

The Pan-Cancer analysis of pseudogene expression reveals biologically and clinically relevant tumour subtypes
- PMID: 24999802
- PMCID: PMC4339277
- DOI: 10.1038/ncomms4963
The Pan-Cancer analysis of pseudogene expression reveals biologically and clinically relevant tumour subtypes
Abstract
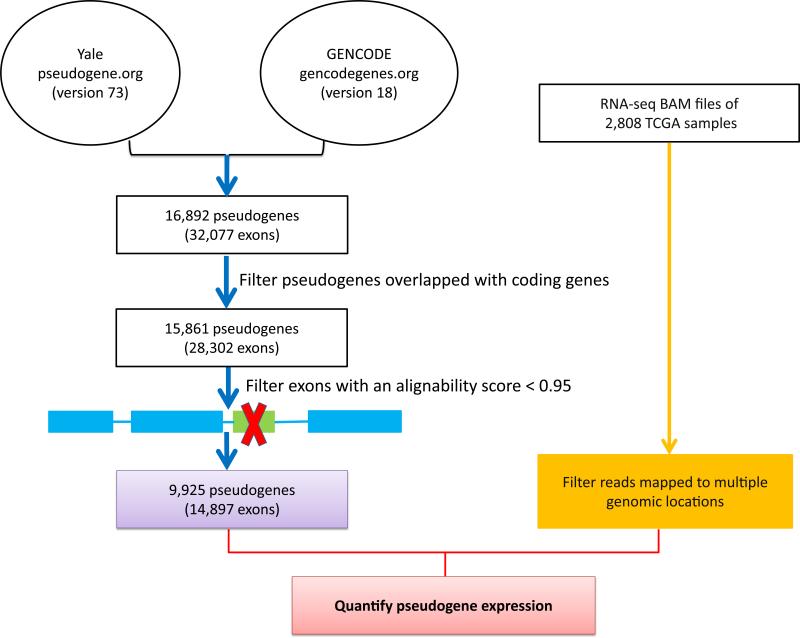
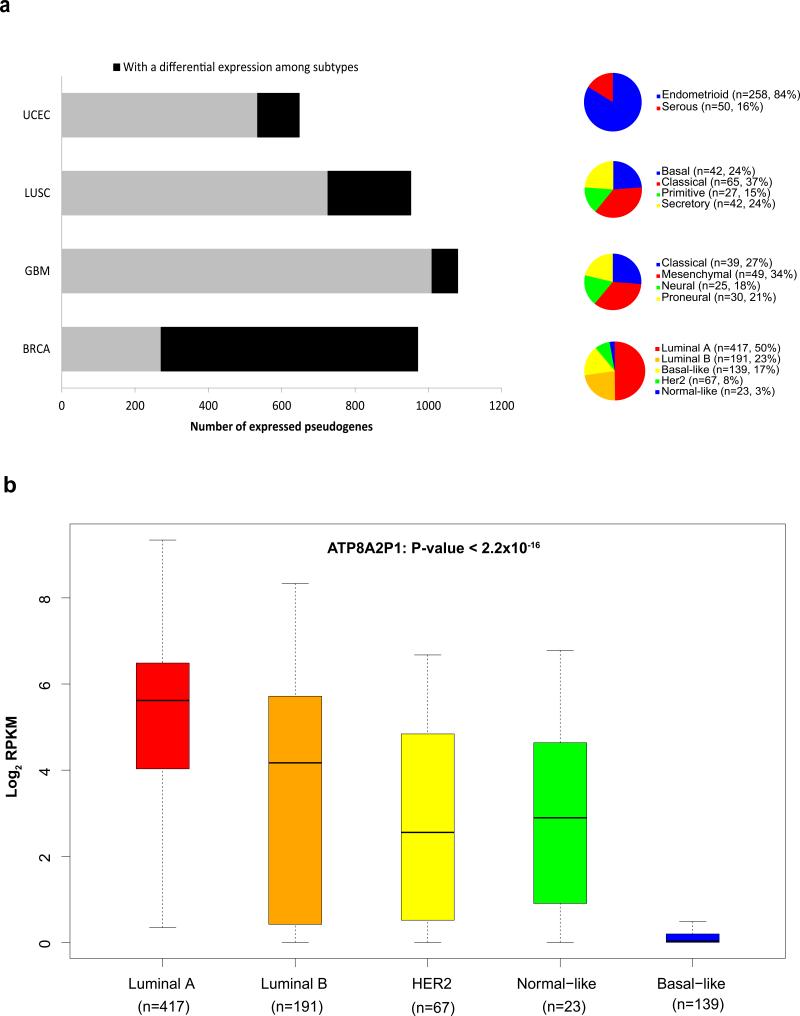
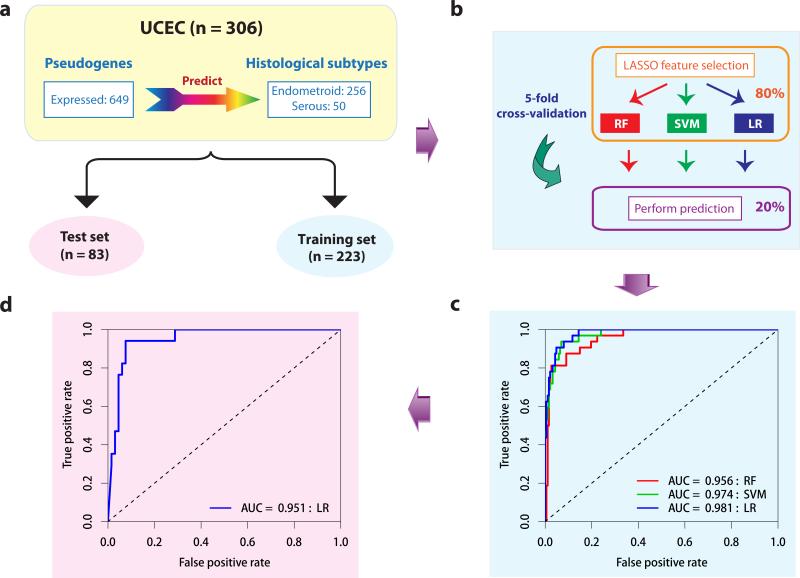
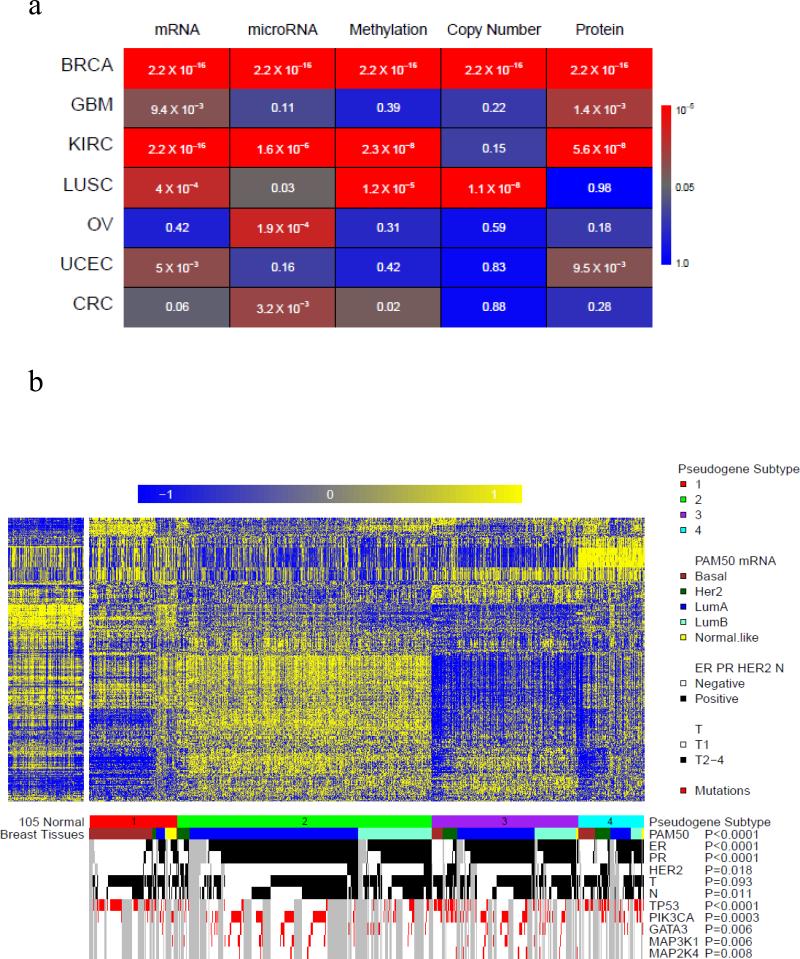
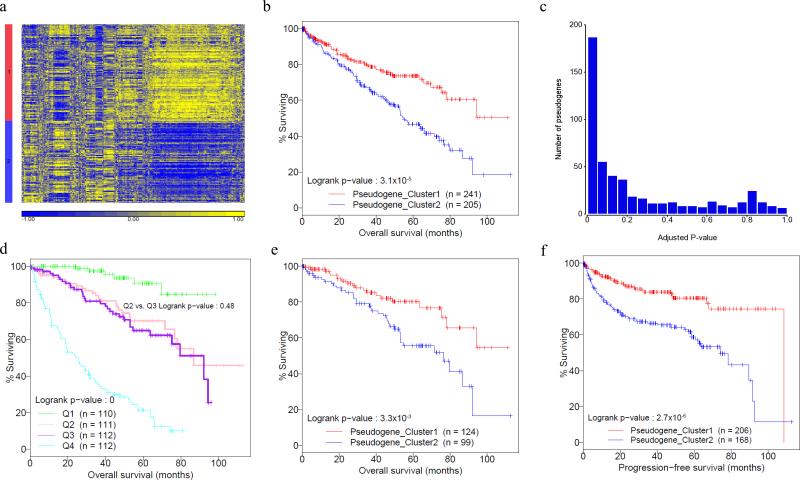
Although individual pseudogenes have been implicated in tumour biology, the biomedical significance and clinical relevance of pseudogene expression have not been assessed in a systematic way. Here we generate pseudogene expression profiles in 2,808 patient samples of seven cancer types from The Cancer Genome Atlas RNA-seq data using a newly developed computational pipeline. Supervised analysis reveals a significant number of pseudogenes differentially expressed among established tumour subtypes and pseudogene expression alone can accurately classify the major histological subtypes of endometrial cancer. Across cancer types, the tumour subtypes revealed by pseudogene expression show extensive and strong concordance with the subtypes defined by other molecular data. Strikingly, in kidney cancer, the pseudogene expression subtypes not only significantly correlate with patient survival, but also help stratify patients in combination with clinical variables. Our study highlights the potential of pseudogene expression analysis as a new paradigm for investigating cancer mechanisms and discovering prognostic biomarkers.
Figures
Comment in
-
Analysis finds value in pseudogenes.Cancer Discov. 2014 Sep;4(9):978-9. doi: 10.1158/2159-8290.CD-NB2014-111. Epub 2014 Jul 24. Cancer Discov. 2014. PMID: 25185168
-
Pseudogene: promising signature for cancer reclassification : comment on "The Pan-Cancer analysis of pseudogene expression reveals biologically and clinically relevant tumour subtypes", Nat Commun. 2014; 5:3963.Med Oncol. 2015 Jan;32(1):354. doi: 10.1007/s12032-014-0354-4. Epub 2014 Nov 28. Med Oncol. 2015. PMID: 25429833 No abstract available.
References
-
- Balakirev ES, Ayala FJ. Pseudogenes: are they “junk” or functional DNA? Annu. Rev. Genet. 2003;37:123–51. - PubMed
-
- Li WH, Gojobori T, Nei M. Pseudogenes as a paradigm of neutral evolution. Nature. 1981;292:237–9. - PubMed
-
- Poliseno L. Pseudogenes: newly discovered players in human cancer. Sci. Signal. 2012;5:re5. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
