

Segmental intelligibility of synthetic speech produced by rule
- PMID: 2527884
- PMCID: PMC3507386
- DOI: 10.1121/1.398236
Segmental intelligibility of synthetic speech produced by rule
Abstract
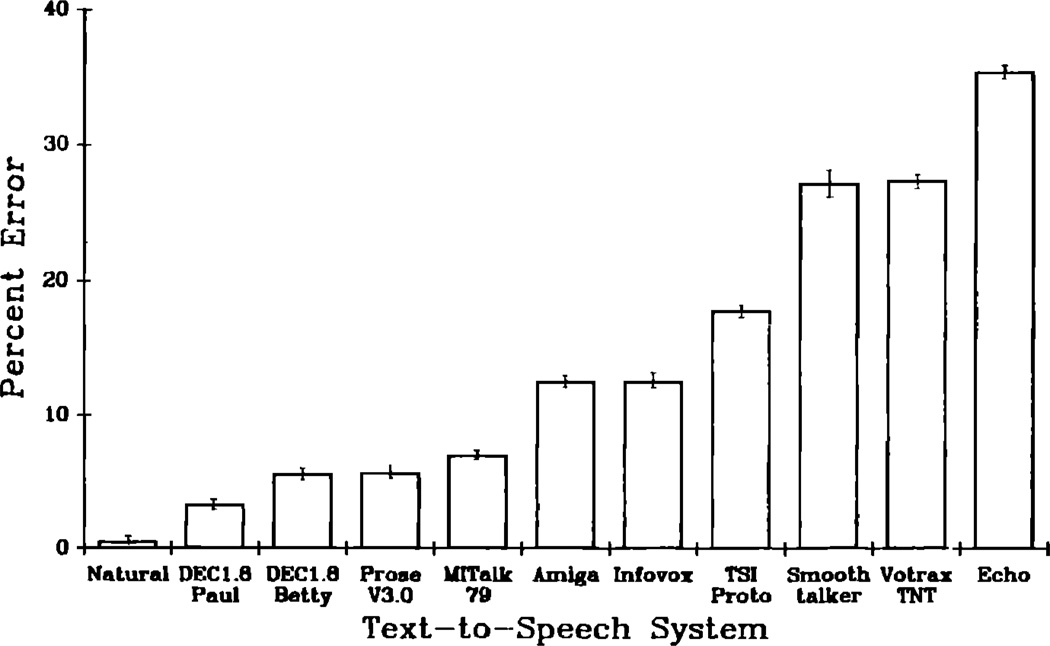
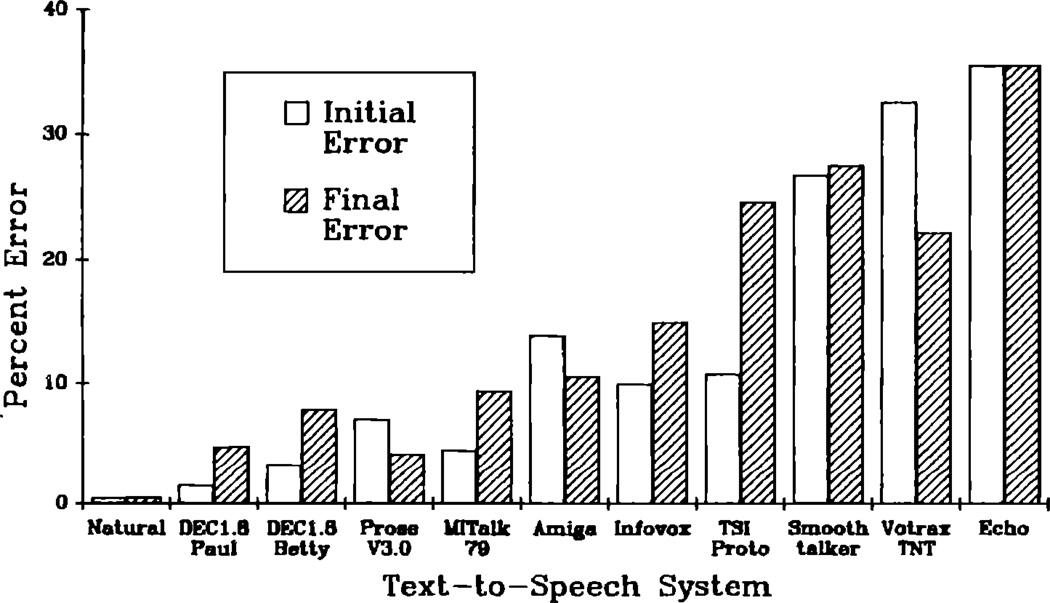
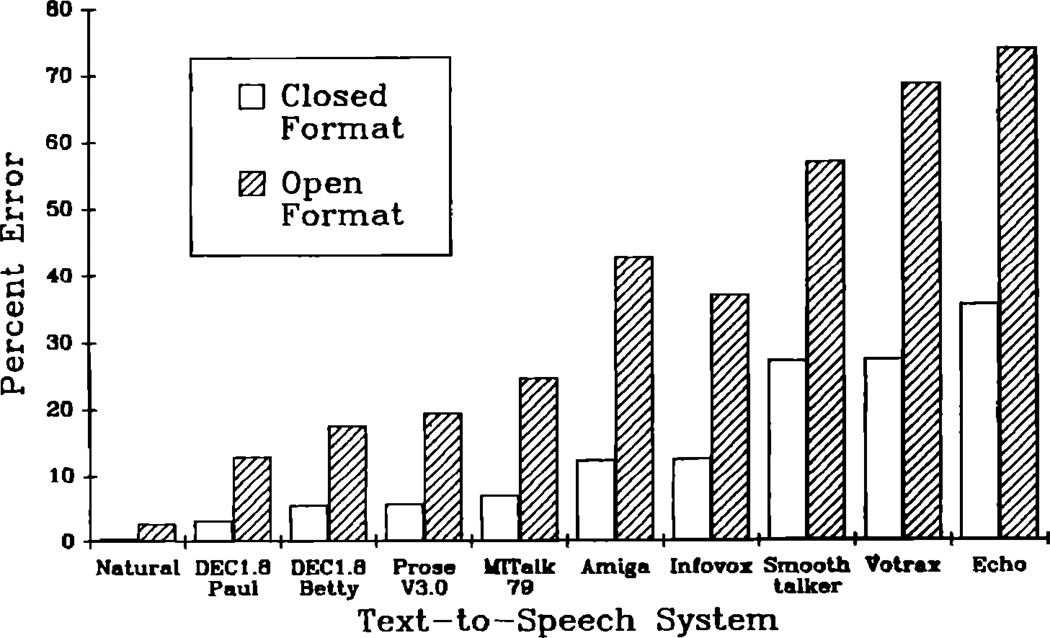
This paper reports the results of an investigation that employed the modified rhyme test (MRT) to measure the segmental intelligibility of synthetic speech generated automatically by rule. Synthetic speech produced by ten text-to-speech systems was studied and compared to natural speech. A variation of the standard MRT was also used to study the effects of response set size on perceptual confusions. Results indicated that the segmental intelligibility scores formed a continuum. Several systems displayed very high levels of performance that were close to or equal to scores obtained with natural speech; other systems displayed substantially worse performance compared to natural speech. The overall performance of the best system, DECtalk--Paul, was equivalent to the data obtained with natural speech for consonants in syllable-initial position. The findings from this study are discussed in terms of the use of a set of standardized procedures for measuring intelligibility of synthetic speech under controlled laboratory conditions. Recent work investigating the perception of synthetic speech under more severe conditions in which greater demands are made on the listener's processing resources is also considered. The wide range of intelligibility scores obtained in the present study demonstrates important differences in perception and suggests that not all synthetic speech is perceptually equivalent to the listener.
Figures
References
-
- Allen J. Synthesis of speech from unrestricted text. Proc. IEEE. 1976;64:433–442.
-
- Allen J. Linguistic-based algorithms offer practical text-to-speech systems. Speech Tech. 1981;1:12–16.
-
- Allen J, Hunnicutt S, Klatt DH. From Text to Speech: The MITalk System. Cambridge, United Kingdom: Cambridge U. P.; 1987.
-
- Bernstein J, Pisoni DB. Unlimited text-to-speech system: Description and evaluation of a microprocessor based device. Proc. Int. Conf. Acoust. Speech Signal Process. 1980;ICASSP-80:576–579.
-
- Bruckert E, Minow M, Tetschner W. Three-tiered software and VLSI aid developmental system to read text aloud. Electronics. 1983;56:133–138.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical