

Real-time learning of predictive recognition categories that chunk sequences of items stored in working memory
- PMID: 25339918
- PMCID: PMC4186345
- DOI: 10.3389/fpsyg.2014.01053
Real-time learning of predictive recognition categories that chunk sequences of items stored in working memory
Abstract
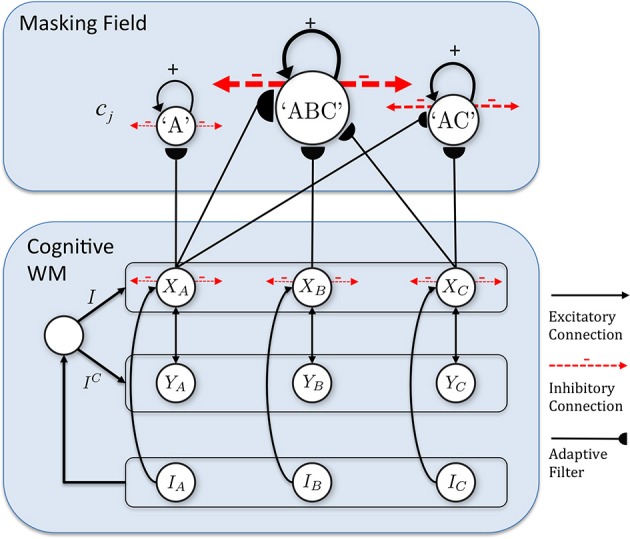
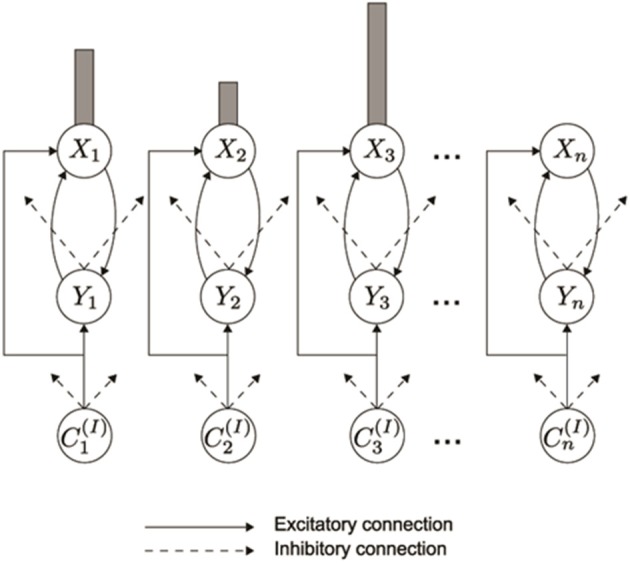
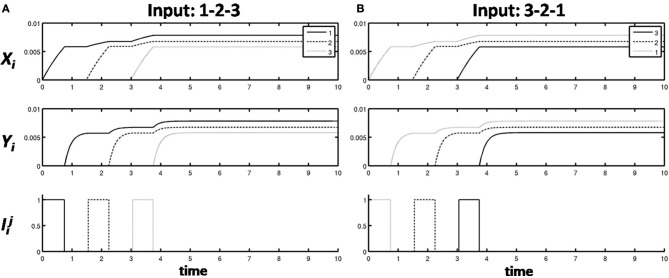
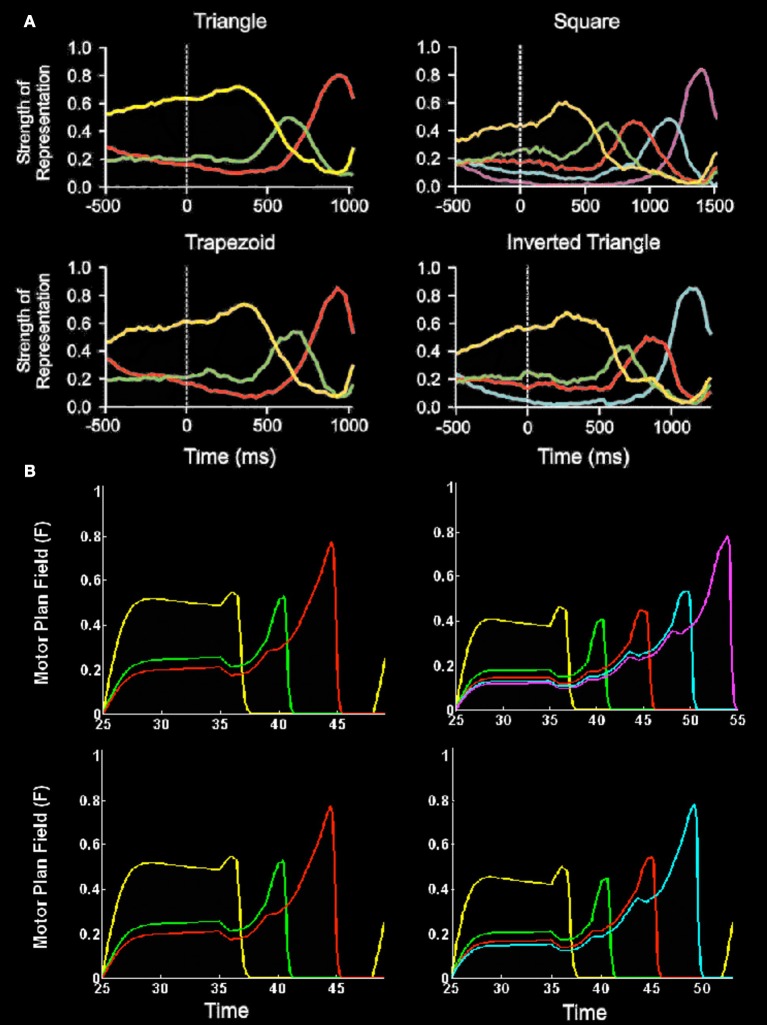
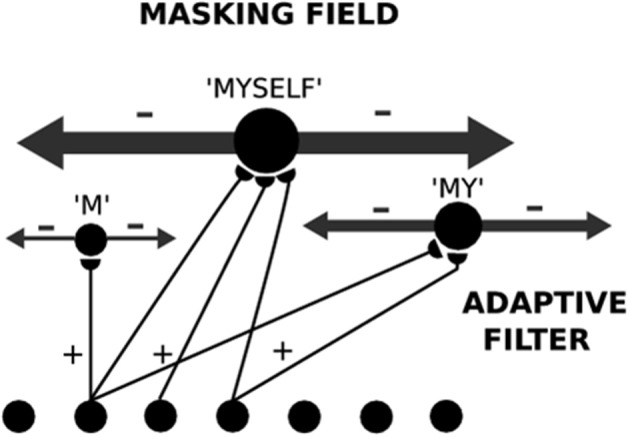
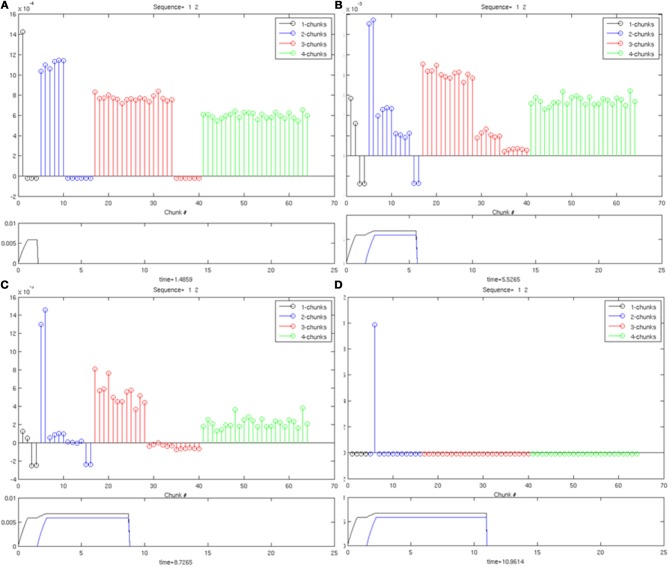
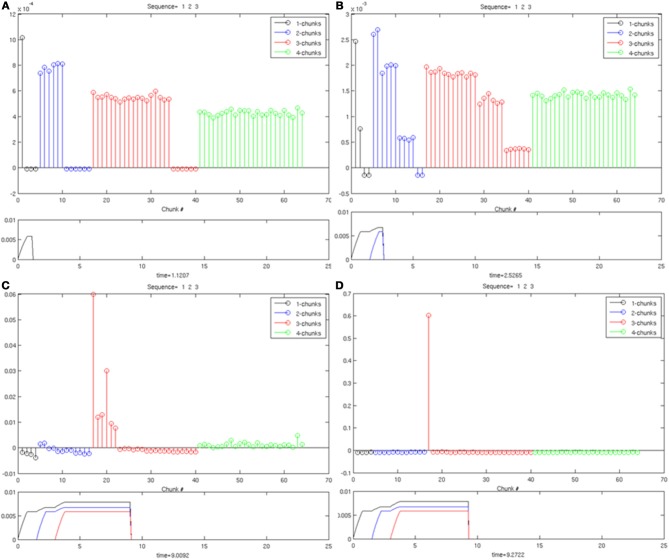
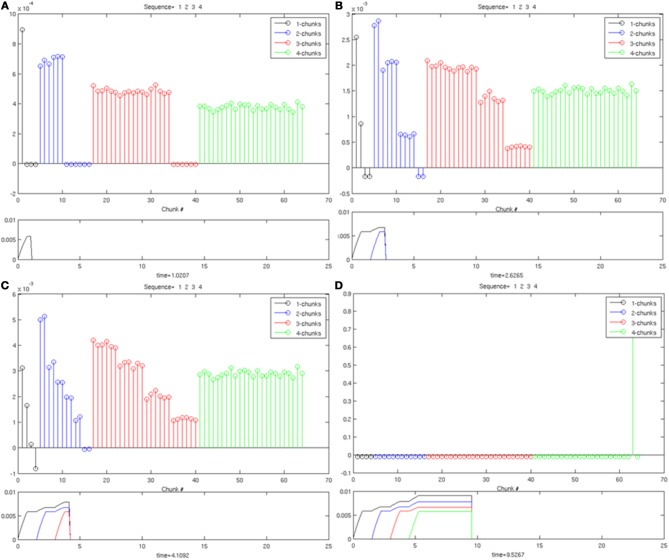
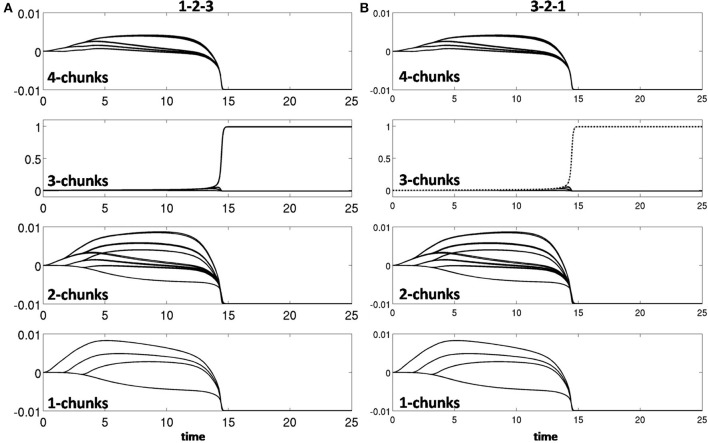
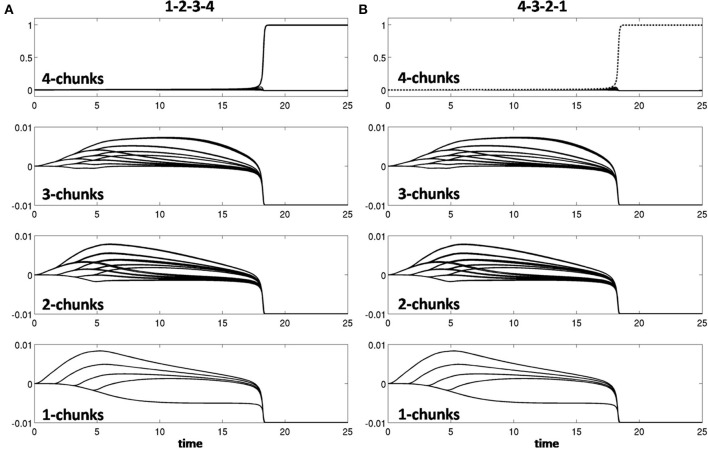
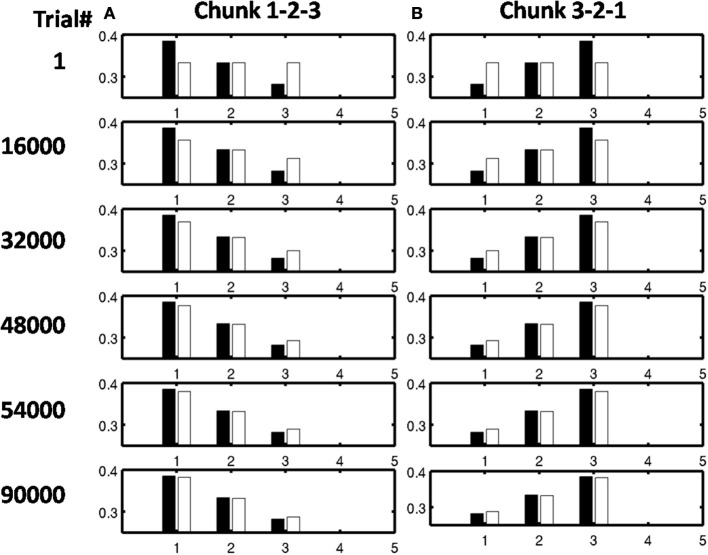
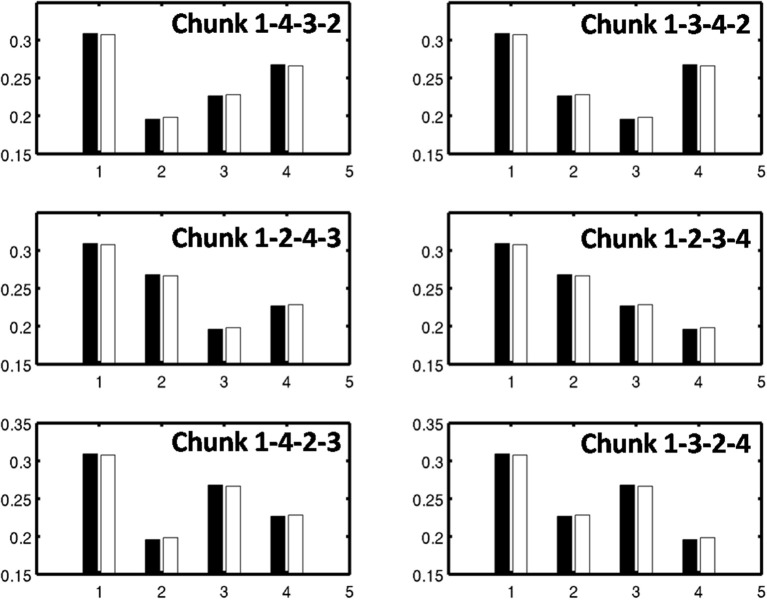
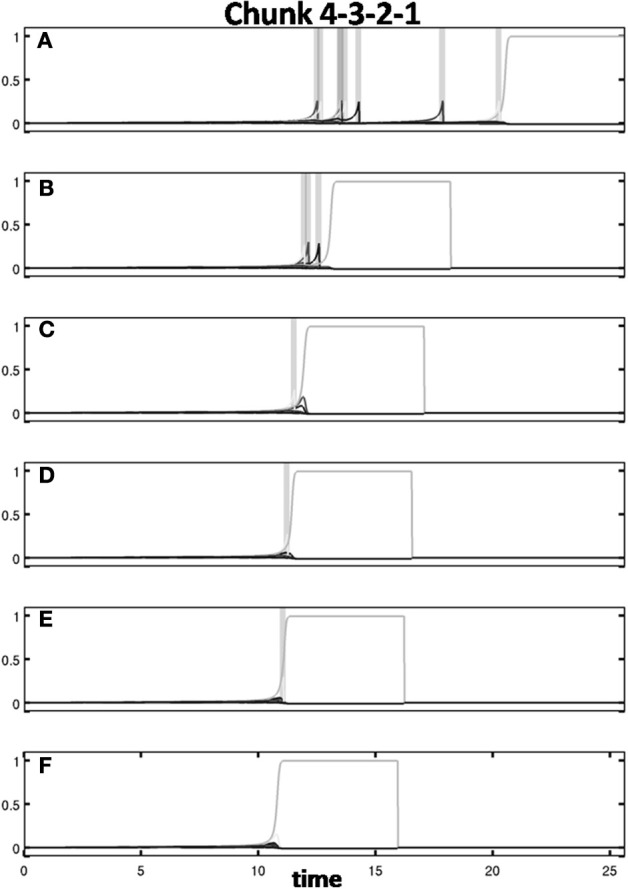
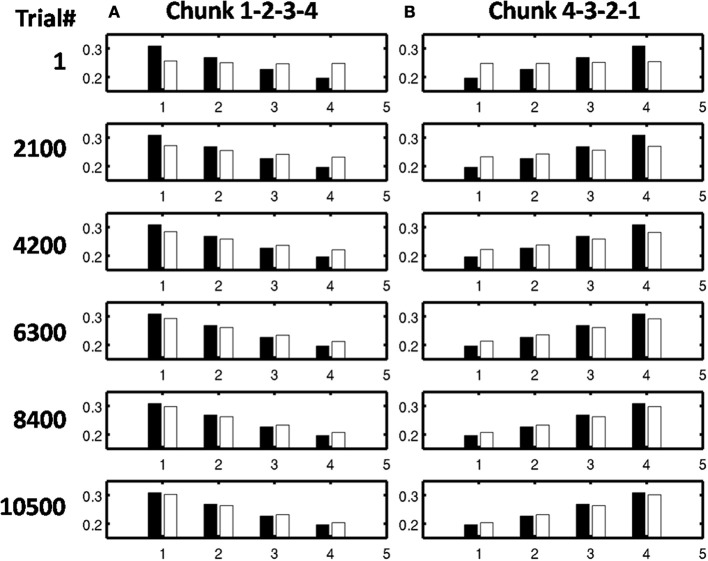
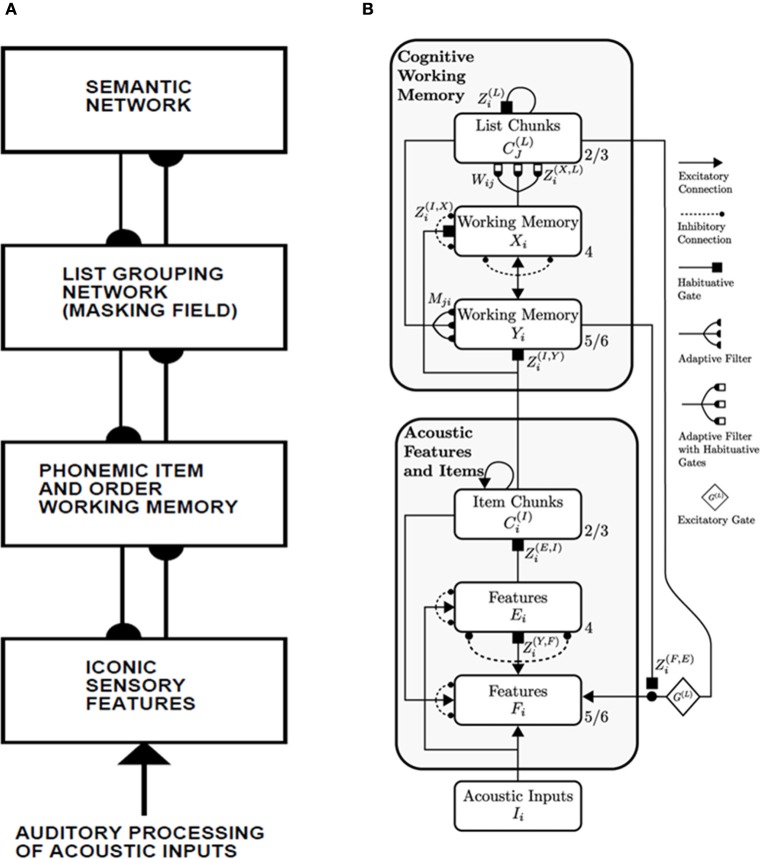
How are sequences of events that are temporarily stored in a cognitive working memory unitized, or chunked, through learning? Such sequential learning is needed by the brain in order to enable language, spatial understanding, and motor skills to develop. In particular, how does the brain learn categories, or list chunks, that become selectively tuned to different temporal sequences of items in lists of variable length as they are stored in working memory, and how does this learning process occur in real time? The present article introduces a neural model that simulates learning of such list chunks. In this model, sequences of items are temporarily stored in an Item-and-Order, or competitive queuing, working memory before learning categorizes them using a categorization network, called a Masking Field, which is a self-similar, multiple-scale, recurrent on-center off-surround network that can weigh the evidence for variable-length sequences of items as they are stored in the working memory through time. A Masking Field hereby activates the learned list chunks that represent the most predictive item groupings at any time, while suppressing less predictive chunks. In a network with a given number of input items, all possible ordered sets of these item sequences, up to a fixed length, can be learned with unsupervised or supervised learning. The self-similar multiple-scale properties of Masking Fields interacting with an Item-and-Order working memory provide a natural explanation of George Miller's Magical Number Seven and Nelson Cowan's Magical Number Four. The article explains why linguistic, spatial, and action event sequences may all be stored by Item-and-Order working memories that obey similar design principles, and thus how the current results may apply across modalities. Item-and-Order properties may readily be extended to Item-Order-Rank working memories in which the same item can be stored in multiple list positions, or ranks, as in the list ABADBD. Comparisons with other models, including TRACE, MERGE, and TISK, are made.
Keywords: Adaptive Resonance Theory; Magical Number 7; Masking Field; Time Invariant String Kernel; capacity limits; category learning; speech perception; working memory.
Figures
References
LinkOut - more resources
Full Text Sources
Other Literature Sources