

Compressive mapping of number to space reflects dynamic encoding mechanisms, not static logarithmic transform
- PMID: 24821771
- PMCID: PMC4040572
- DOI: 10.1073/pnas.1402785111
Compressive mapping of number to space reflects dynamic encoding mechanisms, not static logarithmic transform
Abstract
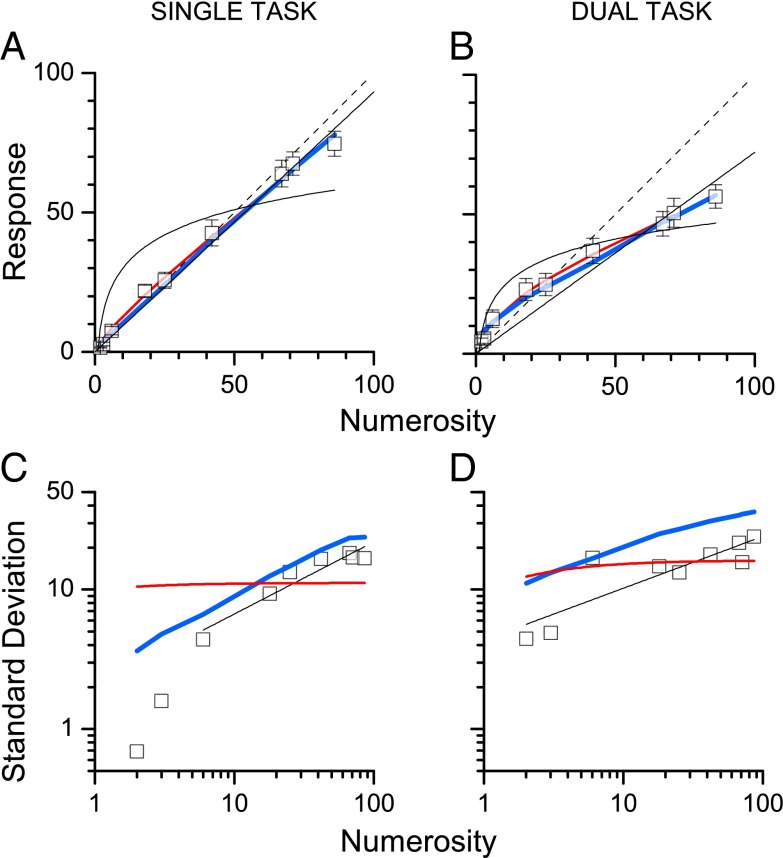
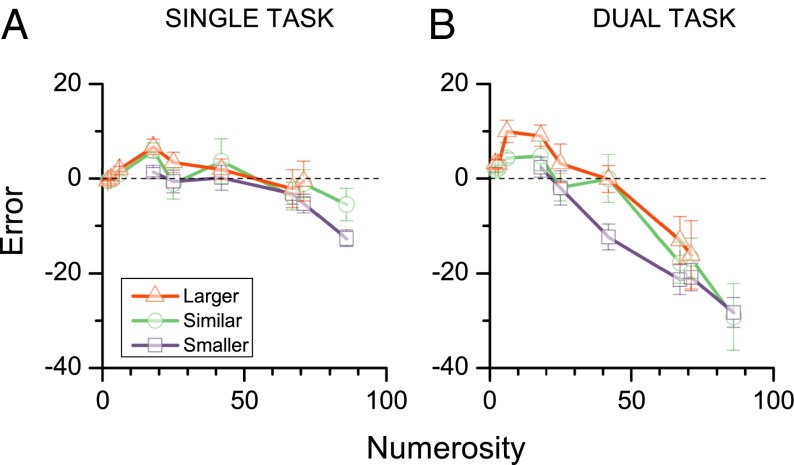
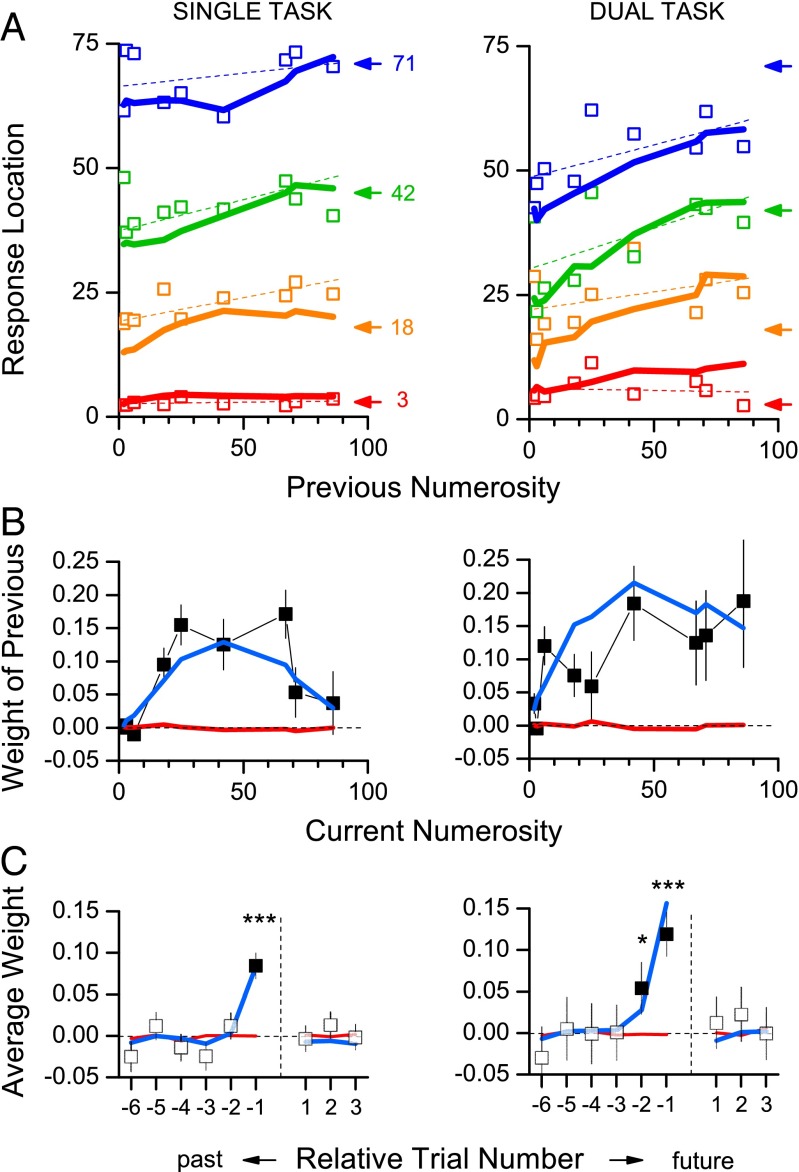
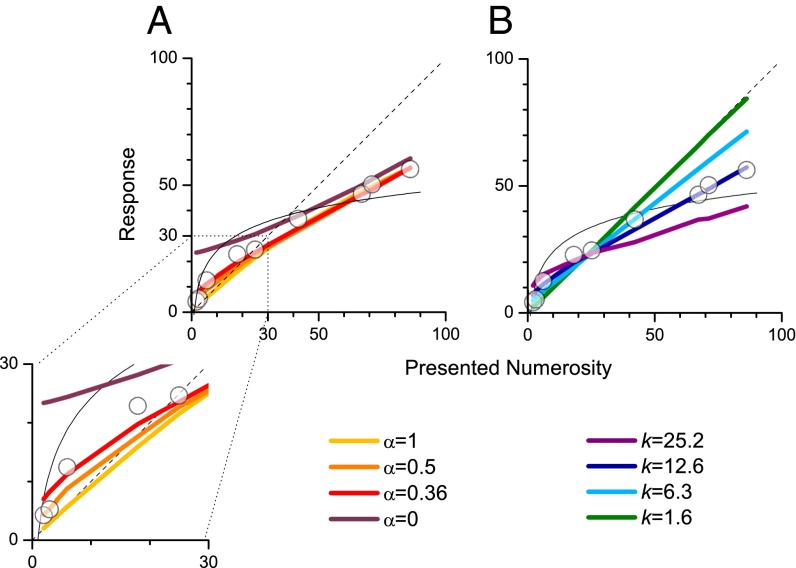
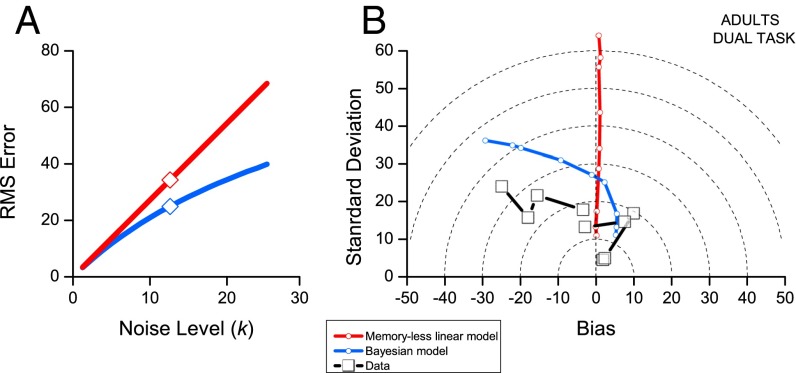
The mapping of number onto space is fundamental to measurement and mathematics. However, the mapping of young children, unschooled adults, and adults under attentional load shows strong compressive nonlinearities, thought to reflect intrinsic logarithmic encoding mechanisms, which are later "linearized" by education. Here we advance and test an alternative explanation: that the nonlinearity results from adaptive mechanisms incorporating the statistics of recent stimuli. This theory predicts that the response to the current trial should depend on the magnitude of the previous trial, whereas a static logarithmic nonlinearity predicts trialwise independence. We found a strong and highly significant relationship between numberline mapping of the current trial and the magnitude of the previous trial, in both adults and school children, with the current response influenced by up to 15% of the previous trial value. The dependency is sufficient to account for the shape of the numberline, without requiring logarithmic transform. We show that this dynamic strategy results in a reduction of reproduction error, and hence improvement in accuracy.
Keywords: Weber–Fechner law; approximate number system; numerical cognition; predictive coding; serial dependency.
Conflict of interest statement
The authors declare no conflict of interest.
Figures
References
-
- Galton F. Visualized numerals. Nature. 1880;21:252–256. 494-255.
-
- Dehaene S. The Number Sense: How the Mind Creates Mathematics. Oxford: Oxford Univ Press; 1997.
-
- Siegler RS, Booth JL. Development of numerical estimation in young children. Child Dev. 2004;75(2):428–444. - PubMed
-
- Siegler RS, Opfer JE. The development of numerical estimation: Evidence for multiple representations of numerical quantity. Psychol Sci. 2003;14(3):237–243. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
