

Predicting the fungal CUG codon translation with Bagheera
- PMID: 24885275
- PMCID: PMC4050208
- DOI: 10.1186/1471-2164-15-411
Predicting the fungal CUG codon translation with Bagheera
Abstract
Background: Many eukaryotes have been shown to use alternative schemes to the universal genetic code. While most Saccharomycetes, including Saccharomyces cerevisiae, use the standard genetic code translating the CUG codon as leucine, some yeasts, including many but not all of the "Candida", translate the same codon as serine. It has been proposed that the change in codon identity was accomplished by an almost complete loss of the original CUG codons, making the CUG positions within the extant species highly discriminative for the one or other translation scheme.
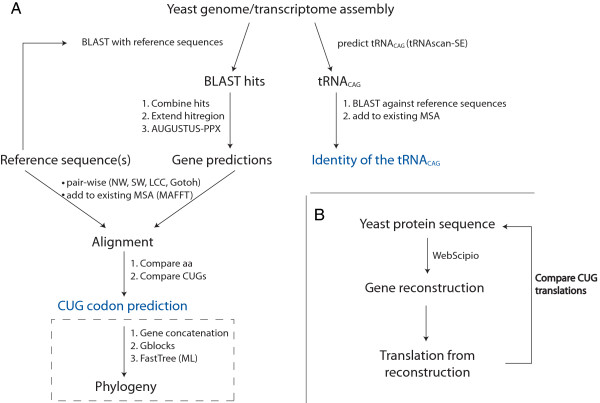
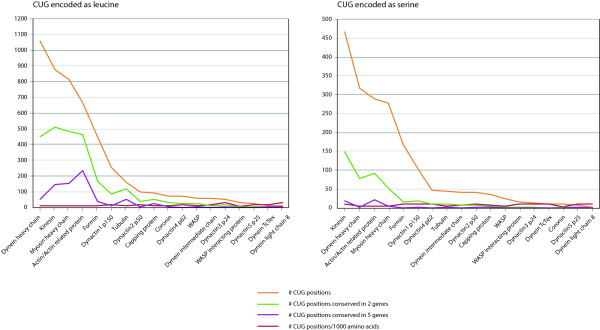
Results: In order to improve the prediction of genes in yeast species by providing the correct CUG decoding scheme we implemented a web server, called Bagheera, that allows determining the most probable CUG codon translation for a given transcriptome or genome assembly based on extensive reference data. As reference data we use 2071 manually assembled and annotated sequences from 38 cytoskeletal and motor proteins belonging to 79 yeast species. The web service includes a pipeline, which starts with predicting and aligning homologous genes to the reference data. CUG codon positions within the predicted genes are analysed with respect to amino acid similarity and CUG codon conservation in related species. In addition, the tRNACAG gene is predicted in genomic data and compared to known leu-tRNACAG and ser-tRNACAG genes. Bagheera can also be used to evaluate any mRNA and protein sequence data with the codon usage of the respective species. The usage of the system has been demonstrated by analysing six genomes not included in the reference data.
Conclusions: Gene prediction and consecutive comparison with reference data from other Saccharomycetes are sufficient to predict the most probable decoding scheme for CUG codons. This approach has been implemented into Bagheera (http://www.motorprotein.de/bagheera).
Figures

Similar articles
-
Molecular phylogeny of sequenced Saccharomycetes reveals polyphyly of the alternative yeast codon usage.Genome Biol Evol. 2014 Jul 22;6(12):3222-37. doi: 10.1093/gbe/evu152. Genome Biol Evol. 2014. PMID: 25646540 Free PMC article.
-
Non-universal decoding of the leucine codon CUG in several Candida species.Nucleic Acids Res. 1993 Aug 25;21(17):4039-45. doi: 10.1093/nar/21.17.4039. Nucleic Acids Res. 1993. PMID: 8371978 Free PMC article.
-
Characterization of serine and leucine tRNAs in an asporogenic yeast Candida cylindracea and evolutionary implications of genes for tRNA(Ser)CAG responsible for translation of a non-universal genetic code.Nucleic Acids Res. 1994 Jan 25;22(2):115-23. doi: 10.1093/nar/22.2.115. Nucleic Acids Res. 1994. PMID: 8121794 Free PMC article.
-
The non-standard genetic code of Candida spp.: an evolving genetic code or a novel mechanism for adaptation?Mol Microbiol. 1997 Nov;26(3):423-31. doi: 10.1046/j.1365-2958.1997.5891961.x. Mol Microbiol. 1997. PMID: 9402014 Review.
-
Codon reassignment in Candida species: an evolutionary conundrum.Biochimie. 1996;78(11-12):993-9. doi: 10.1016/s0300-9084(97)86722-3. Biochimie. 1996. PMID: 9150877 Review.
Cited by
-
Genomic and transcriptomic analysis of Candida intermedia reveals the genetic determinants for its xylose-converting capacity.Biotechnol Biofuels. 2020 Mar 12;13:48. doi: 10.1186/s13068-020-1663-9. eCollection 2020. Biotechnol Biofuels. 2020. PMID: 32190113 Free PMC article.
-
Endogenous Stochastic Decoding of the CUG Codon by Competing Ser- and Leu-tRNAs in Ascoidea asiatica.Curr Biol. 2018 Jul 9;28(13):2046-2057.e5. doi: 10.1016/j.cub.2018.04.085. Epub 2018 Jun 18. Curr Biol. 2018. PMID: 29910077 Free PMC article.
-
A computational screen for alternative genetic codes in over 250,000 genomes.Elife. 2021 Nov 9;10:e71402. doi: 10.7554/eLife.71402. Elife. 2021. PMID: 34751130 Free PMC article.
-
Rapid Genetic Code Evolution in Green Algal Mitochondrial Genomes.Mol Biol Evol. 2019 Apr 1;36(4):766-783. doi: 10.1093/molbev/msz016. Mol Biol Evol. 2019. PMID: 30698742 Free PMC article.
-
Genetic basis of priority effects: insights from nectar yeast.Proc Biol Sci. 2016 Oct 12;283(1840):20161455. doi: 10.1098/rspb.2016.1455. Proc Biol Sci. 2016. PMID: 27708148 Free PMC article.
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
