

Identification of bacteriophage-encoded anti-sRNAs in pathogenic Escherichia coli
- PMID: 24910100
- PMCID: PMC4104026
- DOI: 10.1016/j.molcel.2014.05.006
Identification of bacteriophage-encoded anti-sRNAs in pathogenic Escherichia coli
Abstract
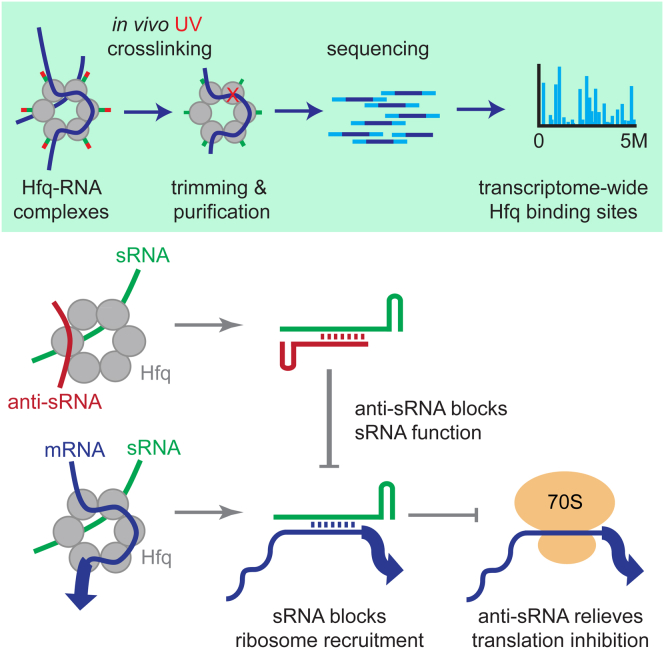
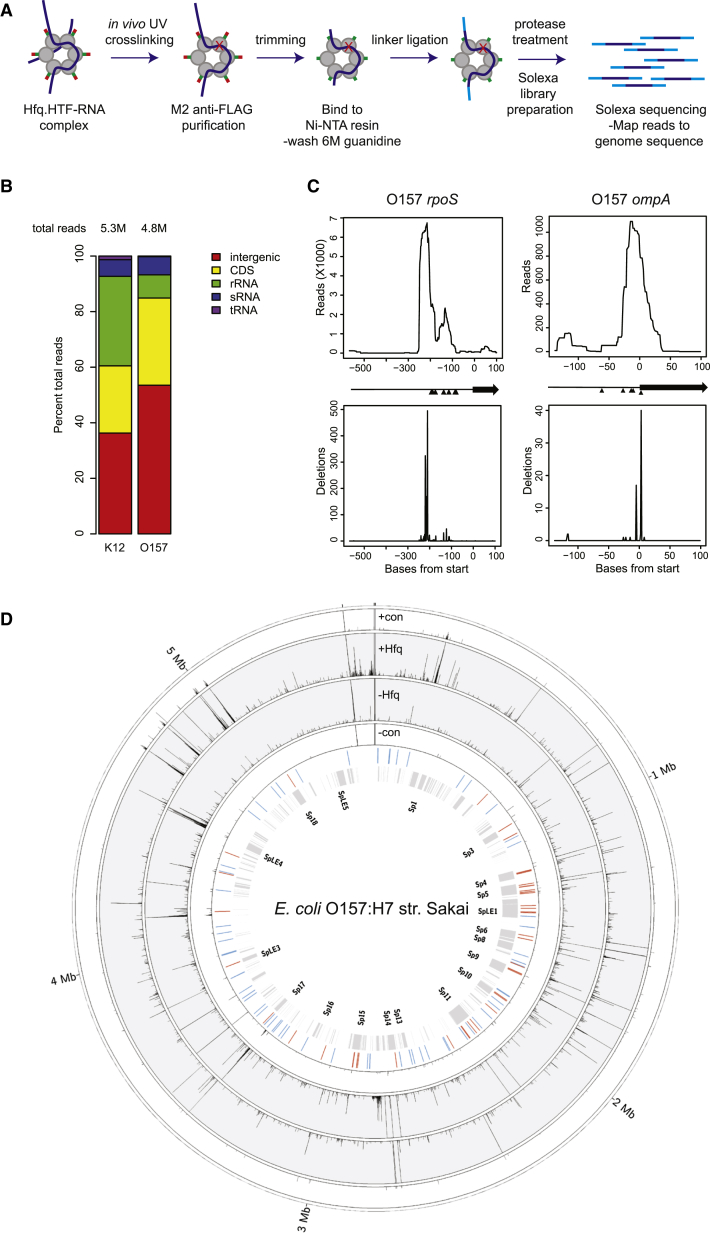
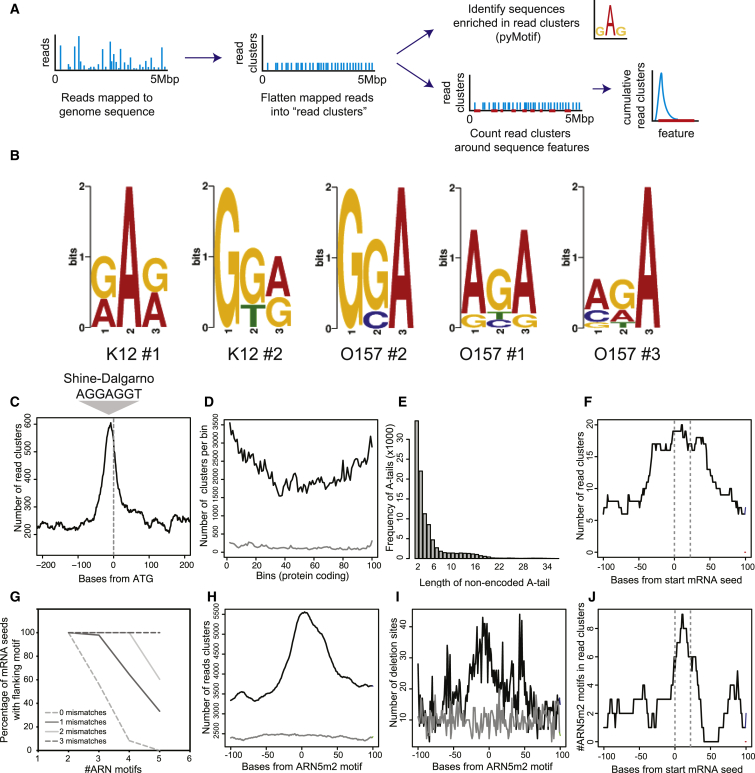
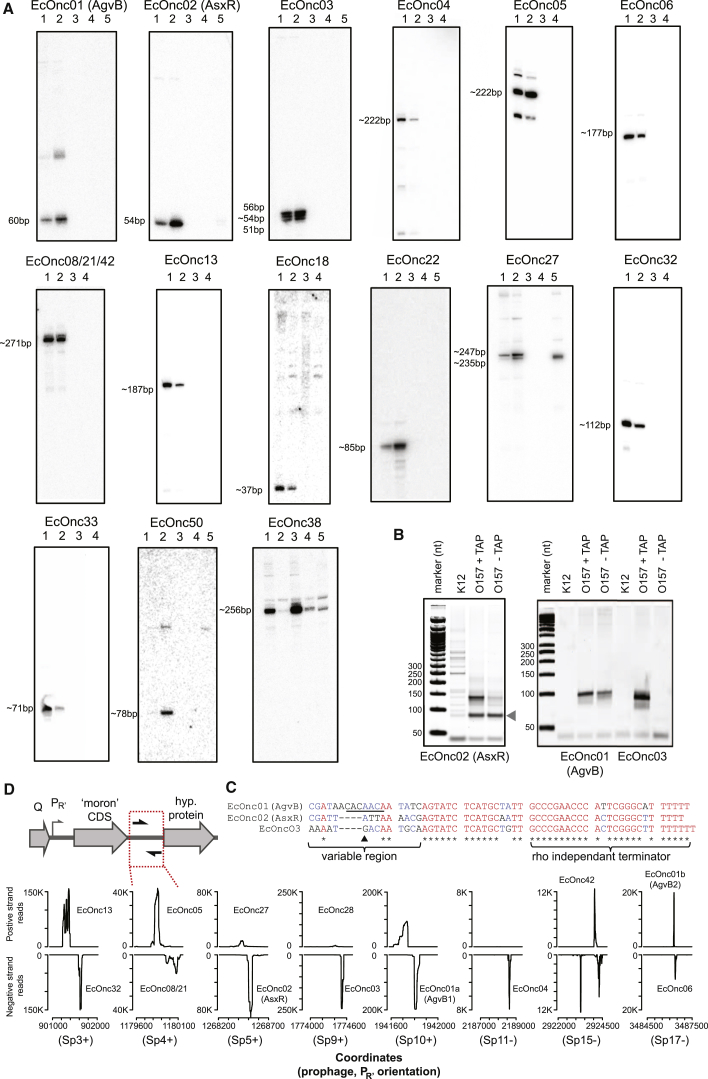
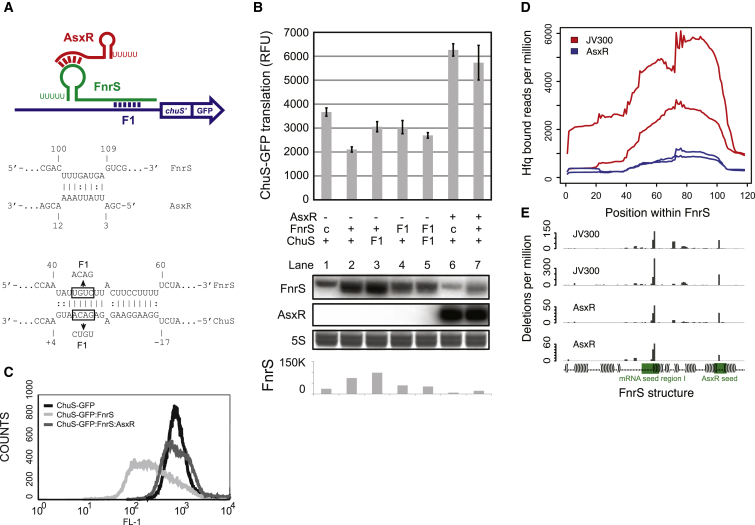
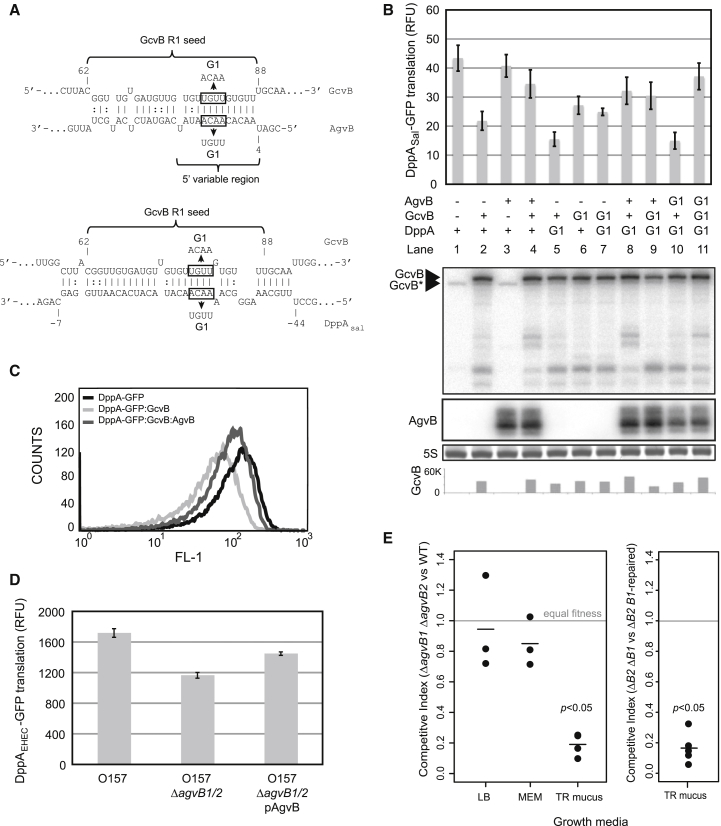
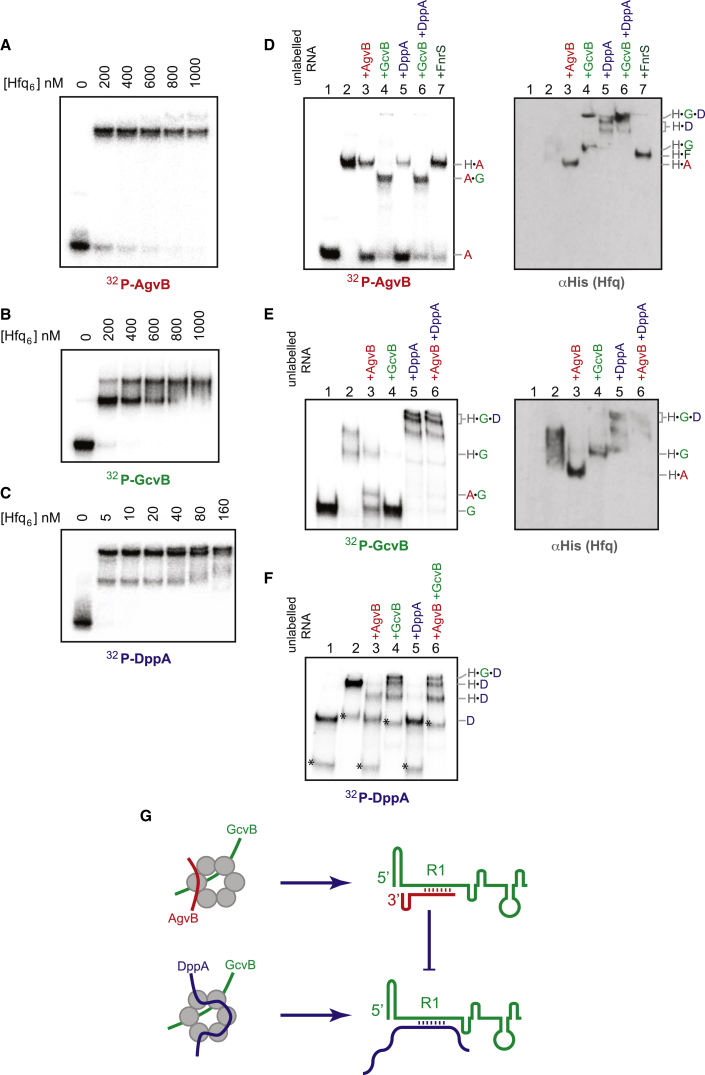
In bacteria, Hfq is a core RNA chaperone that catalyzes the interaction of mRNAs with regulatory small RNAs (sRNAs). To determine in vivo RNA sequence requirements for Hfq interactions, and to study riboregulation in a bacterial pathogen, Hfq was UV crosslinked to RNAs in enterohemorrhagic Escherichia coli (EHEC). Hfq bound repeated trinucleotide motifs of A-R-N (A-A/G-any nucleotide) often associated with the Shine-Dalgarno translation initiation sequence in mRNAs. These motifs overlapped or were adjacent to the mRNA sequences bound by sRNAs. In consequence, sRNA-mRNA duplex formation will displace Hfq, promoting recycling. Fifty-five sRNAs were identified within bacteriophage-derived regions of the EHEC genome, including some of the most abundant Hfq-interacting sRNAs. One of these (AgvB) antagonized the function of the core genome regulatory sRNA, GcvB, by mimicking its mRNA substrate sequence. This bacteriophage-encoded "anti-sRNA" provided EHEC with a growth advantage specifically in bovine rectal mucus recovered from its primary colonization site in cattle.
Copyright © 2014 The Authors. Published by Elsevier Inc. All rights reserved.
Figures

References
-
- Blum E., Carpousis A.J., Higgins C.F. Polyadenylation promotes degradation of 3′-structured RNA by the Escherichia coli mRNA degradosome in vitro. J. Biol. Chem. 1999;274:4009–4016. - PubMed
-
- Bouvier M., Sharma C.M., Mika F., Nierhaus K.H., Vogel J. Small RNA binding to 5′ mRNA coding region inhibits translational initiation. Mol. Cell. 2008;32:827–837. - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Molecular Biology Databases
