

Structural mechanisms of RNA recognition: sequence-specific and non-specific RNA-binding proteins and the Cas9-RNA-DNA complex
- PMID: 25432705
- PMCID: PMC11113803
- DOI: 10.1007/s00018-014-1779-9
Structural mechanisms of RNA recognition: sequence-specific and non-specific RNA-binding proteins and the Cas9-RNA-DNA complex
Abstract
RNA-binding proteins play crucial roles in RNA processing and function as regulators of gene expression. Recent studies have defined the structural basis for RNA recognition by diverse RNA-binding motifs. While many RNA-binding proteins recognize RNA sequence non-specifically by associating with 5' or 3' RNA ends, sequence-specific recognition by RNA-binding proteins is typically achieved by combining multiple modular domains to form complex binding surfaces. In this review, we present examples of structures from different classes of RNA-binding proteins, identify the mechanisms utilized by them to target specific RNAs, and describe structural principles of how protein-protein interactions affect RNA recognition specificity. We also highlight the structural mechanism of sequence-dependent and -independent interactions in the Cas9-RNA-DNA complex.
Figures
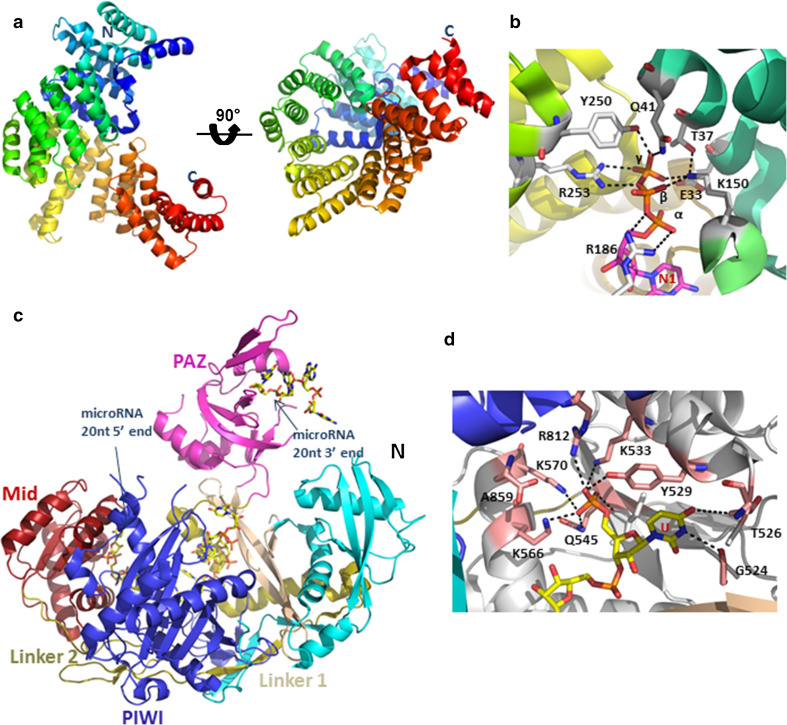
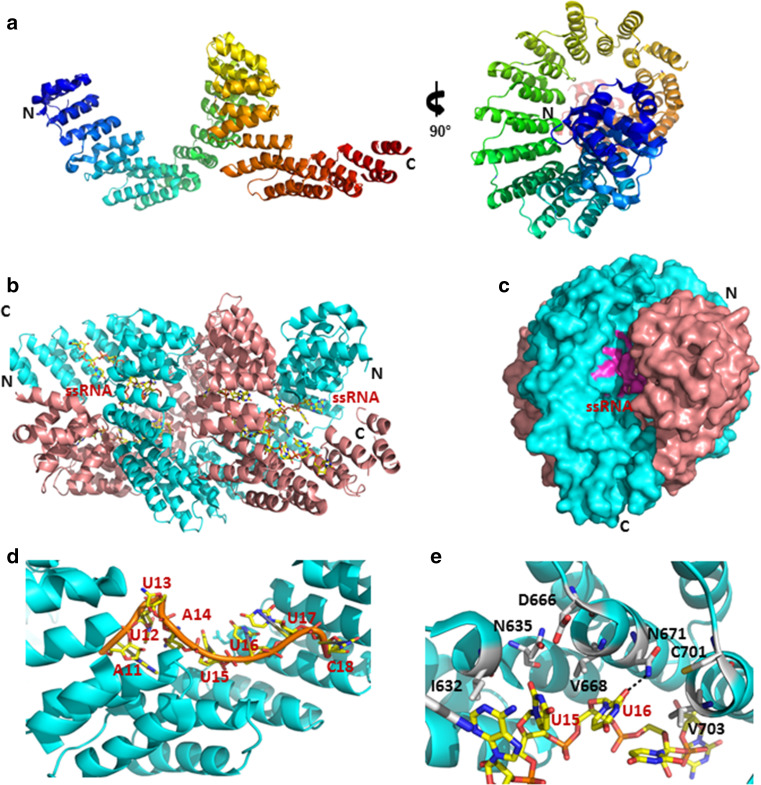
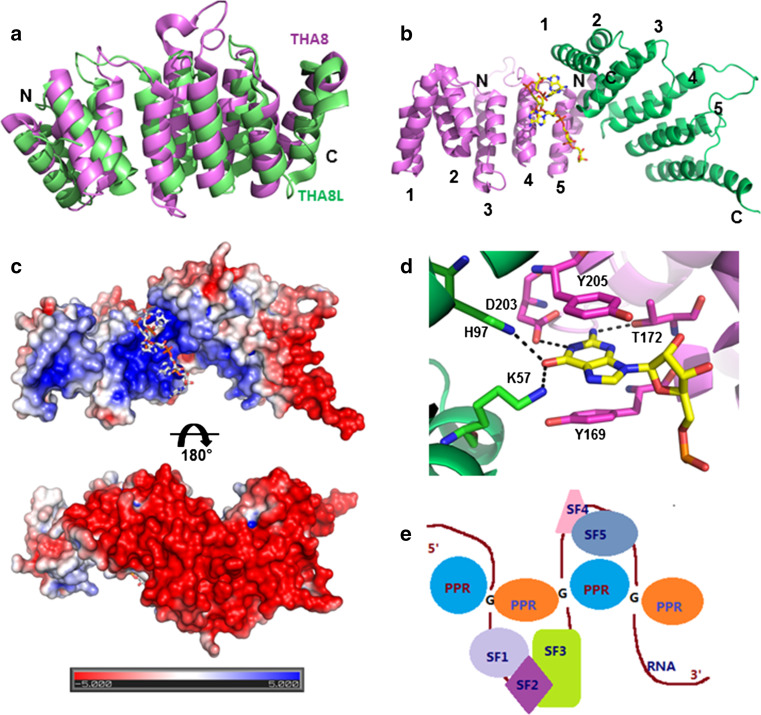
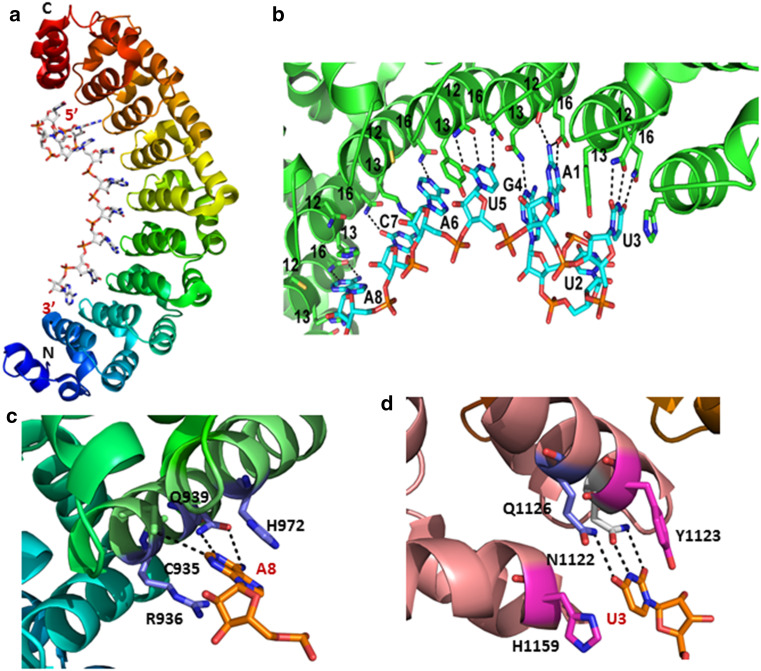
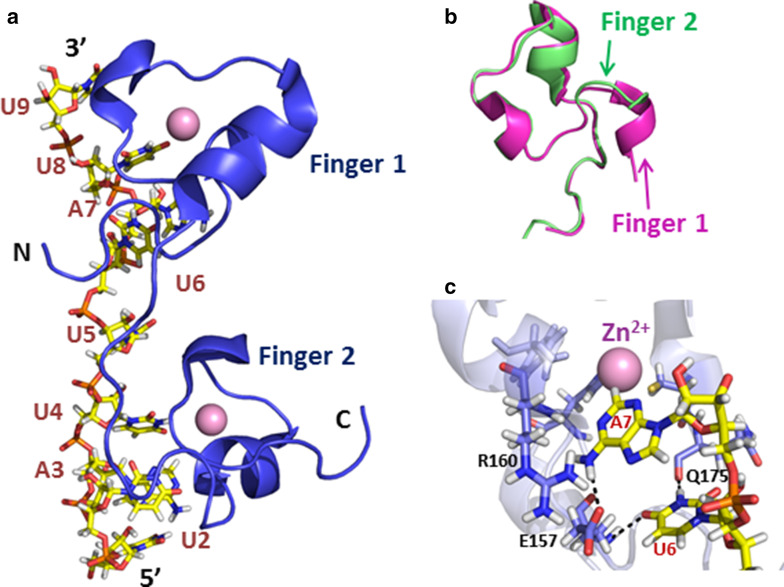
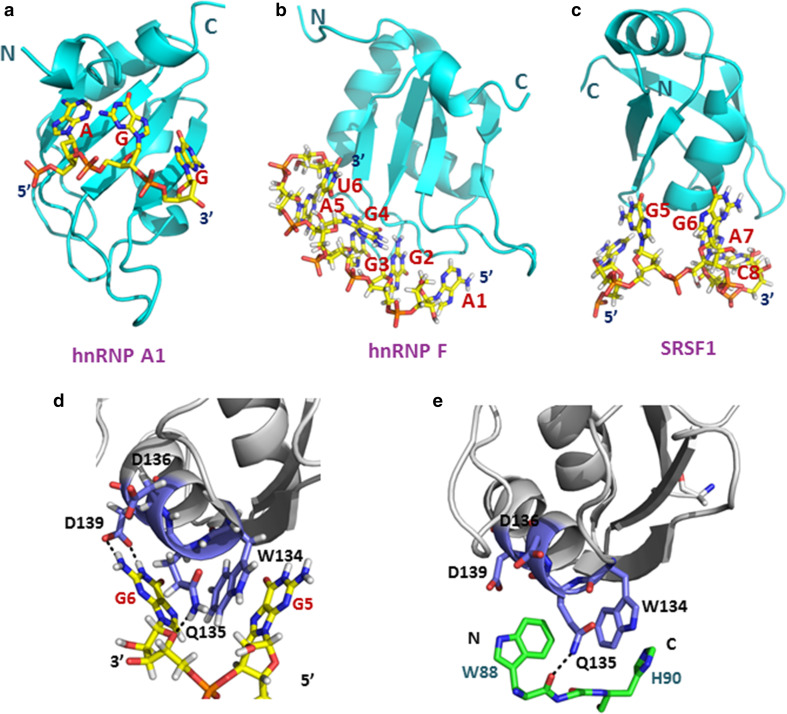
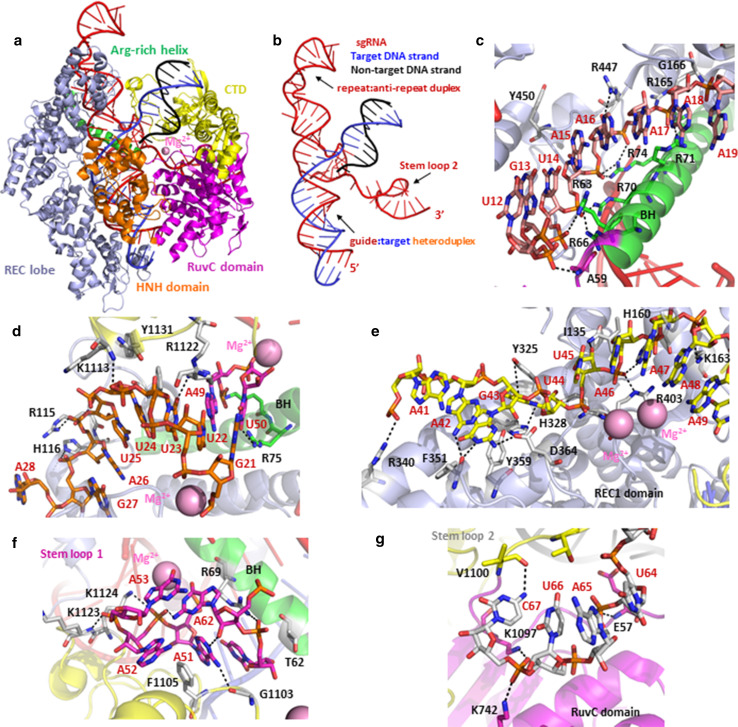
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
