

Limestone: high-throughput candidate phenotype generation via tensor factorization
- PMID: 25038555
- PMCID: PMC6563906
- DOI: 10.1016/j.jbi.2014.07.001
Limestone: high-throughput candidate phenotype generation via tensor factorization
Abstract
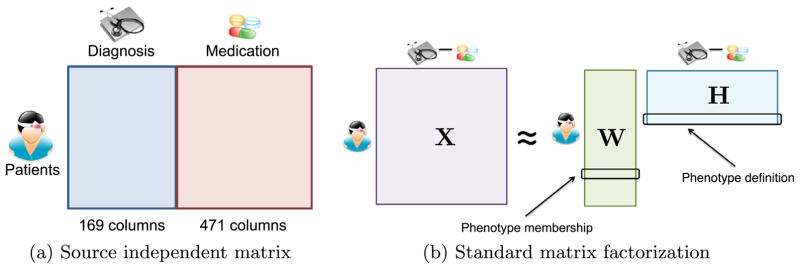
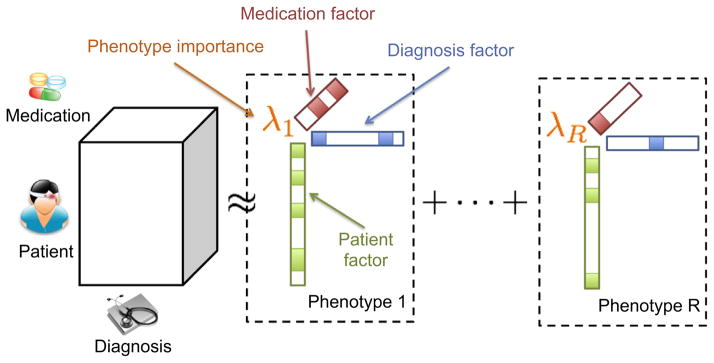
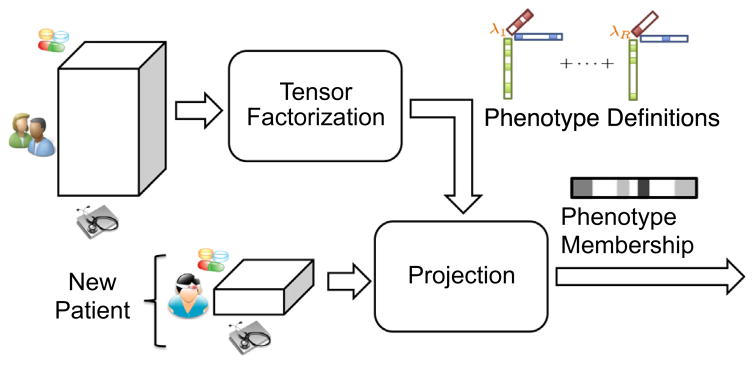
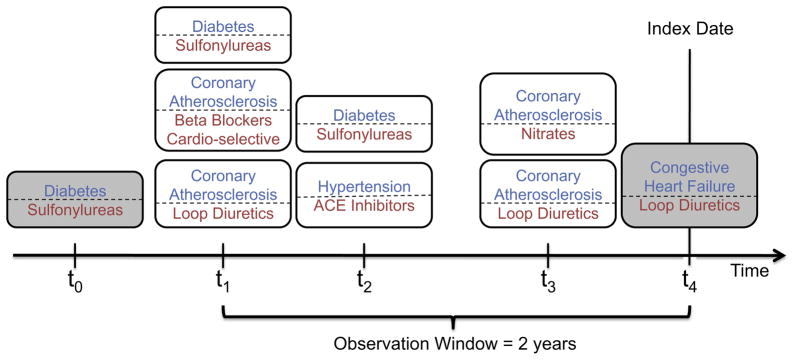
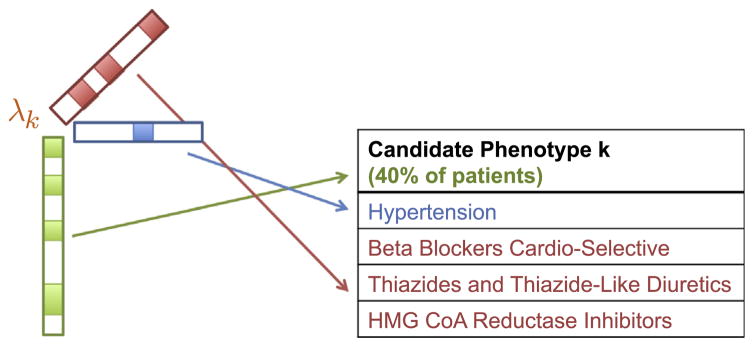
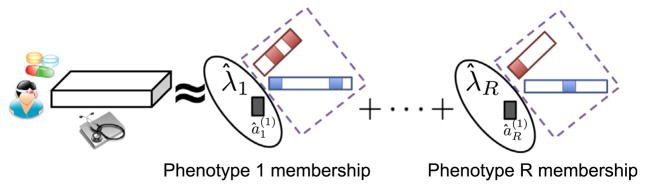
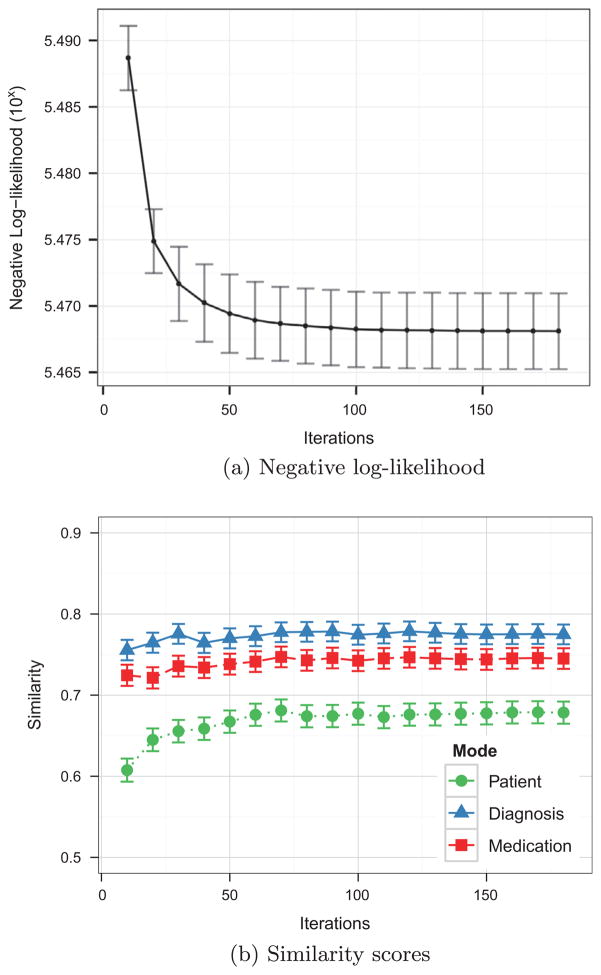
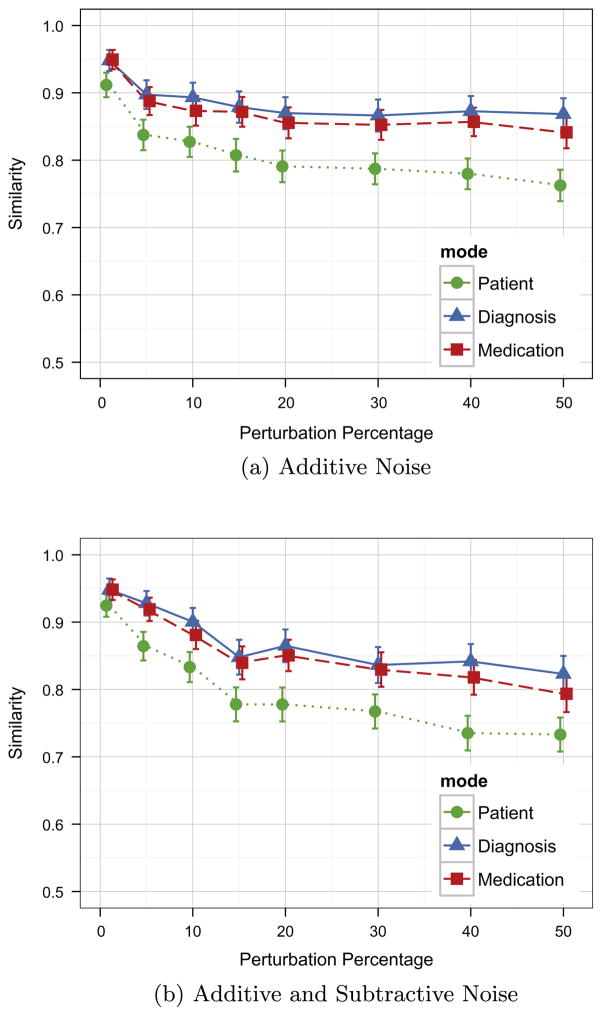
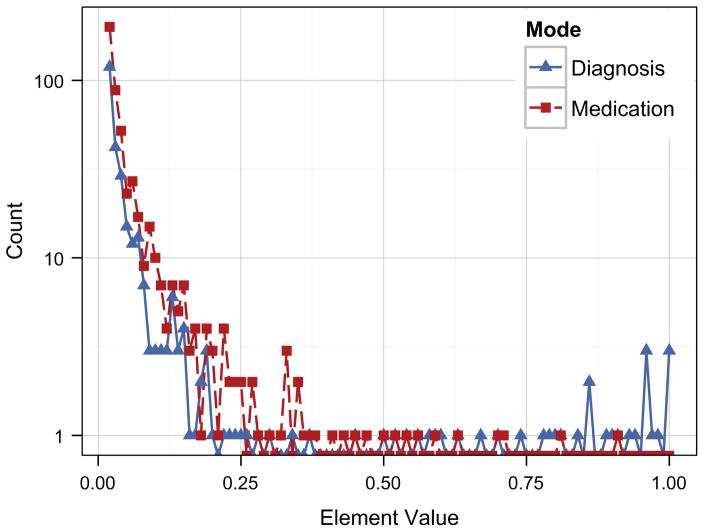
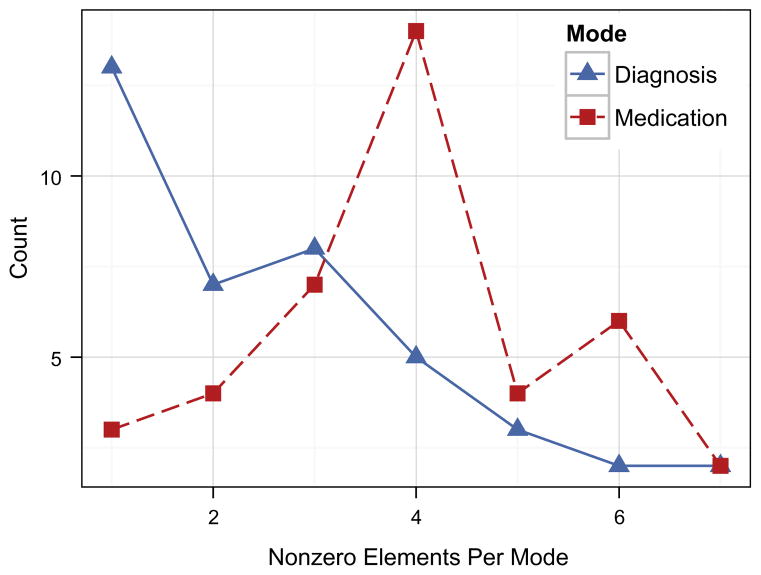
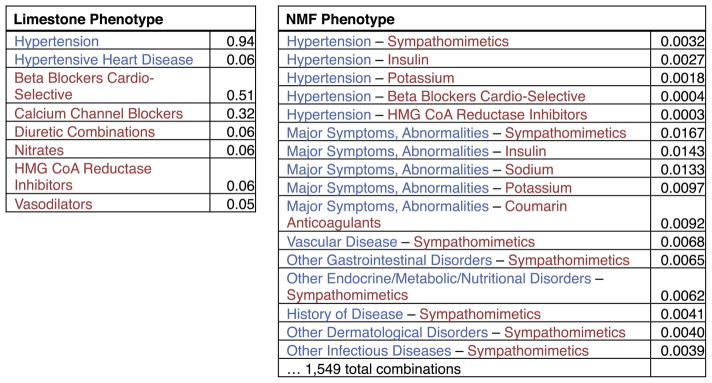
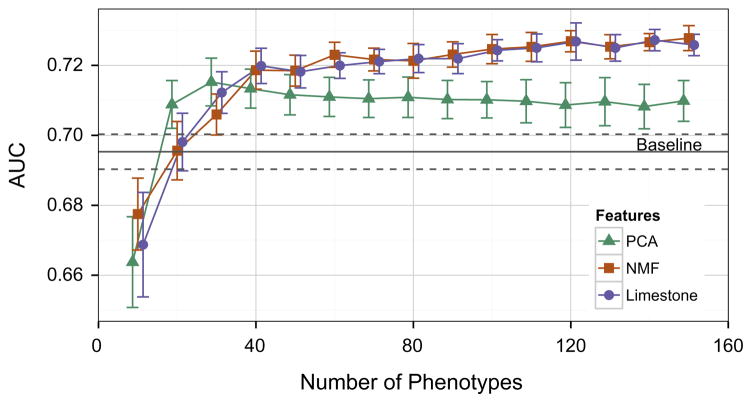
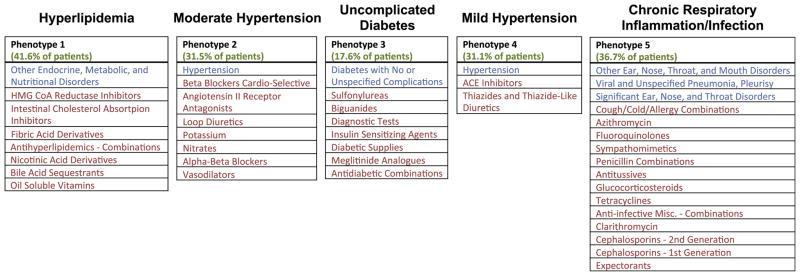
The rapidly increasing availability of electronic health records (EHRs) from multiple heterogeneous sources has spearheaded the adoption of data-driven approaches for improved clinical research, decision making, prognosis, and patient management. Unfortunately, EHR data do not always directly and reliably map to medical concepts that clinical researchers need or use. Some recent studies have focused on EHR-derived phenotyping, which aims at mapping the EHR data to specific medical concepts; however, most of these approaches require labor intensive supervision from experienced clinical professionals. Furthermore, existing approaches are often disease-centric and specialized to the idiosyncrasies of the information technology and/or business practices of a single healthcare organization. In this paper, we propose Limestone, a nonnegative tensor factorization method to derive phenotype candidates with virtually no human supervision. Limestone represents the data source interactions naturally using tensors (a generalization of matrices). In particular, we investigate the interaction of diagnoses and medications among patients. The resulting tensor factors are reported as phenotype candidates that automatically reveal patient clusters on specific diagnoses and medications. Using the proposed method, multiple phenotypes can be identified simultaneously from data. We demonstrate the capability of Limestone on a cohort of 31,815 patient records from the Geisinger Health System. The dataset spans 7years of longitudinal patient records and was initially constructed for a heart failure onset prediction study. Our experiments demonstrate the robustness, stability, and the conciseness of Limestone-derived phenotypes. Our results show that using only 40 phenotypes, we can outperform the original 640 features (169 diagnosis categories and 471 medication types) to achieve an area under the receiver operator characteristic curve (AUC) of 0.720 (95% CI 0.715 to 0.725). Moreover, in consultation with a medical expert, we confirmed 82% of the top 50 candidates automatically extracted by Limestone are clinically meaningful.
Keywords: Dimensionality reduction; EHR phenotyping; Nonnegative tensor factorization.
Copyright © 2014 Elsevier Inc. All rights reserved.
Figures

References
-
- Davis J, Lantz E, Page D, Struyf J, Peissig P, Vidaillet H, et al. Machine learning for personalized medicine: will this drug give me a heart attack. ICML workshop on machine learning for health care applications; 2008.
-
- Ramakrishnan N, Hanauer D, Keller B. Mining electronic health records. Computer. 2010;43:77–81.
-
- Koh HC, Tan G. Data mining applications in healthcare. J Healthcare Inform Manage. 2005;19:64–72. - PubMed
-
- Davis D, Chawla N, Christakis NA, Barabási A. Time to CARE: a collaborative engine for practical disease prediction. Data Min Knowl Discov. 2010;20:388–415.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
