

True zero-training brain-computer interfacing--an online study
- PMID: 25068464
- PMCID: PMC4113217
- DOI: 10.1371/journal.pone.0102504
True zero-training brain-computer interfacing--an online study
Abstract
Despite several approaches to realize subject-to-subject transfer of pre-trained classifiers, the full performance of a Brain-Computer Interface (BCI) for a novel user can only be reached by presenting the BCI system with data from the novel user. In typical state-of-the-art BCI systems with a supervised classifier, the labeled data is collected during a calibration recording, in which the user is asked to perform a specific task. Based on the known labels of this recording, the BCI's classifier can learn to decode the individual's brain signals. Unfortunately, this calibration recording consumes valuable time. Furthermore, it is unproductive with respect to the final BCI application, e.g. text entry. Therefore, the calibration period must be reduced to a minimum, which is especially important for patients with a limited concentration ability. The main contribution of this manuscript is an online study on unsupervised learning in an auditory event-related potential (ERP) paradigm. Our results demonstrate that the calibration recording can be bypassed by utilizing an unsupervised trained classifier, that is initialized randomly and updated during usage. Initially, the unsupervised classifier tends to make decoding mistakes, as the classifier might not have seen enough data to build a reliable model. Using a constant re-analysis of the previously spelled symbols, these initially misspelled symbols can be rectified posthoc when the classifier has learned to decode the signals. We compare the spelling performance of our unsupervised approach and of the unsupervised posthoc approach to the standard supervised calibration-based dogma for n = 10 healthy users. To assess the learning behavior of our approach, it is unsupervised trained from scratch three times per user. Even with the relatively low SNR of an auditory ERP paradigm, the results show that after a limited number of trials (30 trials), the unsupervised approach performs comparably to a classic supervised model.
Conflict of interest statement
Figures




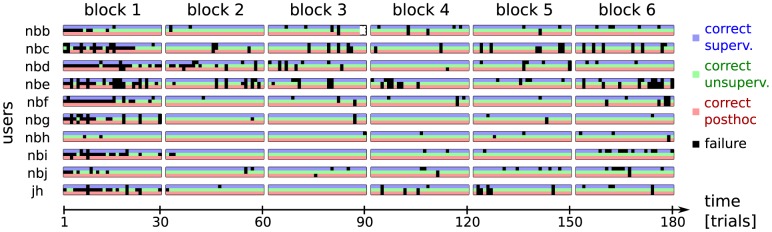
 . Top plot: Online performance of the three blocks per user classified by the supervised LDA approach. Per subject, the classifier had been pre-trained on calibration data (not shown) and kept fix for all three blocks. Middle plot: Online performance of blocks controlled by the unsupervised classifier. The unsupervised classifier had been initialized randomly before each individual block (three times per subject). Bottom plot: performance of the posthoc re-analysis method for the unsupervised blocks. The posthoc classifier, too, had been initialized randomly before each block.
. Top plot: Online performance of the three blocks per user classified by the supervised LDA approach. Per subject, the classifier had been pre-trained on calibration data (not shown) and kept fix for all three blocks. Middle plot: Online performance of blocks controlled by the unsupervised classifier. The unsupervised classifier had been initialized randomly before each individual block (three times per subject). Bottom plot: performance of the posthoc re-analysis method for the unsupervised blocks. The posthoc classifier, too, had been initialized randomly before each block.

 represented by the top line and
represented by the top line and  by the bottom line. For each trial and user, a green square indicates an accurate selection, a black one marks an error. Clearly, the unsupervised classifier commits most erroneous decisions shortly after its random initialization at the beginning of each novel block. In the majority of cases users were able to effectively control the BCI by the end of a block.
by the bottom line. For each trial and user, a green square indicates an accurate selection, a black one marks an error. Clearly, the unsupervised classifier commits most erroneous decisions shortly after its random initialization at the beginning of each novel block. In the majority of cases users were able to effectively control the BCI by the end of a block.

References
-
- Kindermans PJ, Verschore H, Verstraeten D, Schrauwen B (2012) A P300 BCI for the masses: Prior information enables instant unsupervised spelling. In: Advances in Neural Information Processing Systems 25 . pp. 719–727.
-
- Kindermans PJ, Tangermann M, Müller KR, Schrauwen B, (in press) Integrating dynamic stopping, transfer learning and language models in an adaptive zero-training erp speller. Journal of Neural Engineering. - PubMed
-
- Birbaumer N, Ghanayim N, Hinterberger T, Iversen I, Kotchoubey B, et al. (1999) A spelling device for the paralysed. Nature 398: 297–298. - PubMed
-
- Müller KR, Krauledat M, Dornhege G, Curio G, Blankertz B (2004) Machine learning techniques for brain-computer interfaces. Biomed Tech 49: 11–22.
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
