

Dynalign II: common secondary structure prediction for RNA homologs with domain insertions
- PMID: 25416799
- PMCID: PMC4267632
- DOI: 10.1093/nar/gku1172
Dynalign II: common secondary structure prediction for RNA homologs with domain insertions
Abstract
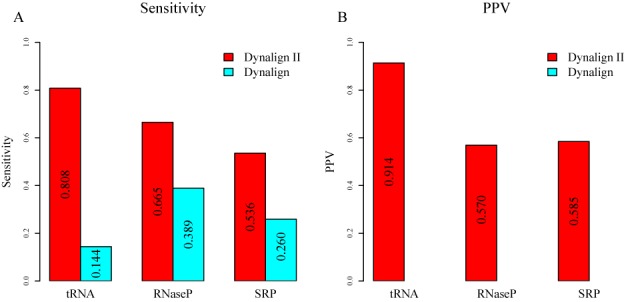
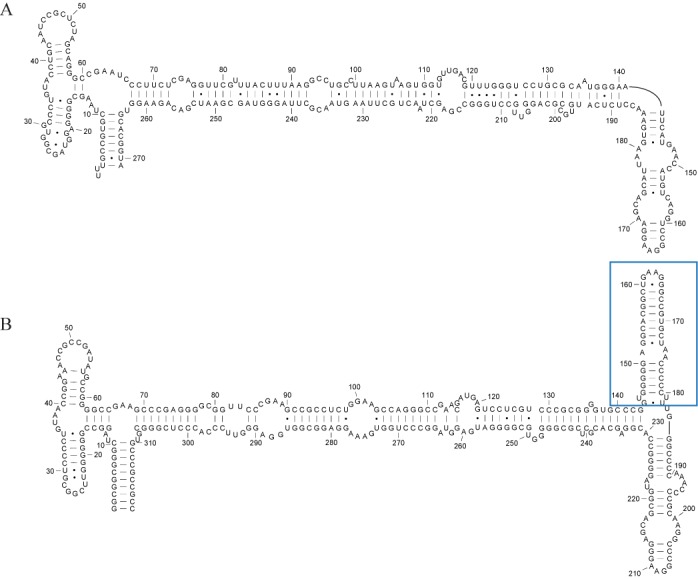
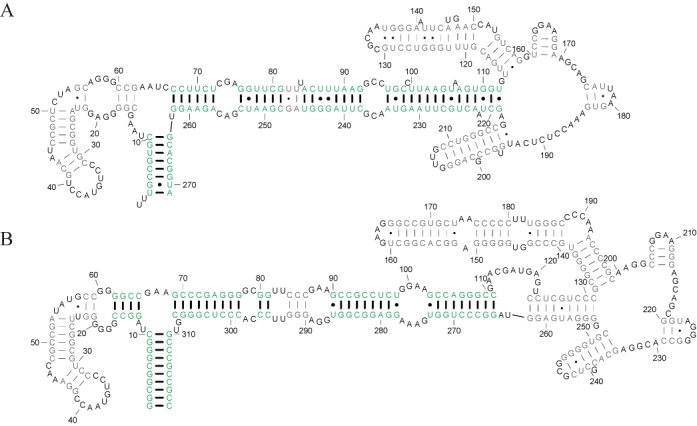
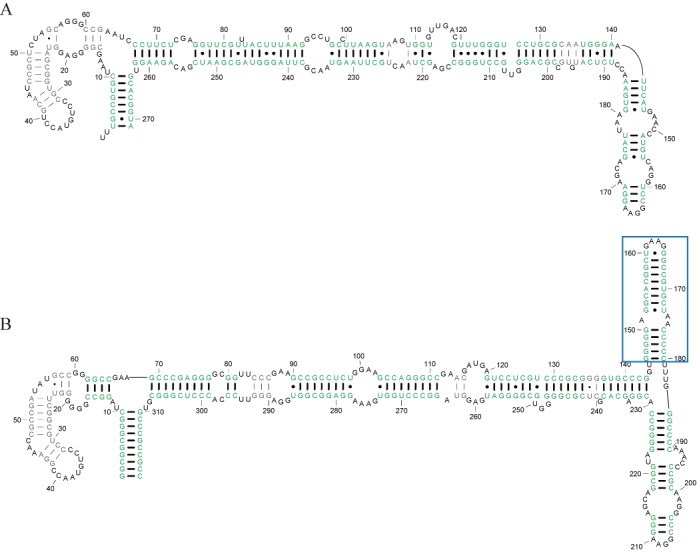
Homologous non-coding RNAs frequently exhibit domain insertions, where a branch of secondary structure is inserted in a sequence with respect to its homologs. Dynamic programming algorithms for common secondary structure prediction of multiple RNA homologs, however, do not account for these domain insertions. This paper introduces a novel dynamic programming algorithm methodology that explicitly accounts for the possibility of inserted domains when predicting common RNA secondary structures. The algorithm is implemented as Dynalign II, an update to the Dynalign software package for predicting the common secondary structure of two RNA homologs. This update is accomplished with negligible increase in computational cost. Benchmarks on ncRNA families with domain insertions validate the method. Over base pairs occurring in inserted domains, Dynalign II improves accuracy over Dynalign, attaining 80.8% sensitivity (compared with 14.4% for Dynalign) and 91.4% positive predictive value (PPV) for tRNA; 66.5% sensitivity (compared with 38.9% for Dynalign) and 57.0% PPV for RNase P RNA; and 50.1% sensitivity (compared with 24.3% for Dynalign) and 58.5% PPV for SRP RNA. Compared with Dynalign, Dynalign II also exhibits statistically significant improvements in overall sensitivity and PPV. Dynalign II is available as a component of RNAstructure, which can be downloaded from http://rna.urmc.rochester.edu/RNAstructure.html.
Figures

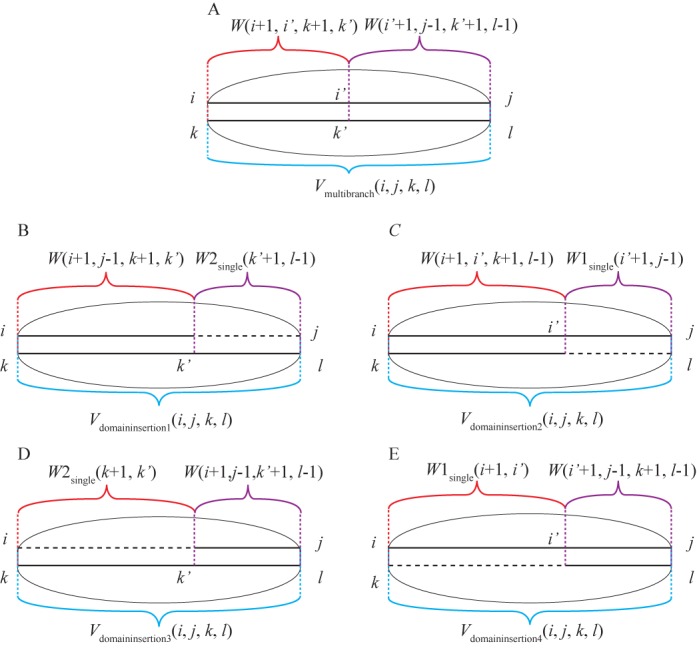
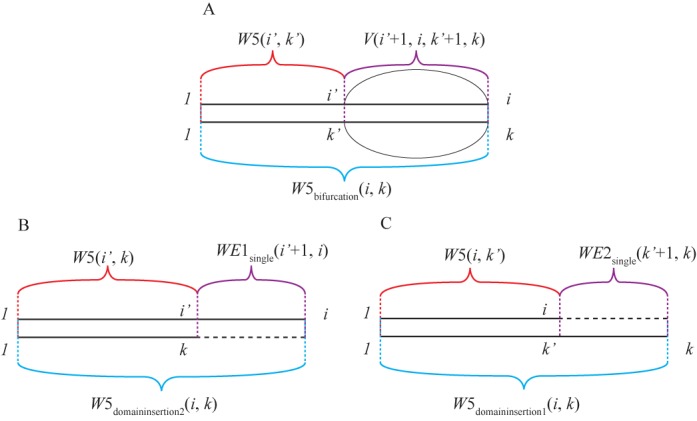
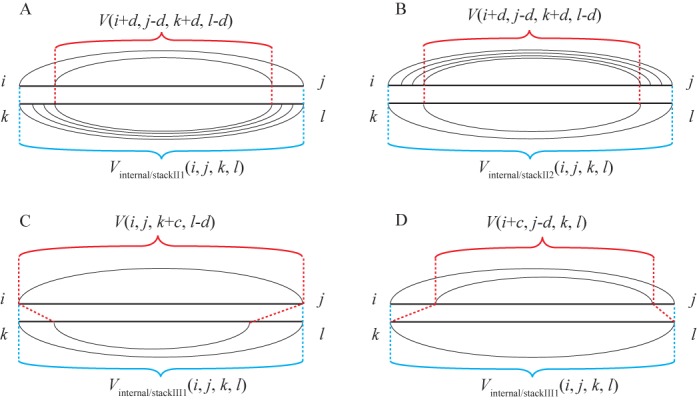
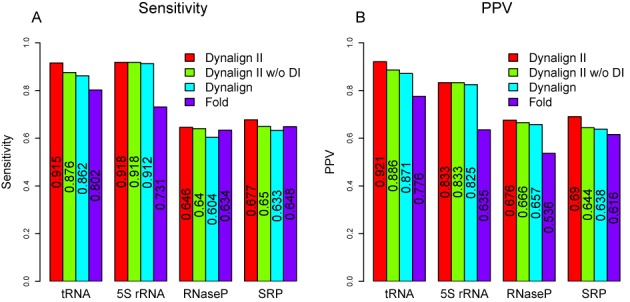
References
-
- Eddy S.R. Non-coding RNA genes and the modern RNA world. Nat. Rev. Genet. 2001;2:919–929. - PubMed
-
- Doudna J.A., Cech T.R. The chemical repertoire of natural ribozymes. Nature. 2002;418:222–228. - PubMed
-
- Tucker B.J., Breaker R.R. Riboswitches as versatile gene control elements. Curr. Opin. Struct. Biol. 2005;15:342–348. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
