

e!DAL--a framework to store, share and publish research data
- PMID: 24958009
- PMCID: PMC4080583
- DOI: 10.1186/1471-2105-15-214
e!DAL--a framework to store, share and publish research data
Abstract
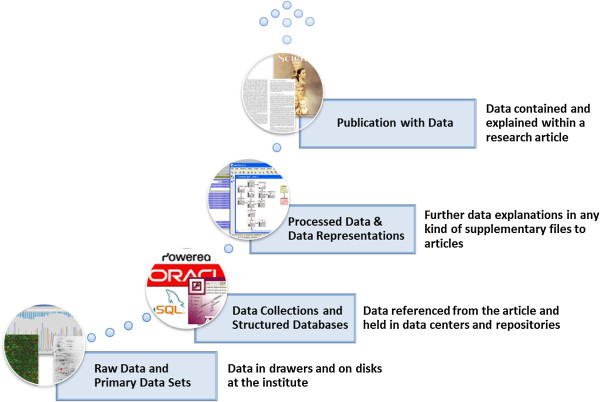
Background: The life-science community faces a major challenge in handling "big data", highlighting the need for high quality infrastructures capable of sharing and publishing research data. Data preservation, analysis, and publication are the three pillars in the "big data life cycle". The infrastructures currently available for managing and publishing data are often designed to meet domain-specific or project-specific requirements, resulting in the repeated development of proprietary solutions and lower quality data publication and preservation overall.
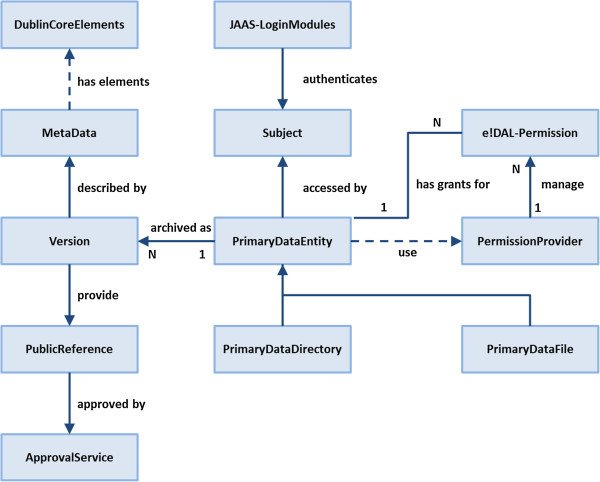
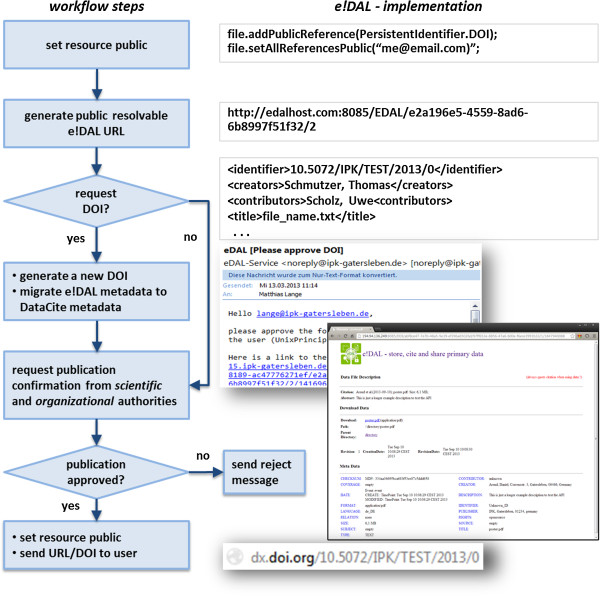
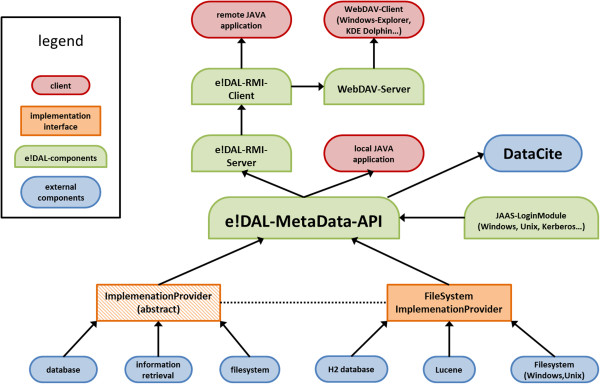
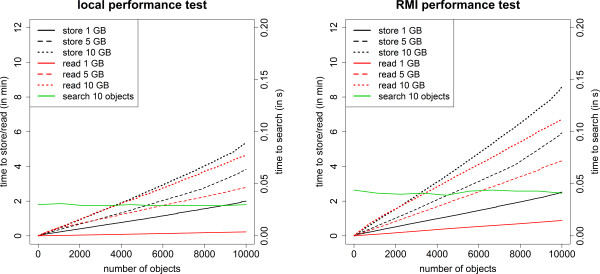
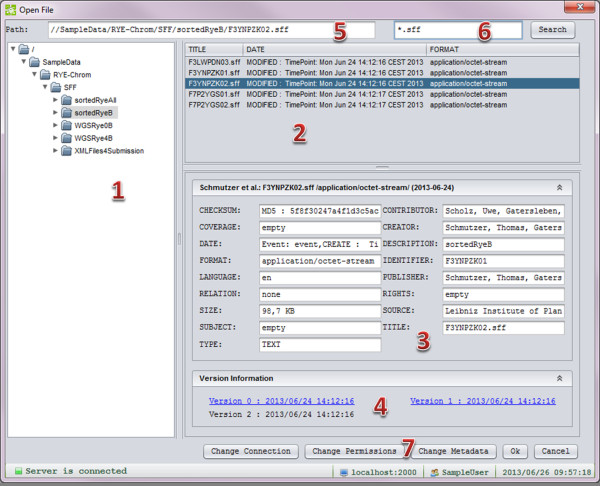
Results: e!DAL is a lightweight software framework for publishing and sharing research data. Its main features are version tracking, metadata management, information retrieval, registration of persistent identifiers (DOI), an embedded HTTP(S) server for public data access, access as a network file system, and a scalable storage backend. e!DAL is available as an API for local non-shared storage and as a remote API featuring distributed applications. It can be deployed "out-of-the-box" as an on-site repository.
Conclusions: e!DAL was developed based on experiences coming from decades of research data management at the Leibniz Institute of Plant Genetics and Crop Plant Research (IPK). Initially developed as a data publication and documentation infrastructure for the IPK's role as a data center in the DataCite consortium, e!DAL has grown towards being a general data archiving and publication infrastructure. The e!DAL software has been deployed into the Maven Central Repository. Documentation and Software are also available at: http://edal.ipk-gatersleben.de.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
