

Fast convergence of learning requires plasticity between inferior olive and deep cerebellar nuclei in a manipulation task: a closed-loop robotic simulation
- PMID: 25177290
- PMCID: PMC4133770
- DOI: 10.3389/fncom.2014.00097
Fast convergence of learning requires plasticity between inferior olive and deep cerebellar nuclei in a manipulation task: a closed-loop robotic simulation
Abstract
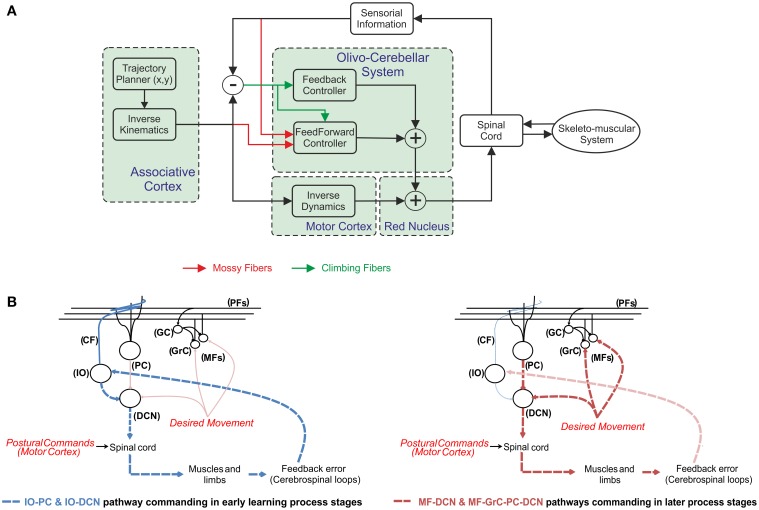
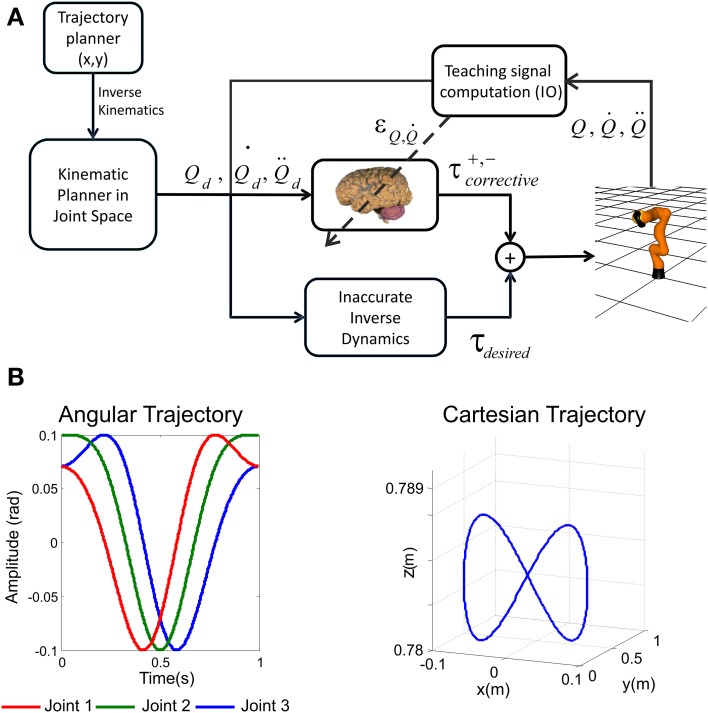
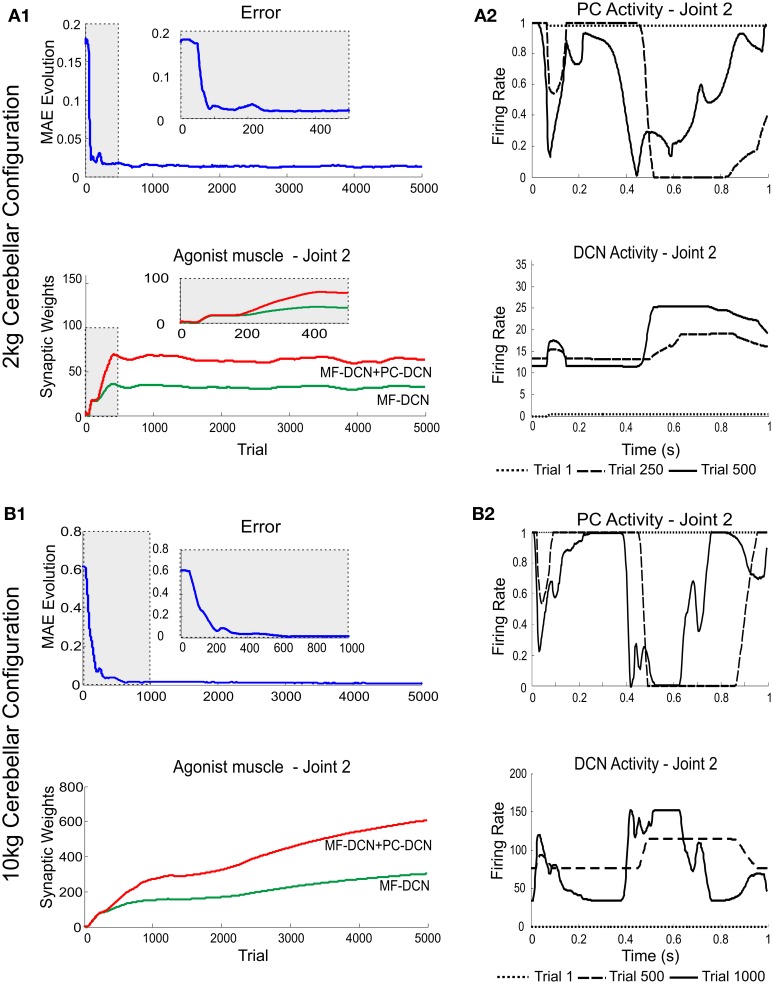
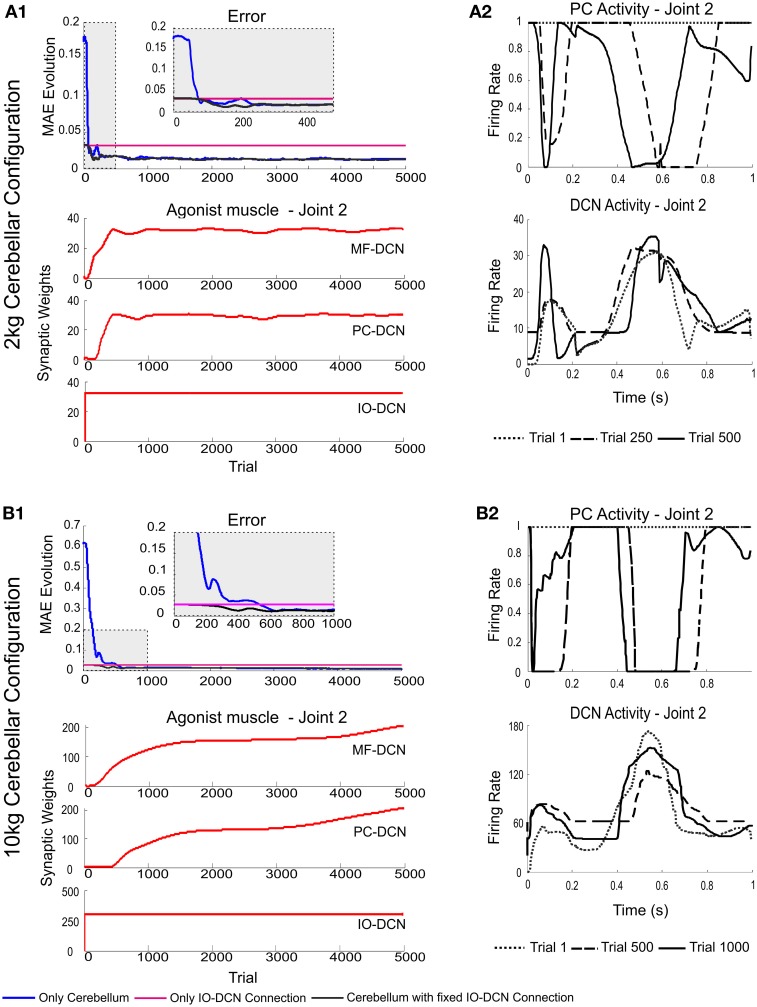
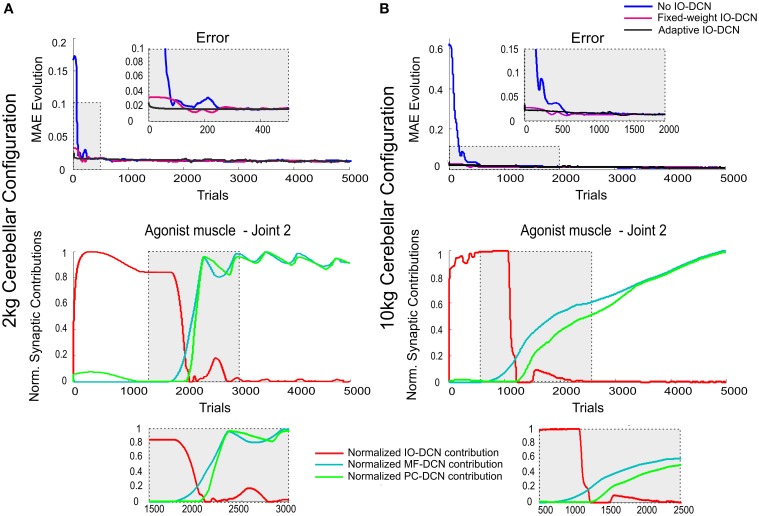
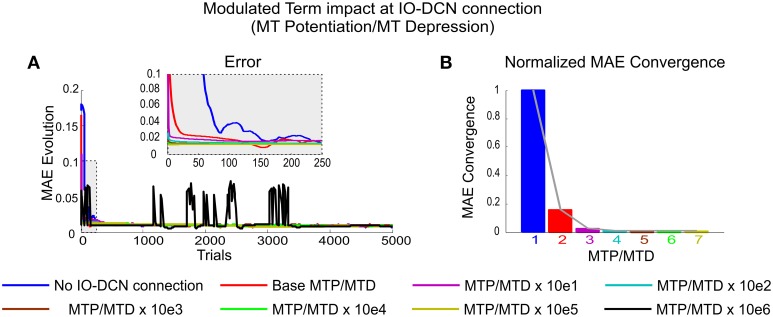
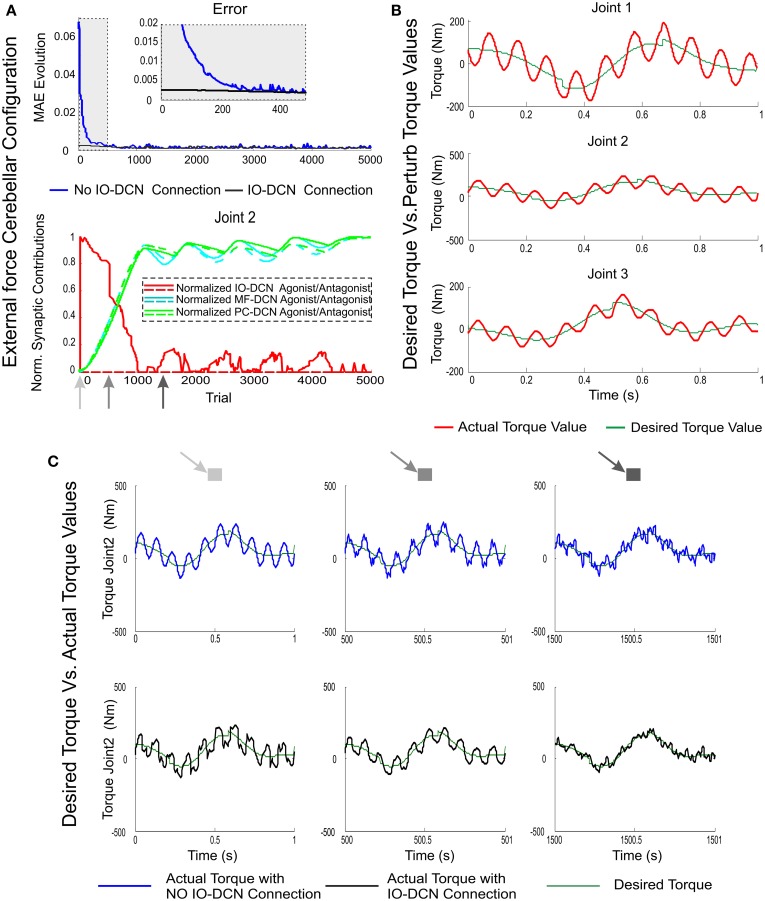
The cerebellum is known to play a critical role in learning relevant patterns of activity for adaptive motor control, but the underlying network mechanisms are only partly understood. The classical long-term synaptic plasticity between parallel fibers (PFs) and Purkinje cells (PCs), which is driven by the inferior olive (IO), can only account for limited aspects of learning. Recently, the role of additional forms of plasticity in the granular layer, molecular layer and deep cerebellar nuclei (DCN) has been considered. In particular, learning at DCN synapses allows for generalization, but convergence to a stable state requires hundreds of repetitions. In this paper we have explored the putative role of the IO-DCN connection by endowing it with adaptable weights and exploring its implications in a closed-loop robotic manipulation task. Our results show that IO-DCN plasticity accelerates convergence of learning by up to two orders of magnitude without conflicting with the generalization properties conferred by DCN plasticity. Thus, this model suggests that multiple distributed learning mechanisms provide a key for explaining the complex properties of procedural learning and open up new experimental questions for synaptic plasticity in the cerebellar network.
Keywords: cerebellar nuclei; inferior olive; learning consolidation; long-term synaptic plasticity; modeling.
Figures
References
-
- Albu-Schäffer A., Haddadin S., Ott C., Stemmer A., Wimböck T., Hirzinger G. (2007). The DLR lightweight robot: design and control concepts for robots in human environments. Int. J. Ind. Rob. 34, 376–385 10.1108/01439910710774386 - DOI
-
- Albus J. S. (1971). A theory of cerebellar function. Math. Biosci. 10, 25–61 10.1016/0025-5564(71)90051-4 - DOI
-
- Arimoto S. (1984). Stability and robustness of PID feedback control for robot manipulators of sensory capability, in Robotics Research, 1st International Symposium (MIT Press), 783–799
Publication types
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Miscellaneous