

UniProt: a hub for protein information
- PMID: 25348405
- PMCID: PMC4384041
- DOI: 10.1093/nar/gku989
UniProt: a hub for protein information
Abstract
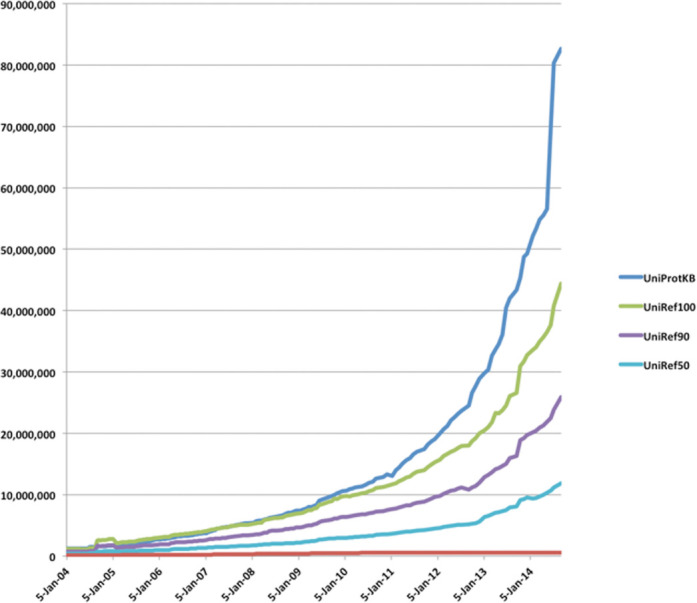
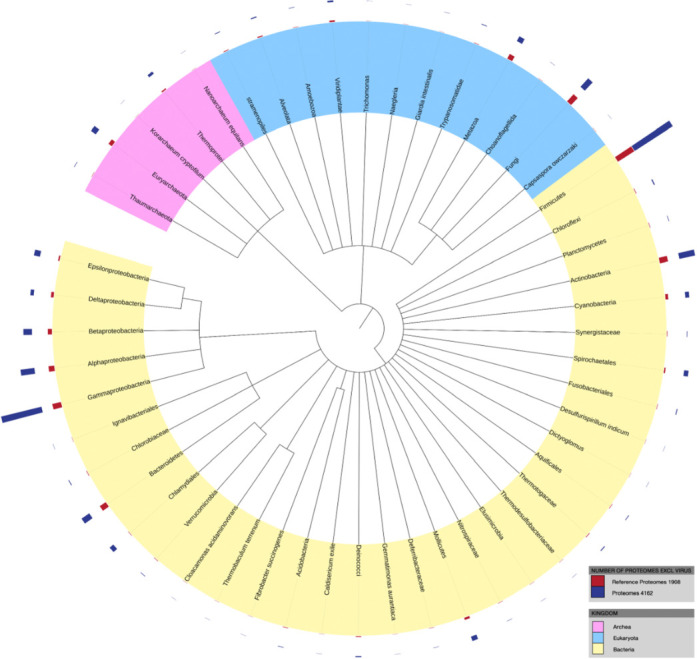
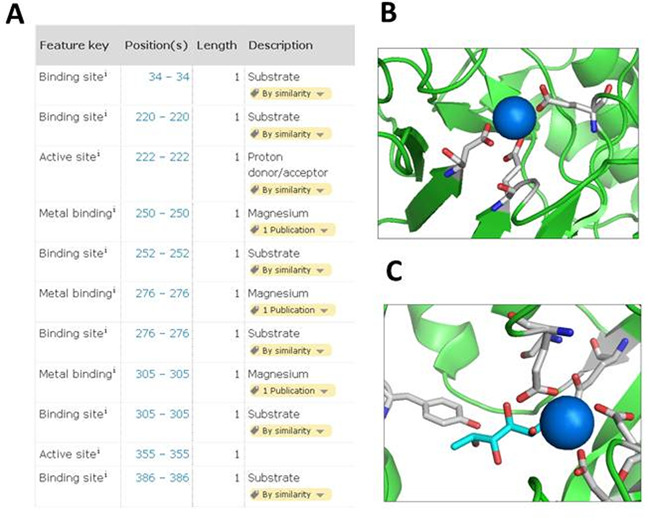
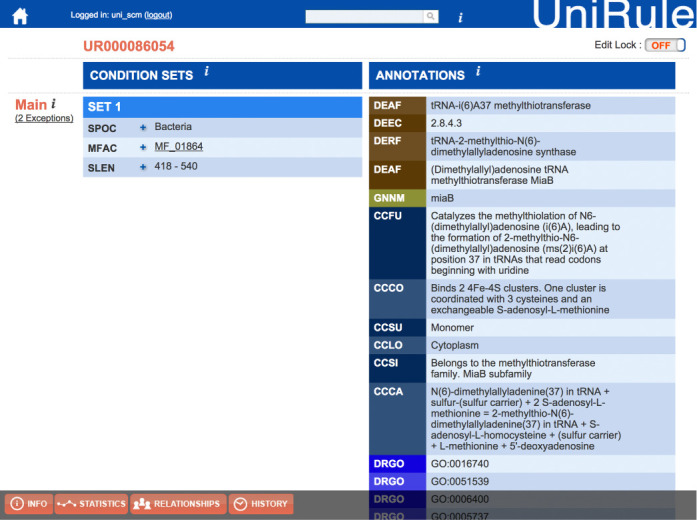
UniProt is an important collection of protein sequences and their annotations, which has doubled in size to 80 million sequences during the past year. This growth in sequences has prompted an extension of UniProt accession number space from 6 to 10 characters. An increasing fraction of new sequences are identical to a sequence that already exists in the database with the majority of sequences coming from genome sequencing projects. We have created a new proteome identifier that uniquely identifies a particular assembly of a species and strain or subspecies to help users track the provenance of sequences. We present a new website that has been designed using a user-experience design process. We have introduced an annotation score for all entries in UniProt to represent the relative amount of knowledge known about each protein. These scores will be helpful in identifying which proteins are the best characterized and most informative for comparative analysis. All UniProt data is provided freely and is available on the web at http://www.uniprot.org/.
© The Author(s) 2014. Published by Oxford University Press on behalf of Nucleic Acids Research.
Figures
References
-
- Suzek B.E., Huang H., McGarvey P., Mazumder R., Wu C.H. UniRef: comprehensive and non-redundant UniProt reference clusters. Bioinformatics. 2007;23:1282–1288. - PubMed
-
- Leinonen R., Diez F.G., Binns D., Fleischmann W., Lopez R., Apweiler R. UniProt archive. Bioinformatics. 2004;20:3236–3237. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
- R01 GM080646/GM/NIGMS NIH HHS/United States
- G08LM010720/LM/NLM NIH HHS/United States
- U41 HG002273/HG/NHGRI NIH HHS/United States
- G-1307/PUK_/Parkinson's UK/United Kingdom
- U41HG007822/HG/NHGRI NIH HHS/United States
- P20GM103446/GM/NIGMS NIH HHS/United States
- U41HG006104/HG/NHGRI NIH HHS/United States
- WT_/Wellcome Trust/United Kingdom
- U41HG002273/HG/NHGRI NIH HHS/United States
- R01GM080646/GM/NIGMS NIH HHS/United States
- P20 GM103446/GM/NIGMS NIH HHS/United States
- RG/13/5/30112/BHF_/British Heart Foundation/United Kingdom
- U41 HG007822/HG/NHGRI NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Miscellaneous
