

Compression and fast retrieval of SNP data
- PMID: 25064564
- PMCID: PMC4609015
- DOI: 10.1093/bioinformatics/btu495
Compression and fast retrieval of SNP data
Abstract
Motivation: The increasing interest in rare genetic variants and epistatic genetic effects on complex phenotypic traits is currently pushing genome-wide association study design towards datasets of increasing size, both in the number of studied subjects and in the number of genotyped single nucleotide polymorphisms (SNPs). This, in turn, is leading to a compelling need for new methods for compression and fast retrieval of SNP data.
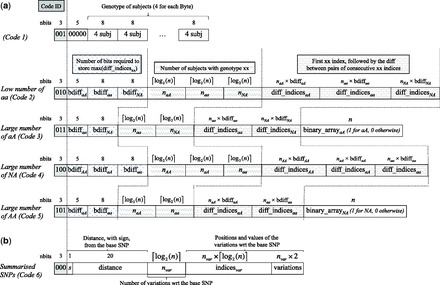
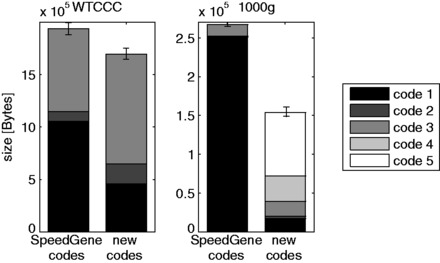
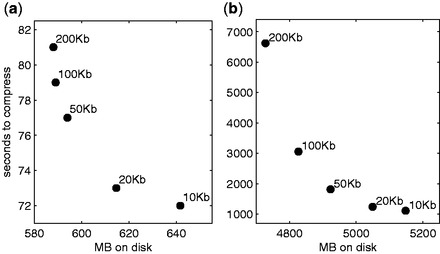
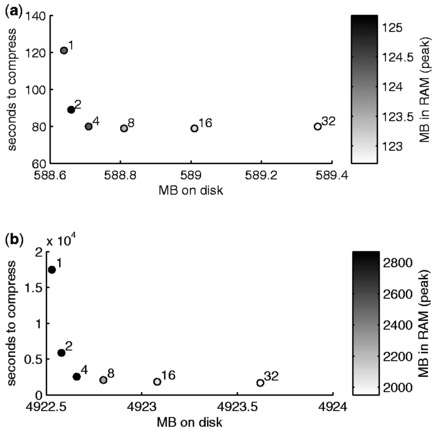
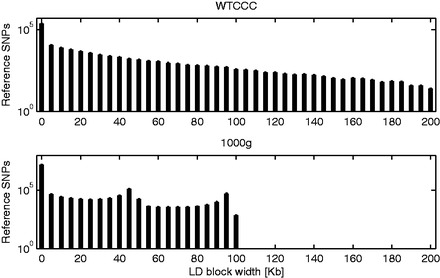
Results: We present a novel algorithm and file format for compressing and retrieving SNP data, specifically designed for large-scale association studies. Our algorithm is based on two main ideas: (i) compress linkage disequilibrium blocks in terms of differences with a reference SNP and (ii) compress reference SNPs exploiting information on their call rate and minor allele frequency. Tested on two SNP datasets and compared with several state-of-the-art software tools, our compression algorithm is shown to be competitive in terms of compression rate and to outperform all tools in terms of time to load compressed data.
Availability and implementation: Our compression and decompression algorithms are implemented in a C++ library, are released under the GNU General Public License and are freely downloadable from http://www.dei.unipd.it/~sambofra/snpack.html.
© The Author 2014. Published by Oxford University Press. All rights reserved. For Permissions, please e-mail: journals.permissions@oup.com.
Figures
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Miscellaneous
