

Altering spatial priority maps via reward-based learning
- PMID: 24948813
- PMCID: PMC6608215
- DOI: 10.1523/JNEUROSCI.0277-14.2014
Altering spatial priority maps via reward-based learning
Abstract
Spatial priority maps are real-time representations of the behavioral salience of locations in the visual field, resulting from the combined influence of stimulus driven activity and top-down signals related to the current goals of the individual. They arbitrate which of a number of (potential) targets in the visual scene will win the competition for attentional resources. As a result, deployment of visual attention to a specific spatial location is determined by the current peak of activation (corresponding to the highest behavioral salience) across the map. Here we report a behavioral study performed on healthy human volunteers, where we demonstrate that spatial priority maps can be shaped via reward-based learning, reflecting long-lasting alterations (biases) in the behavioral salience of specific spatial locations. These biases exert an especially strong influence on performance under conditions where multiple potential targets compete for selection, conferring competitive advantage to targets presented in spatial locations associated with greater reward during learning relative to targets presented in locations associated with lesser reward. Such acquired biases of spatial attention are persistent, are nonstrategic in nature, and generalize across stimuli and task contexts. These results suggest that reward-based attentional learning can induce plastic changes in spatial priority maps, endowing these representations with the "intelligent" capacity to learn from experience.
Keywords: cross-target competition; reward-based learning; spatial attention; spatial priority maps.
Copyright © 2014 the authors 0270-6474/14/348594-11$15.00/0.
Figures
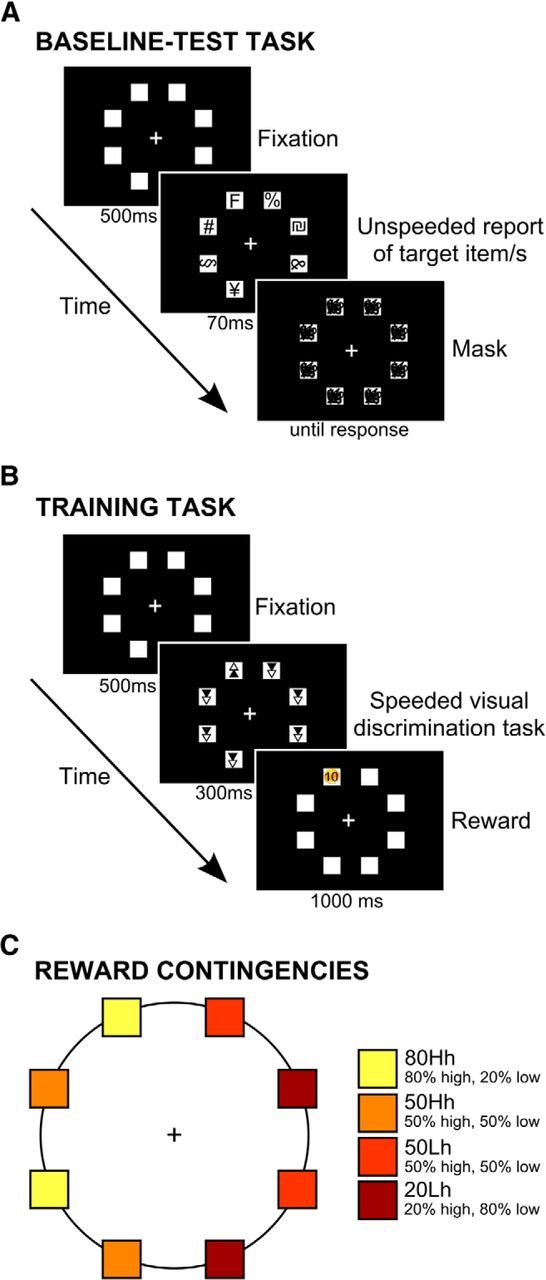
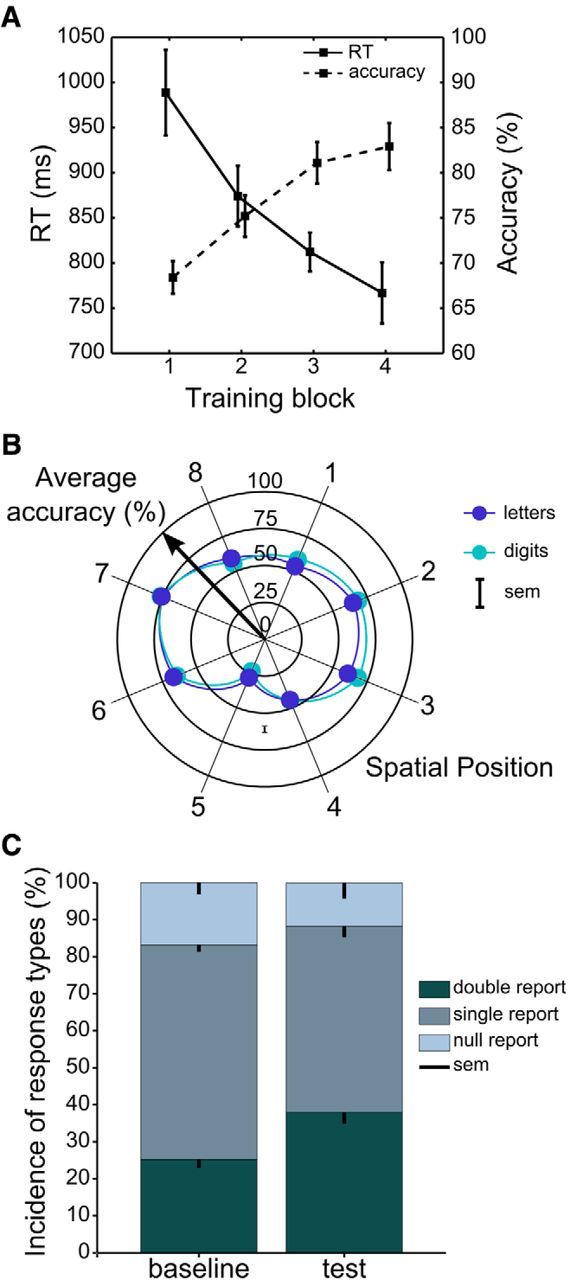
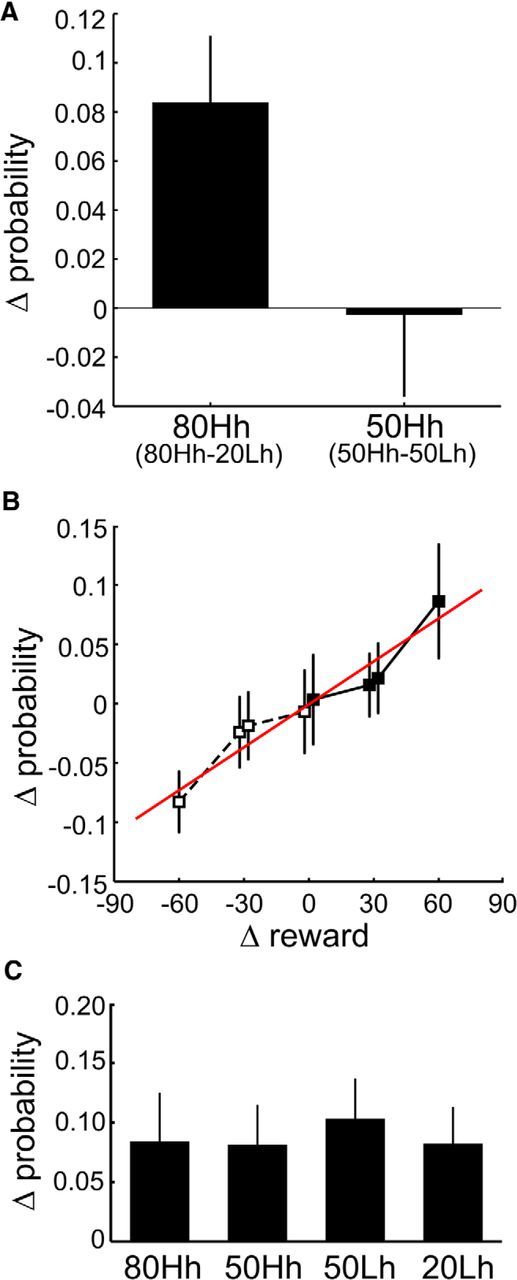
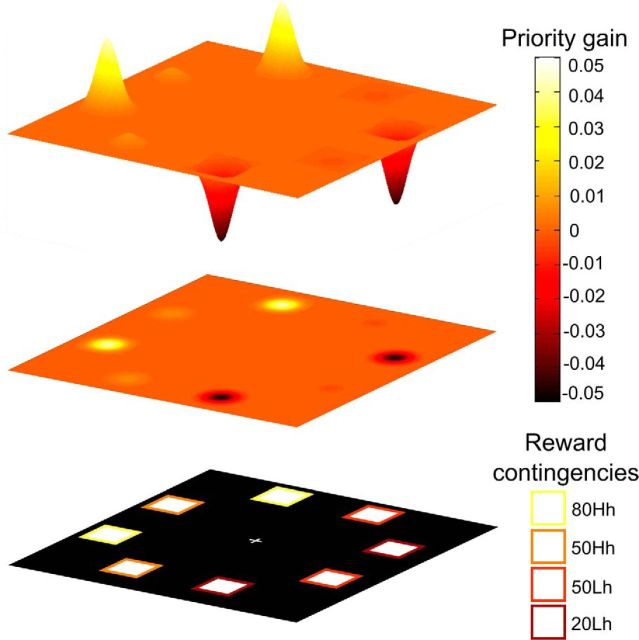
Comment in
-
Priority maps explain the roles of value, attention, and salience in goal-oriented behavior.J Neurosci. 2014 Oct 15;34(42):13867-9. doi: 10.1523/JNEUROSCI.3249-14.2014. J Neurosci. 2014. PMID: 25319682 Free PMC article. No abstract available.
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
Miscellaneous