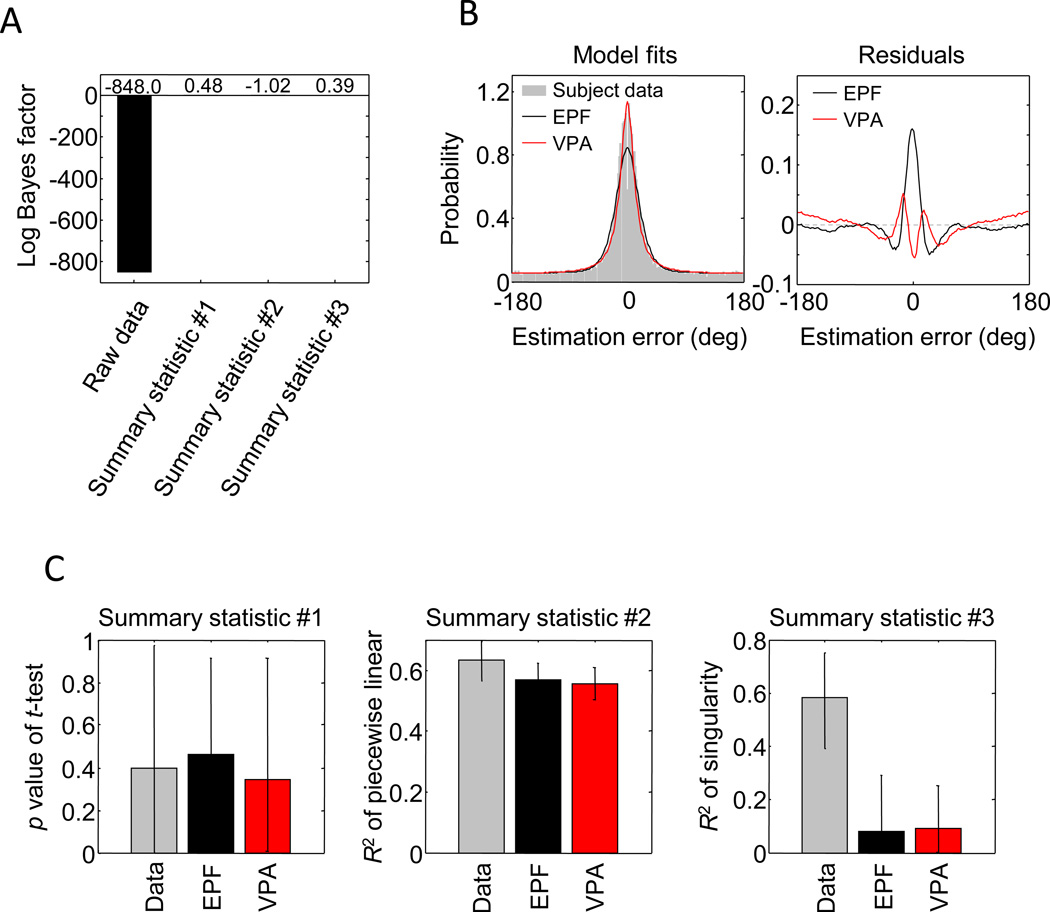
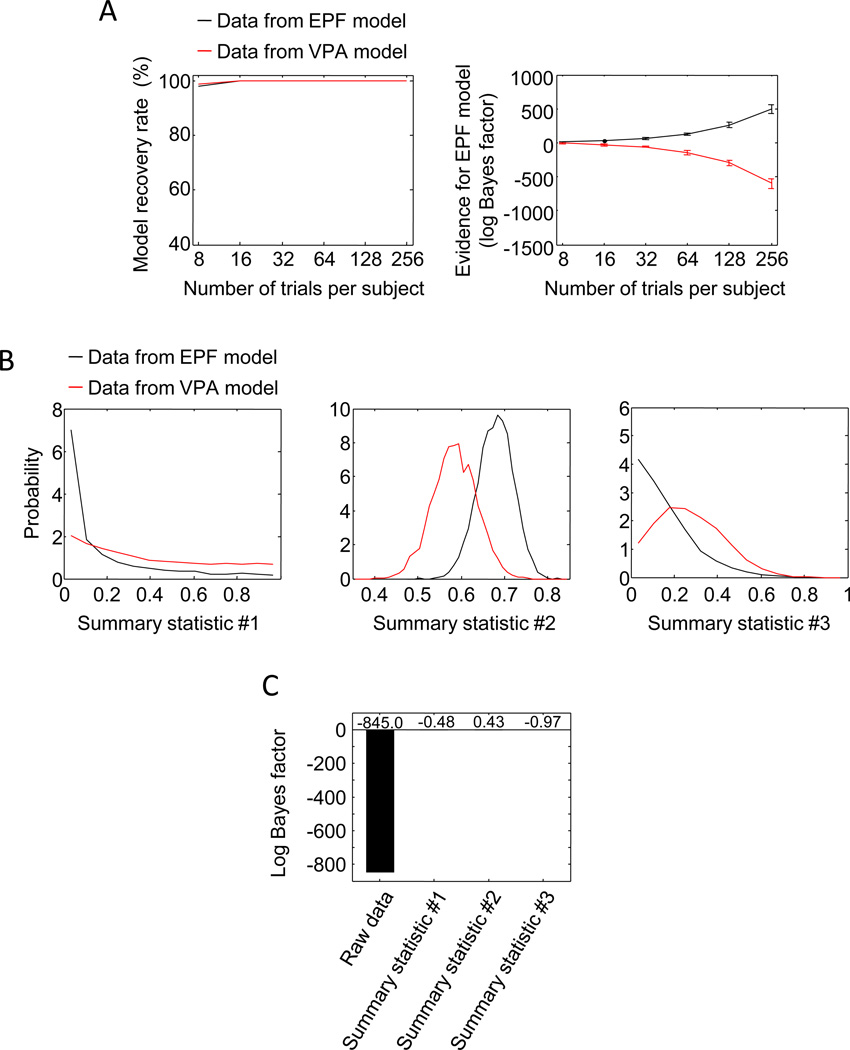
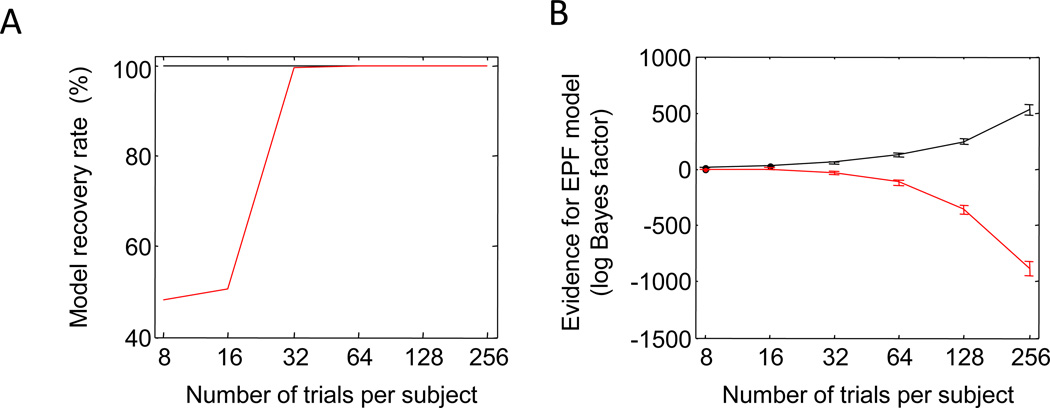
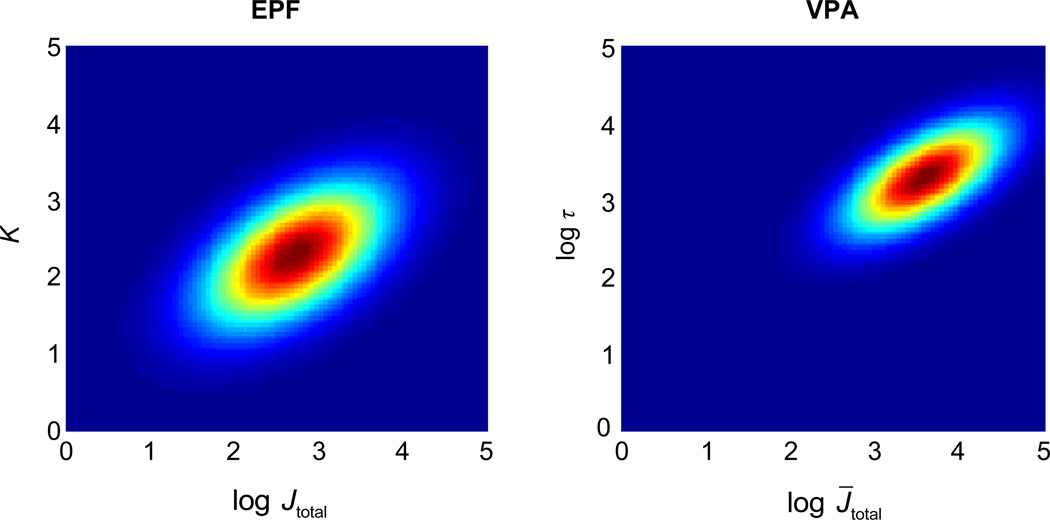
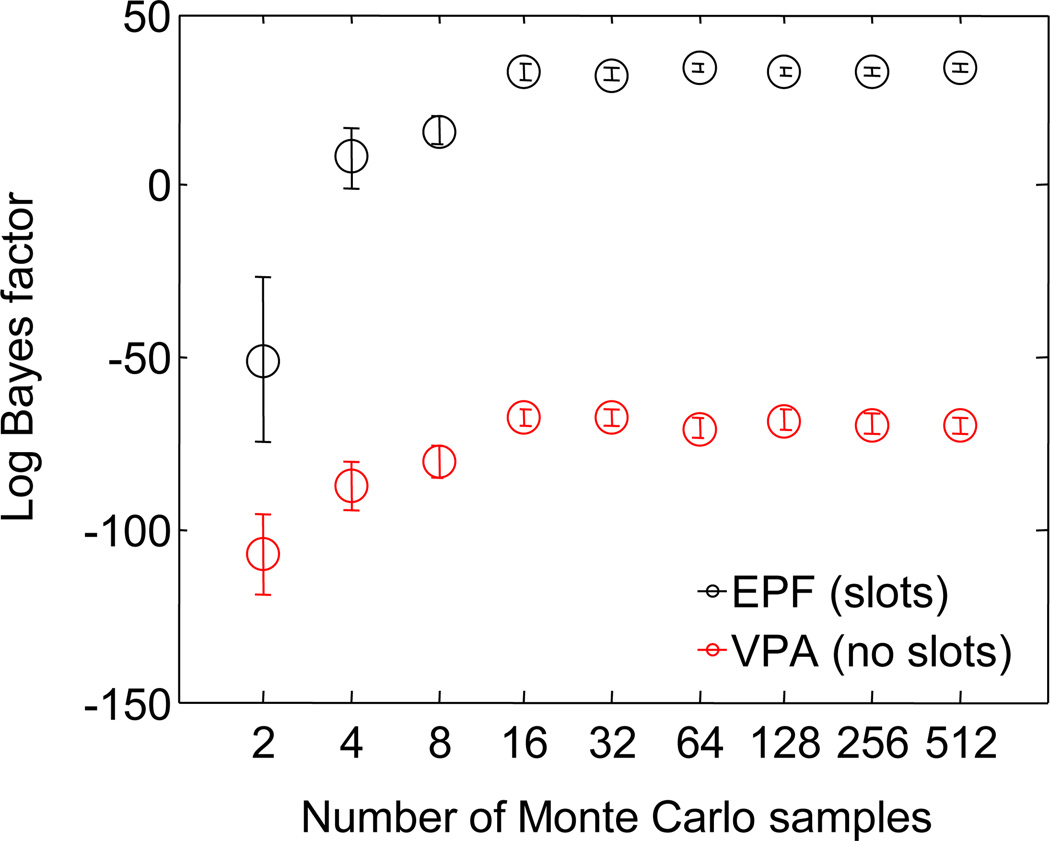
Performance on visual working memory tasks decreases as more items need to be remembered. Over the past decade, a debate has unfolded between proponents of slot models and slotless models of this phenomenon (Ma, Husain, Bays (Nature Neuroscience 17, 347-356, 2014). Zhang and Luck (Nature 453, (7192), 233-235, 2008) and Anderson, Vogel, and Awh (Attention, Perception, Psychophys 74, (5), 891-910, 2011) noticed that as more items need to be remembered, "memory noise" seems to first increase and then reach a "stable plateau." They argued that three summary statistics characterizing this plateau are consistent with slot models, but not with slotless models. Here, we assess the validity of their methods. We generated synthetic data both from a leading slot model and from a recent slotless model and quantified model evidence using log Bayes factors. We found that the summary statistics provided at most 0.15 % of the expected model evidence in the raw data. In a model recovery analysis, a total of more than a million trials were required to achieve 99 % correct recovery when models were compared on the basis of summary statistics, whereas fewer than 1,000 trials were sufficient when raw data were used. Therefore, at realistic numbers of trials, plateau-related summary statistics are highly unreliable for model comparison. Applying the same analyses to subject data from Anderson et al. (Attention, Perception, Psychophys 74, (5), 891-910, 2011), we found that the evidence in the summary statistics was at most 0.12 % of the evidence in the raw data and far too weak to warrant any conclusions. The evidence in the raw data, in fact, strongly favored the slotless model. These findings call into question claims about working memory that are based on summary statistics.
Figures
Similar articles
-
Visual working memory is better characterized as a distributed resource rather than discrete slots.J Vis. 2010 Dec 6;10(14):8. doi: 10.1167/10.14.8. J Vis. 2010. PMID: 21135255
-
Resources masquerading as slots: Flexible allocation of visual working memory.Cogn Psychol. 2016 Mar;85:30-42. doi: 10.1016/j.cogpsych.2016.01.002. Epub 2016 Jan 18. Cogn Psychol. 2016. PMID: 26794368
-
Failure of self-consistency in the discrete resource model of visual working memory.Cogn Psychol. 2018 Sep;105:1-8. doi: 10.1016/j.cogpsych.2018.05.002. Epub 2018 Jun 3. Cogn Psychol. 2018. PMID: 29874628 Free PMC article.
-
Toward ecologically realistic theories in visual short-term memory research.Atten Percept Psychophys. 2014 Oct;76(7):2158-70. doi: 10.3758/s13414-014-0649-8. Atten Percept Psychophys. 2014. PMID: 24658920 Review.
-
Different states in visual working memory: when it guides attention and when it does not.Trends Cogn Sci. 2011 Jul;15(7):327-34. doi: 10.1016/j.tics.2011.05.004. Epub 2011 Jun 12. Trends Cogn Sci. 2011. PMID: 21665518 Review.
Cited by
-
Systematic differences in visual working memory performance are not caused by differences in working memory storage.J Exp Psychol Learn Mem Cogn. 2023 Mar;49(3):335-349. doi: 10.1037/xlm0001202. Epub 2023 Feb 2. J Exp Psychol Learn Mem Cogn. 2023. PMID: 36729486 Free PMC article.
-
Monkeys and humans take local uncertainty into account when localizing a change.J Vis. 2017 Sep 1;17(11):4. doi: 10.1167/17.11.4. J Vis. 2017. PMID: 28877535 Free PMC article.
-
Introduction to the special issue on visual working memory.Atten Percept Psychophys. 2014 Oct;76(7):1861-70. doi: 10.3758/s13414-014-0783-3. Atten Percept Psychophys. 2014. PMID: 25341647 Free PMC article.
-
Competitive interactions affect working memory performance for both simultaneous and sequential stimulus presentation.Sci Rep. 2017 Jul 6;7(1):4785. doi: 10.1038/s41598-017-05011-x. Sci Rep. 2017. PMID: 28684800 Free PMC article.
-
The representational consequences of intentional forgetting: Impairments to both the probability and fidelity of long-term memory.J Exp Psychol Gen. 2016 Jan;145(1):56-81. doi: 10.1037/xge0000128. J Exp Psychol Gen. 2016. PMID: 26709589 Free PMC article.
References
-
- Akaike H. A new look at the statistical model identification. IEEE Transactions on Automatic Control. 1974;19(6):716–723.
-
- Alvarez GA, Cavanagh P. The capacity of visual short-term memory is set both by visual information load and by number of objects. Psych Science. 2004;15:106–111. - PubMed
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
