

Controlling for population structure and genotyping platform bias in the eMERGE multi-institutional biobank linked to electronic health records
- PMID: 25414722
- PMCID: PMC4220165
- DOI: 10.3389/fgene.2014.00352
Controlling for population structure and genotyping platform bias in the eMERGE multi-institutional biobank linked to electronic health records
Abstract
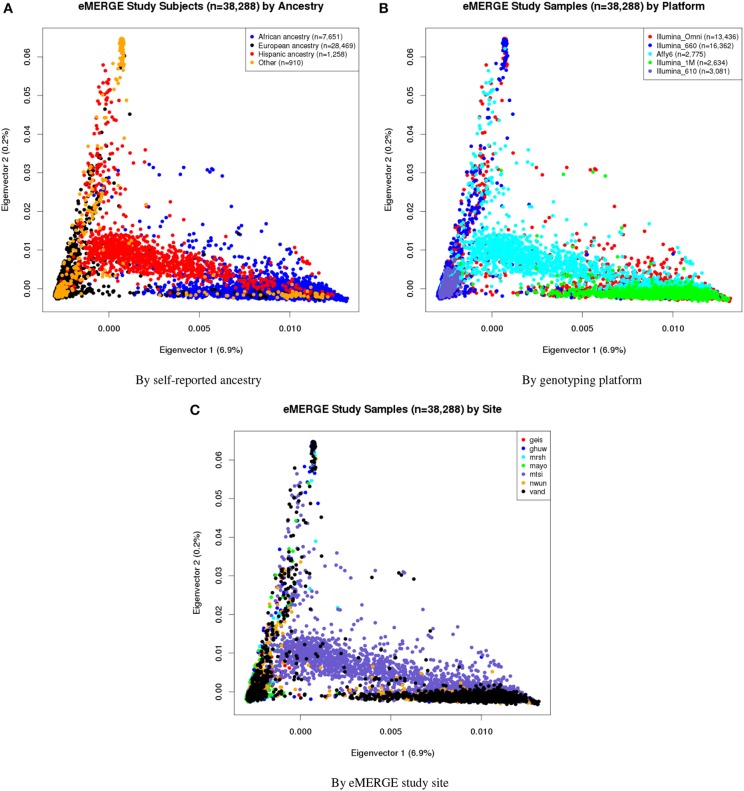
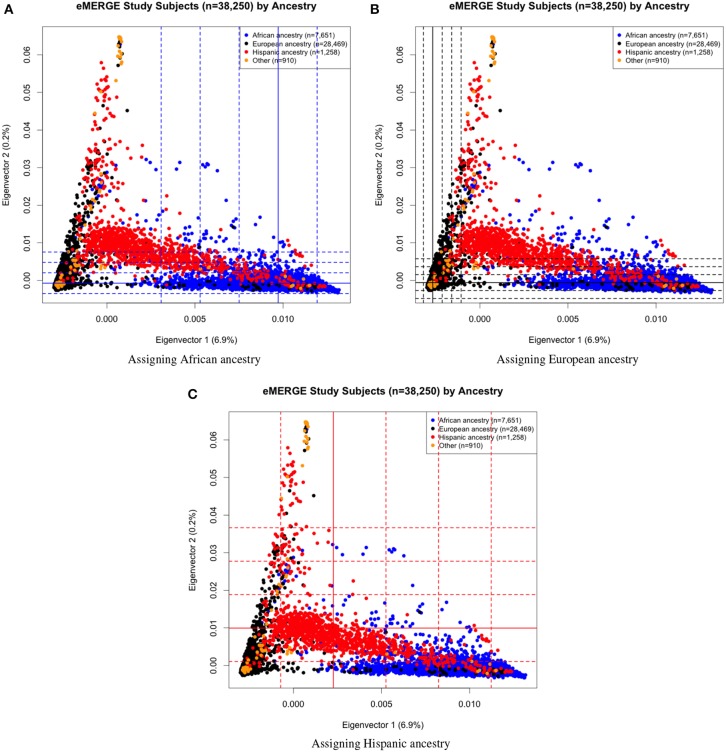
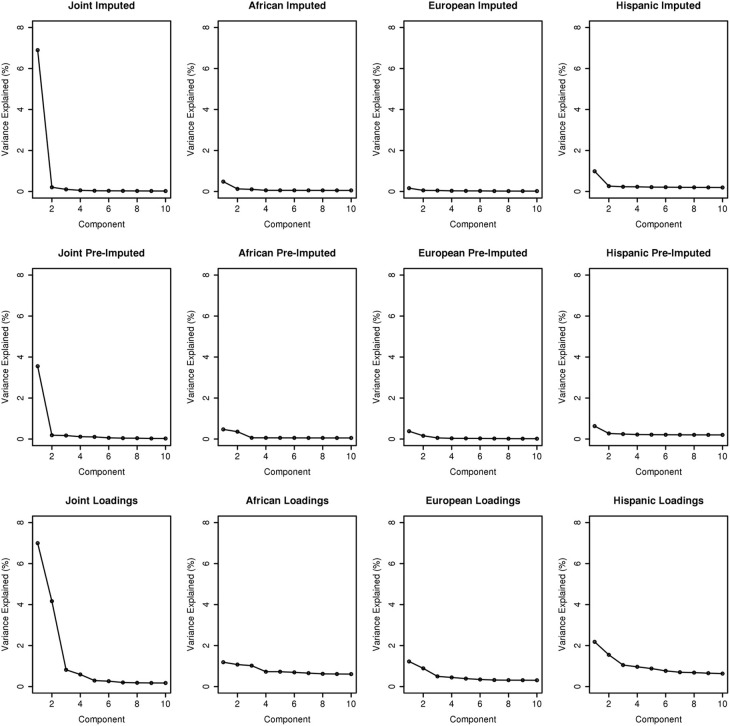
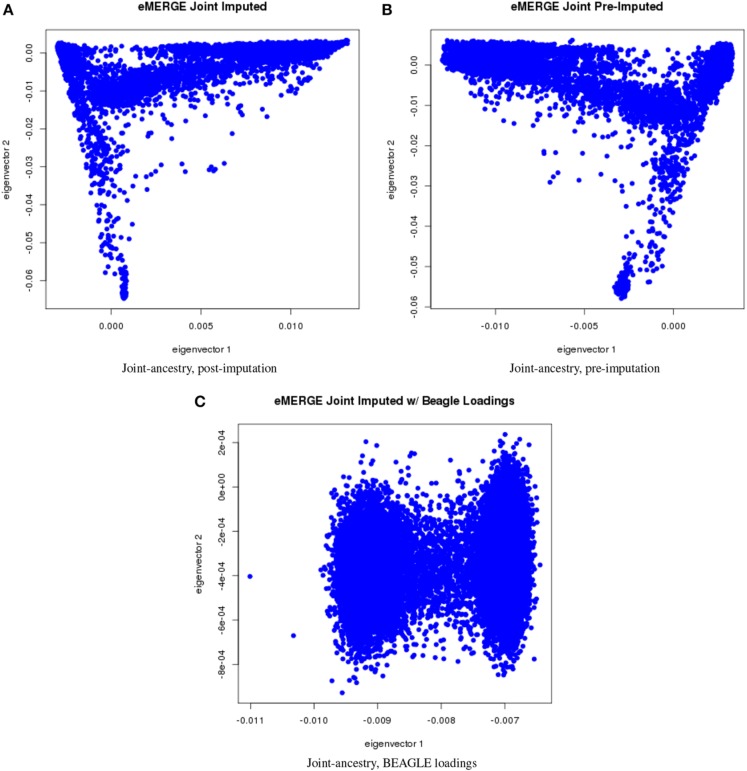
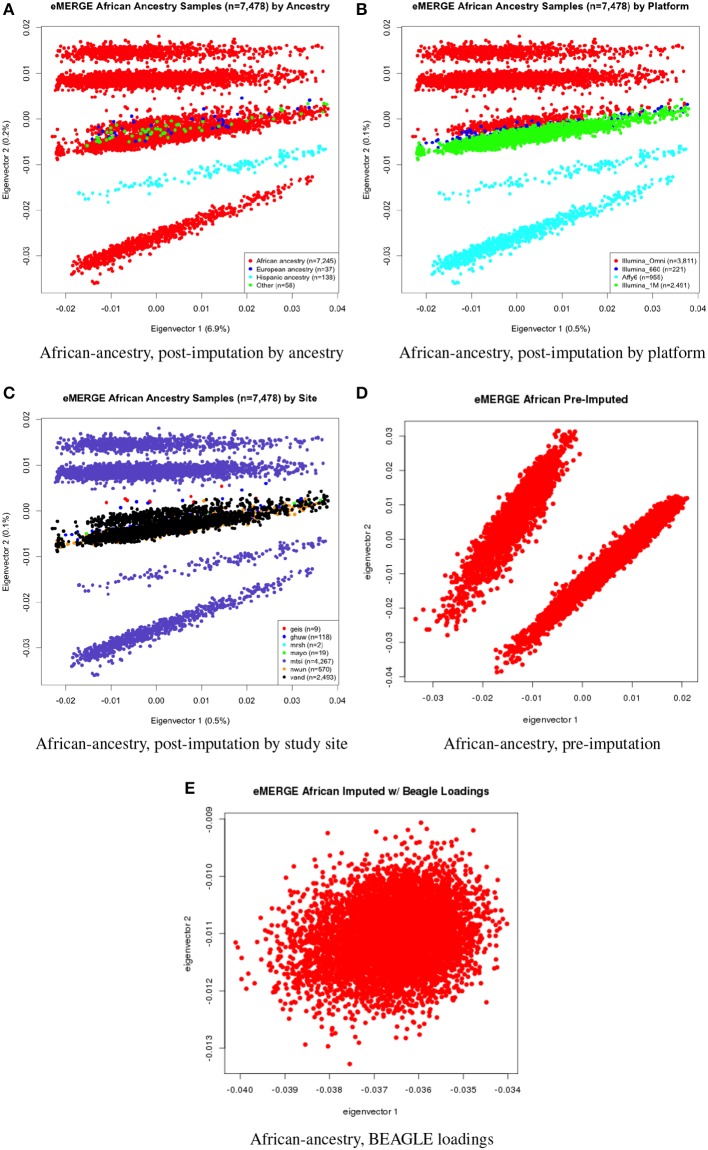
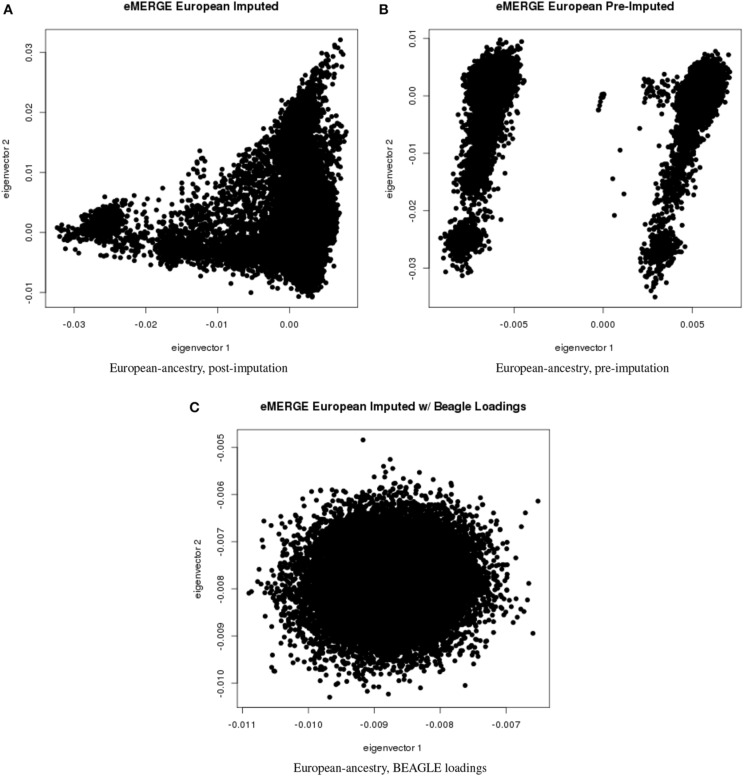
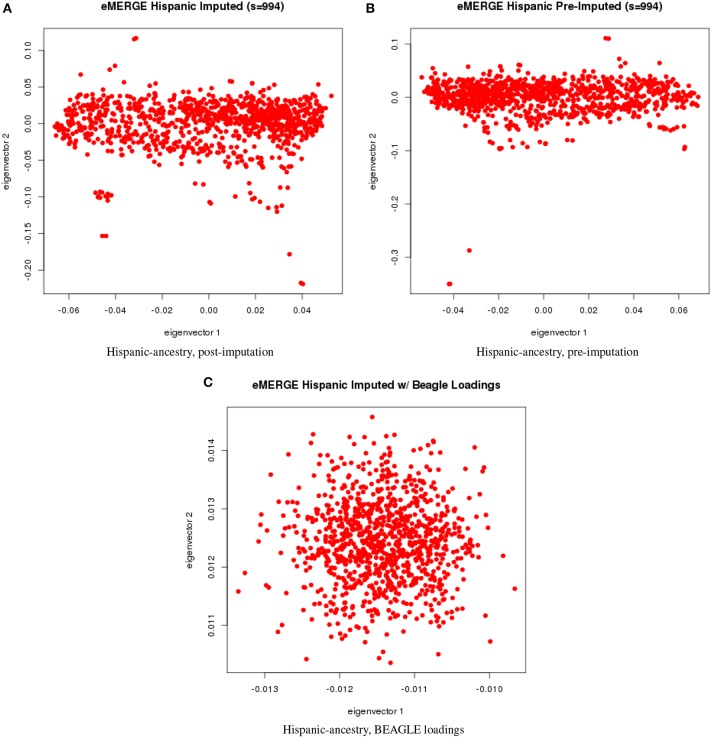
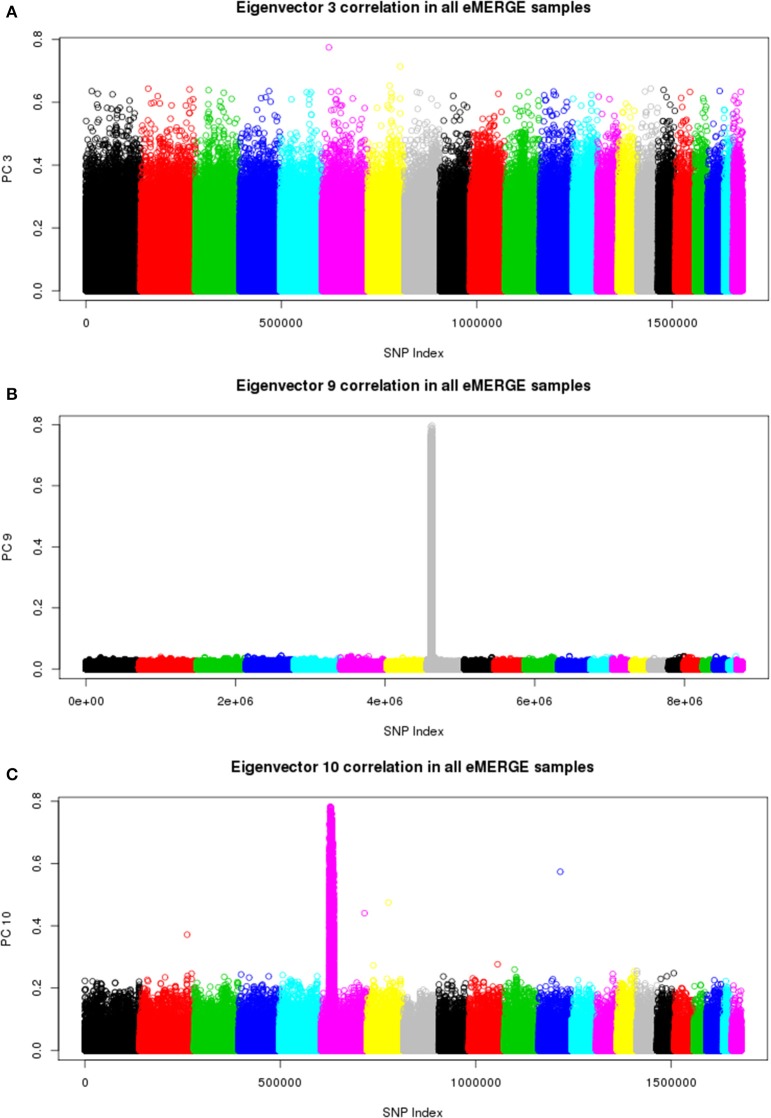
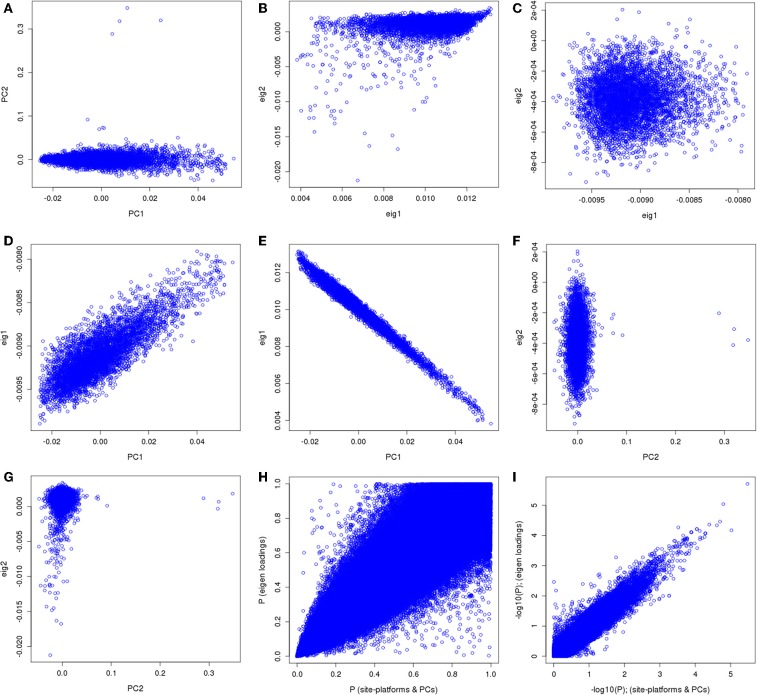
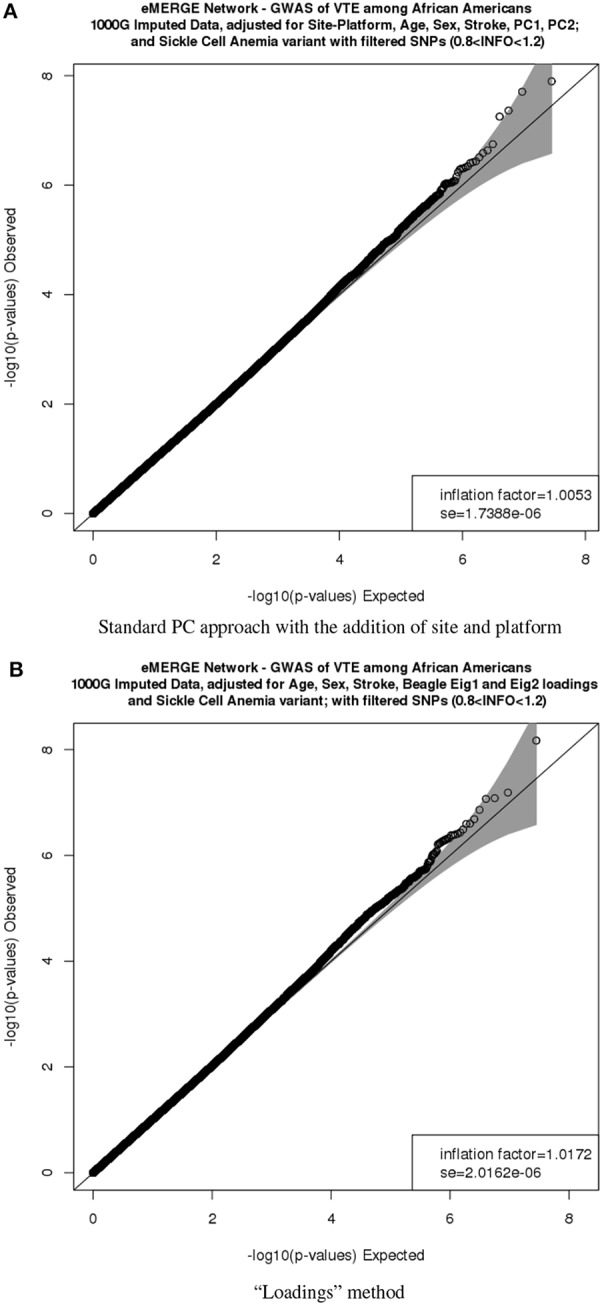
Combining samples across multiple cohorts in large-scale scientific research programs is often required to achieve the necessary power for genome-wide association studies. Controlling for genomic ancestry through principal component analysis (PCA) to address the effect of population stratification is a common practice. In addition to local genomic variation, such as copy number variation and inversions, other factors directly related to combining multiple studies, such as platform and site recruitment bias, can drive the correlation patterns in PCA. In this report, we describe the combination and analysis of multi-ethnic cohort with biobanks linked to electronic health records for large-scale genomic association discovery analyses. First, we outline the observed site and platform bias, in addition to ancestry differences. Second, we outline a general protocol for selecting variants for input into the subject variance-covariance matrix, the conventional PCA approach. Finally, we introduce an alternative approach to PCA by deriving components from subject loadings calculated from a reference sample. This alternative approach of generating principal components controlled for site and platform bias, in addition to ancestry differences, has the advantage of fewer covariates and degrees of freedom.
Keywords: ancestry; biobank; genetic association study; loadings; principal component analysis.
Figures
References
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources