

Hard Data Analytics Problems Make for Better Data Analysis Algorithms: Bioinformatics as an Example
- PMID: 25276500
- PMCID: PMC4174911
- DOI: 10.1089/big.2014.0023
Hard Data Analytics Problems Make for Better Data Analysis Algorithms: Bioinformatics as an Example
Abstract
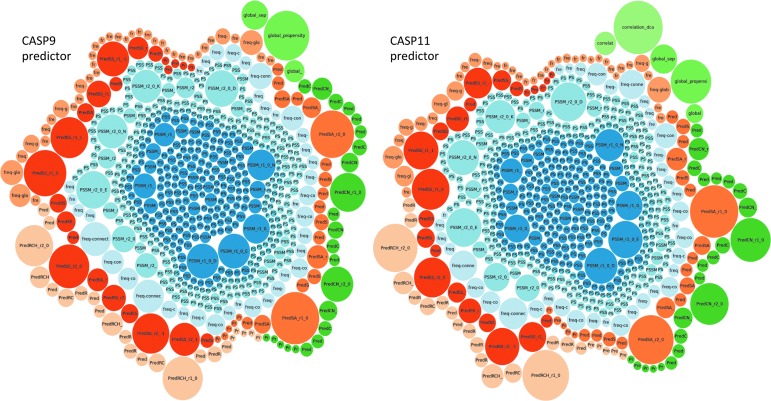
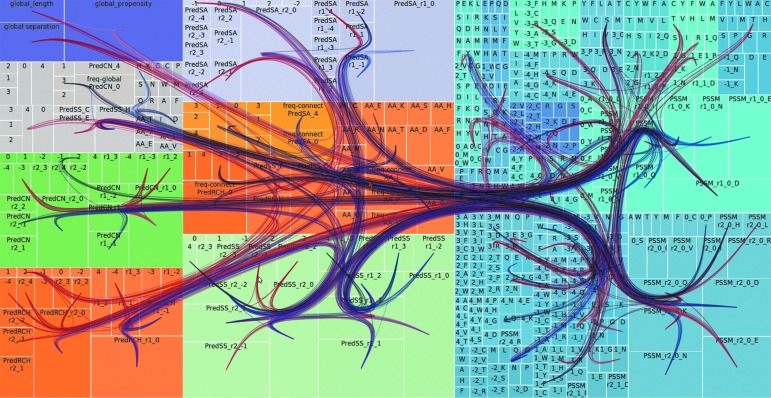
Data mining and knowledge discovery techniques have greatly progressed in the last decade. They are now able to handle larger and larger datasets, process heterogeneous information, integrate complex metadata, and extract and visualize new knowledge. Often these advances were driven by new challenges arising from real-world domains, with biology and biotechnology a prime source of diverse and hard (e.g., high volume, high throughput, high variety, and high noise) data analytics problems. The aim of this article is to show the broad spectrum of data mining tasks and challenges present in biological data, and how these challenges have driven us over the years to design new data mining and knowledge discovery procedures for biodata. This is illustrated with the help of two kinds of case studies. The first kind is focused on the field of protein structure prediction, where we have contributed in several areas: by designing, through regression, functions that can distinguish between good and bad models of a protein's predicted structure; by creating new measures to characterize aspects of a protein's structure associated with individual positions in a protein's sequence, measures containing information that might be useful for protein structure prediction; and by creating accurate estimators of these structural aspects. The second kind of case study is focused on omics data analytics, a class of biological data characterized for having extremely high dimensionalities. Our methods were able not only to generate very accurate classification models, but also to discover new biological knowledge that was later ratified by experimentalists. Finally, we describe several strategies to tightly integrate knowledge extraction and data mining in order to create a new class of biodata mining algorithms that can natively embrace the complexity of biological data, efficiently generate accurate information in the form of classification/regression models, and extract valuable new knowledge. Thus, a complete data-to-information-to-knowledge pipeline is presented.
Figures


References
-
- Schneider MV, Orchard S. Omics technologies, data and bioinformatics principles. Methods Mol Biol 2011; 719:3–30 - PubMed
-
- Stout M, Bacardit J, Hirst JD, Krasnogor N. Prediction of recursive convex hull class assignments for protein residues. Bioinformatics 2008; 24:916–923 - PubMed
-
- Stout M, Bacardit J, Hirst JD, et al. Prediction of topological contacts in proteins using learning classifier systems. Soft Comput 2009; 13:245–258
-
- Widera P, Garibaldi JM, Krasnogor N. GP challenge: evolving energy function for protein structure prediction. Genet Program Evol Mach 2010; 11:61–88
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
