

CDD: NCBI's conserved domain database
- PMID: 25414356
- PMCID: PMC4383992
- DOI: 10.1093/nar/gku1221
CDD: NCBI's conserved domain database
Abstract
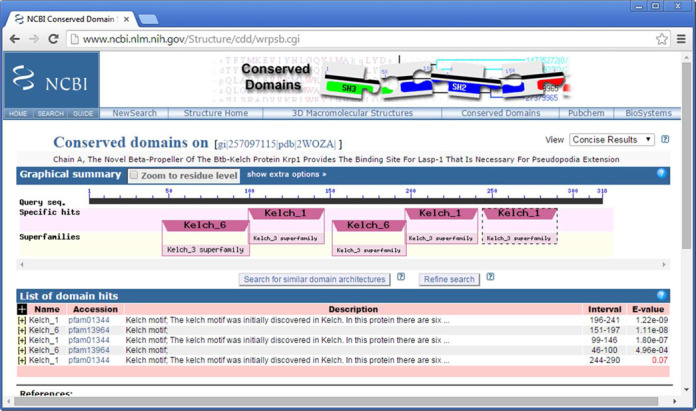
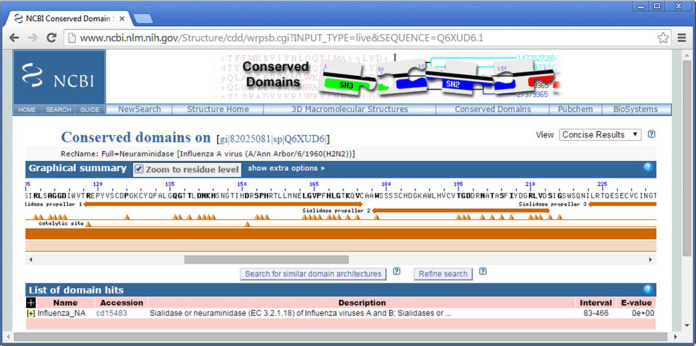
NCBI's CDD, the Conserved Domain Database, enters its 15(th) year as a public resource for the annotation of proteins with the location of conserved domain footprints. Going forward, we strive to improve the coverage and consistency of domain annotation provided by CDD. We maintain a live search system as well as an archive of pre-computed domain annotation for sequences tracked in NCBI's Entrez protein database, which can be retrieved for single sequences or in bulk. We also maintain import procedures so that CDD contains domain models and domain definitions provided by several collections available in the public domain, as well as those produced by an in-house curation effort. The curation effort aims at increasing coverage and providing finer-grained classifications of common protein domains, for which a wealth of functional and structural data has become available. CDD curation generates alignment models of representative sequence fragments, which are in agreement with domain boundaries as observed in protein 3D structure, and which model the structurally conserved cores of domain families as well as annotate conserved features. CDD can be accessed at http://www.ncbi.nlm.nih.gov/Structure/cdd/cdd.shtml.
Published by Oxford University Press on behalf of Nucleic Acids Research 2014. This work is written by US Government employees and is in the public domain in the US.
Figures
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
