

Functional evaluation of out-of-the-box text-mining tools for data-mining tasks
- PMID: 25336595
- PMCID: PMC4433377
- DOI: 10.1136/amiajnl-2014-002902
Functional evaluation of out-of-the-box text-mining tools for data-mining tasks
Abstract
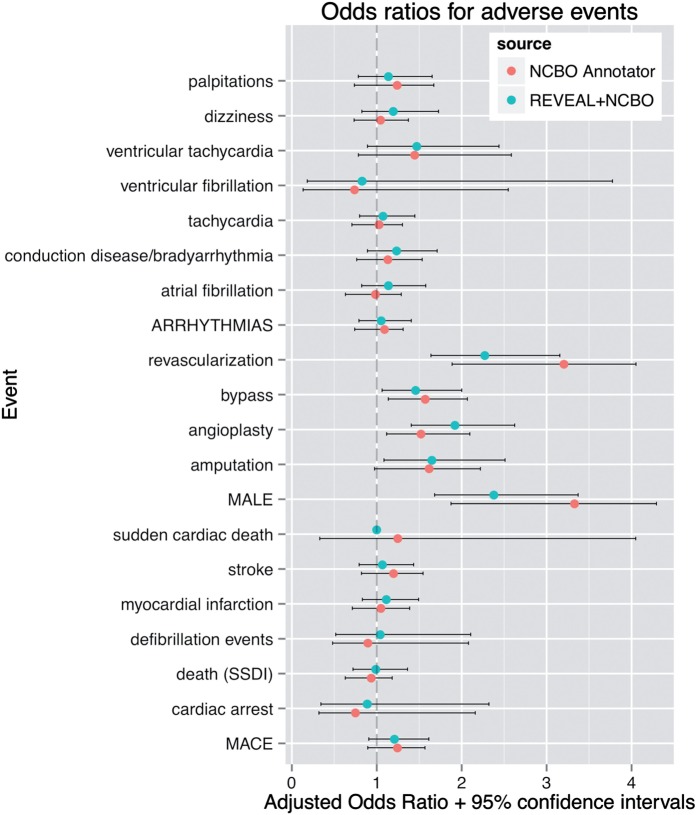
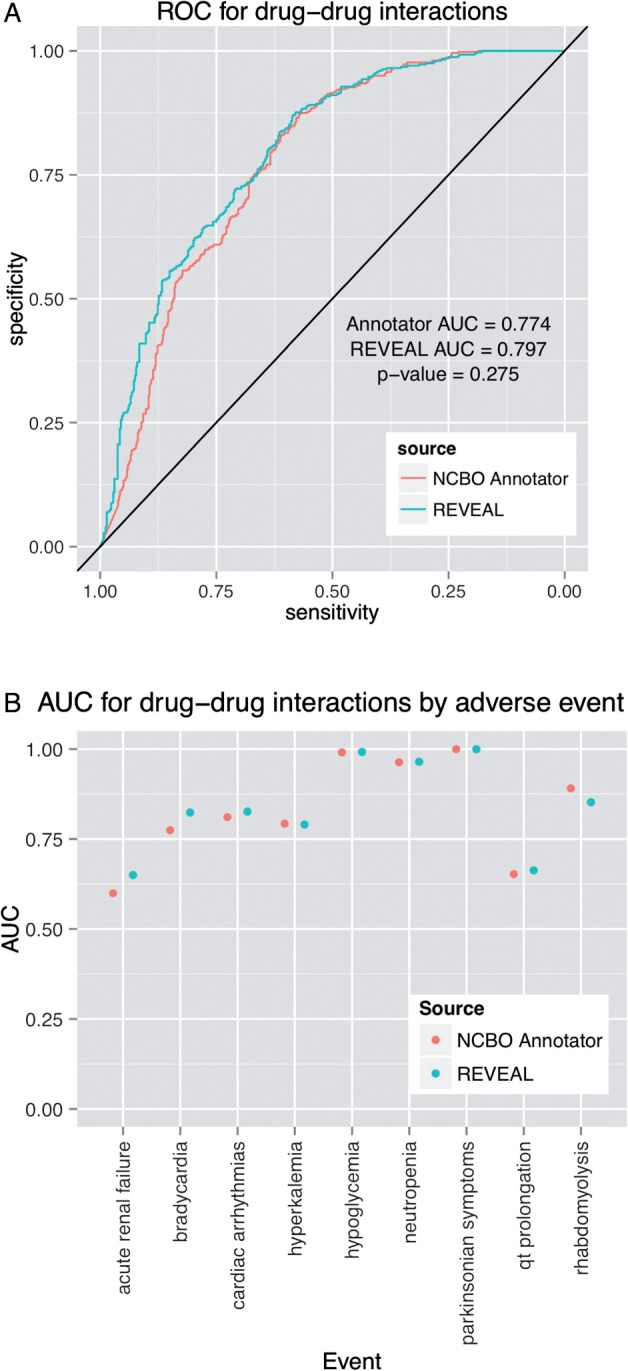
Objective: The trade-off between the speed and simplicity of dictionary-based term recognition and the richer linguistic information provided by more advanced natural language processing (NLP) is an area of active discussion in clinical informatics. In this paper, we quantify this trade-off among text processing systems that make different trade-offs between speed and linguistic understanding. We tested both types of systems in three clinical research tasks: phase IV safety profiling of a drug, learning adverse drug-drug interactions, and learning used-to-treat relationships between drugs and indications.
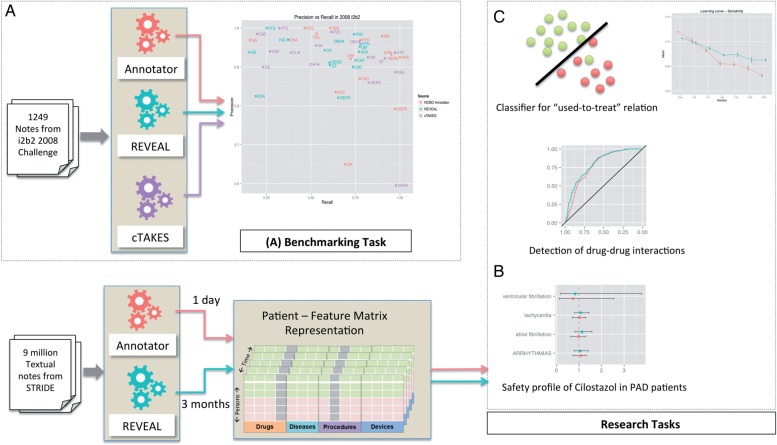
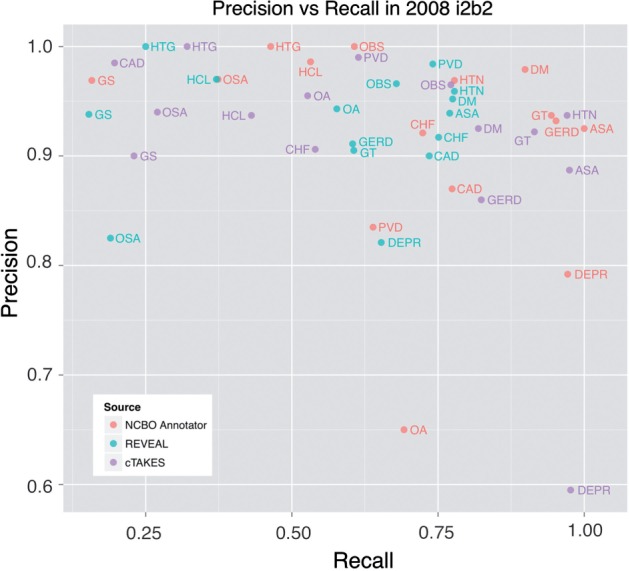
Materials: We first benchmarked the accuracy of the NCBO Annotator and REVEAL in a manually annotated, publically available dataset from the 2008 i2b2 Obesity Challenge. We then applied the NCBO Annotator and REVEAL to 9 million clinical notes from the Stanford Translational Research Integrated Database Environment (STRIDE) and used the resulting data for three research tasks.
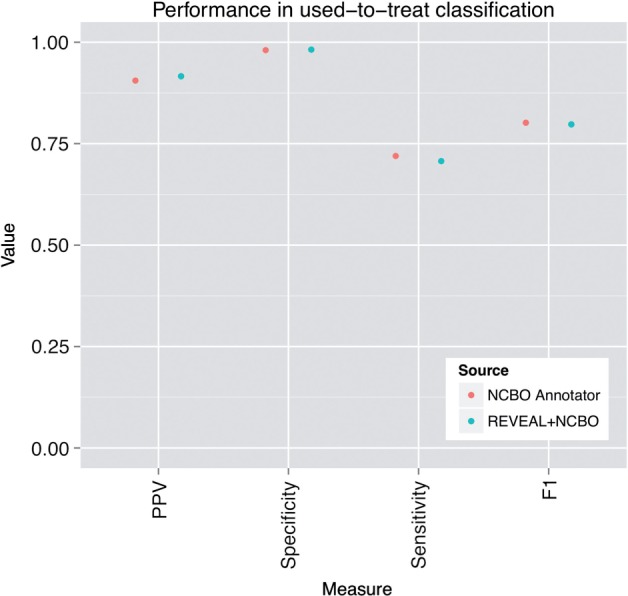
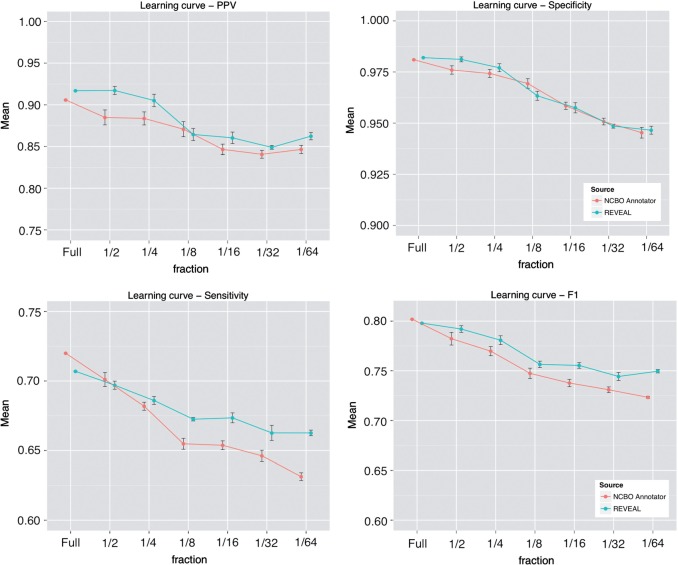
Results: There is no significant difference between using the NCBO Annotator and REVEAL in the results of the three research tasks when using large datasets. In one subtask, REVEAL achieved higher sensitivity with smaller datasets.
Conclusions: For a variety of tasks, employing simple term recognition methods instead of advanced NLP methods results in little or no impact on accuracy when using large datasets. Simpler dictionary-based methods have the advantage of scaling well to very large datasets. Promoting the use of simple, dictionary-based methods for population level analyses can advance adoption of NLP in practice.
Keywords: electronic health records; natural language processing; text mining.
© The Author 2014. Published by Oxford University Press on behalf of the American Medical Informatics Association.
Figures
References
-
- Harpaz R, Haerian K, Chase HS, et al. Mining electronic health records for adverse drug effects using regression based methods. Proceedings of the 1st ACM International Health Informatics Symposium Arlington, Virginia, USA: 1883008: ACM; 2010:100–7 http://dl.acm.org/citation.cfm?id=1883008
-
- Friedman C. Discovering novel adverse drug events using natural language processing and mining of the electronic health record. AMIE 2009: Proceedings of the 12th Conference on Artificial Intelligence in Medicine 2009:1–5.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
