

ECOD: an evolutionary classification of protein domains
- PMID: 25474468
- PMCID: PMC4256011
- DOI: 10.1371/journal.pcbi.1003926
ECOD: an evolutionary classification of protein domains
Abstract
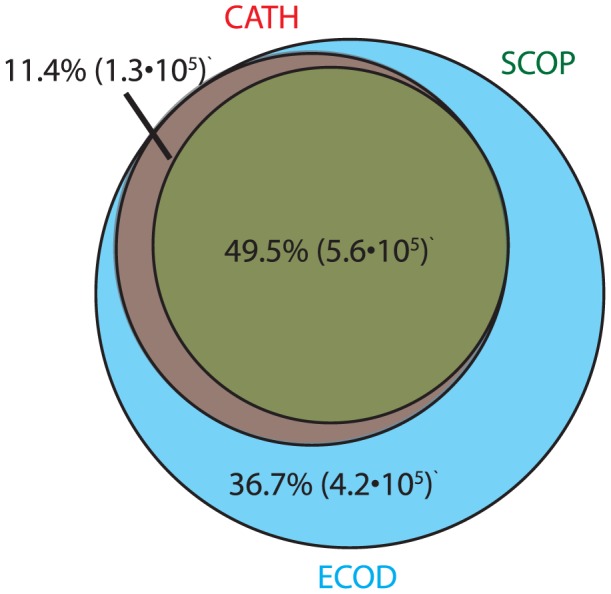
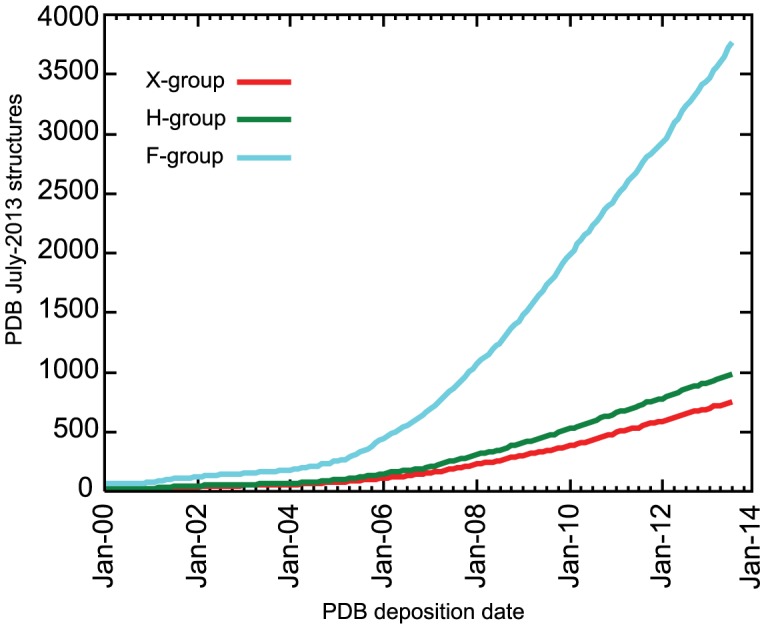
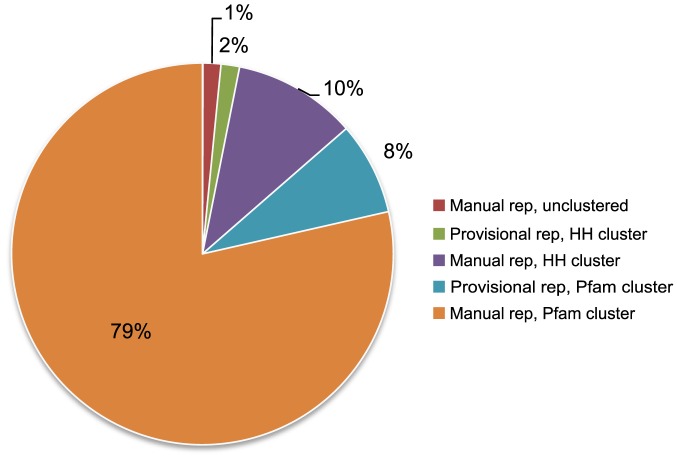
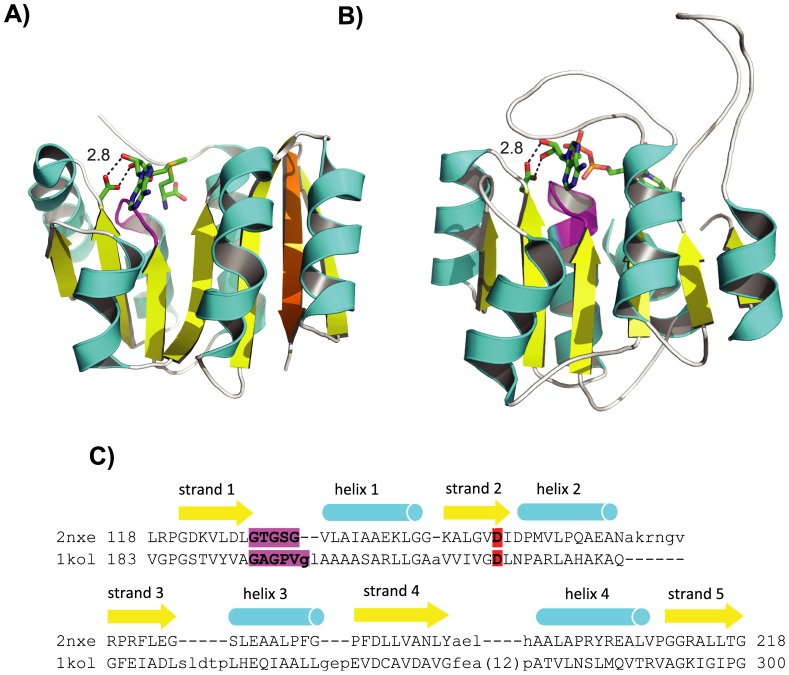
Understanding the evolution of a protein, including both close and distant relationships, often reveals insight into its structure and function. Fast and easy access to such up-to-date information facilitates research. We have developed a hierarchical evolutionary classification of all proteins with experimentally determined spatial structures, and presented it as an interactive and updatable online database. ECOD (Evolutionary Classification of protein Domains) is distinct from other structural classifications in that it groups domains primarily by evolutionary relationships (homology), rather than topology (or "fold"). This distinction highlights cases of homology between domains of differing topology to aid in understanding of protein structure evolution. ECOD uniquely emphasizes distantly related homologs that are difficult to detect, and thus catalogs the largest number of evolutionary links among structural domain classifications. Placing distant homologs together underscores the ancestral similarities of these proteins and draws attention to the most important regions of sequence and structure, as well as conserved functional sites. ECOD also recognizes closer sequence-based relationships between protein domains. Currently, approximately 100,000 protein structures are classified in ECOD into 9,000 sequence families clustered into close to 2,000 evolutionary groups. The classification is assisted by an automated pipeline that quickly and consistently classifies weekly releases of PDB structures and allows for continual updates. This synchronization with PDB uniquely distinguishes ECOD among all protein classifications. Finally, we present several case studies of homologous proteins not recorded in other classifications, illustrating the potential of how ECOD can be used to further biological and evolutionary studies.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
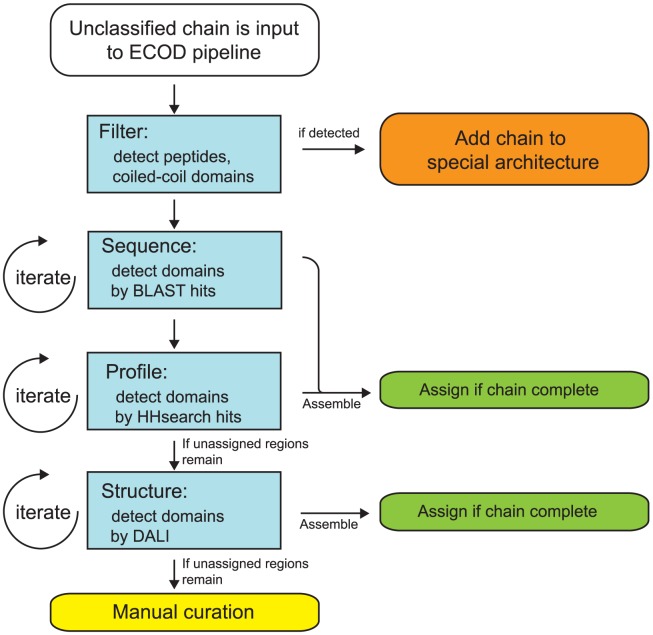
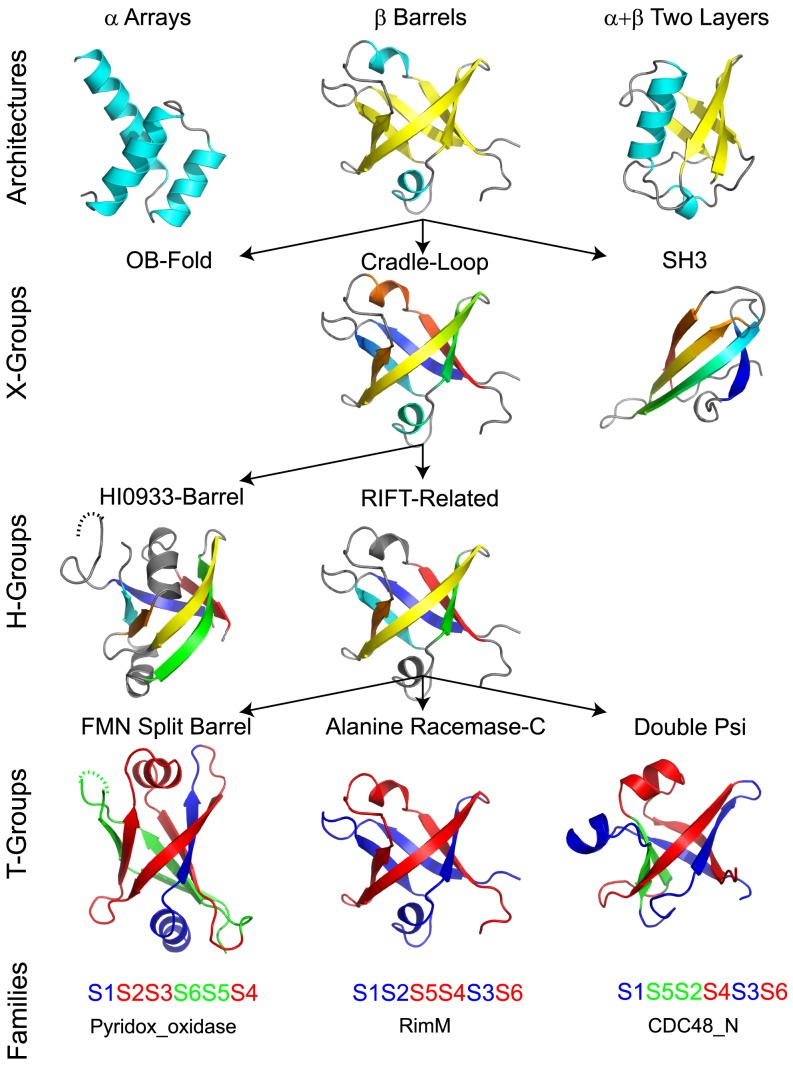
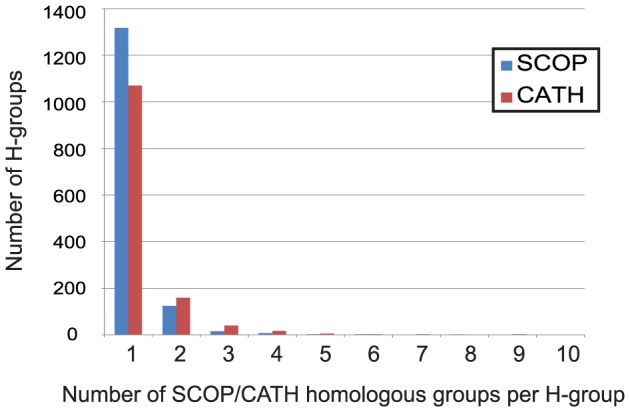
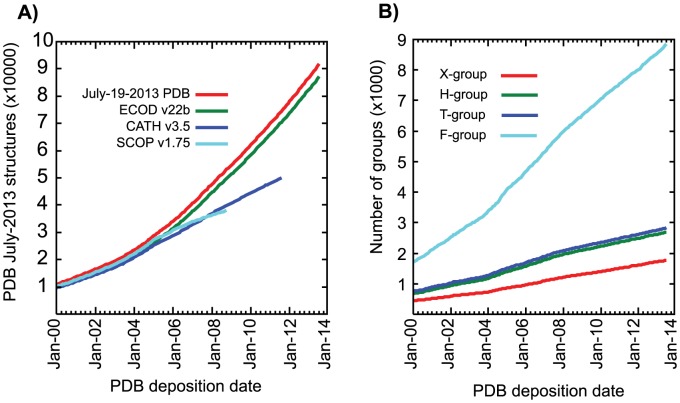
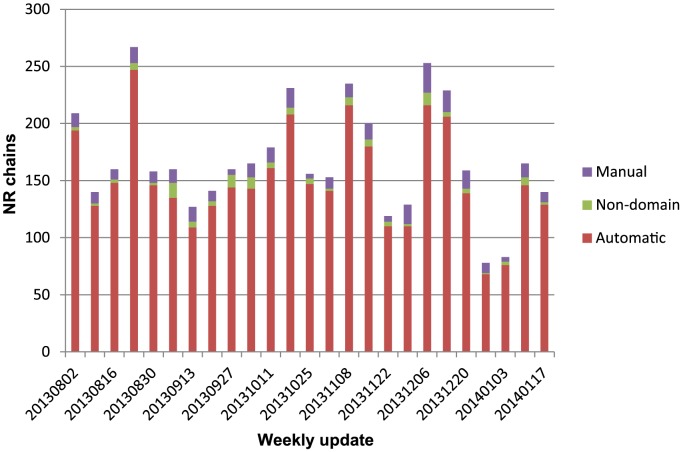
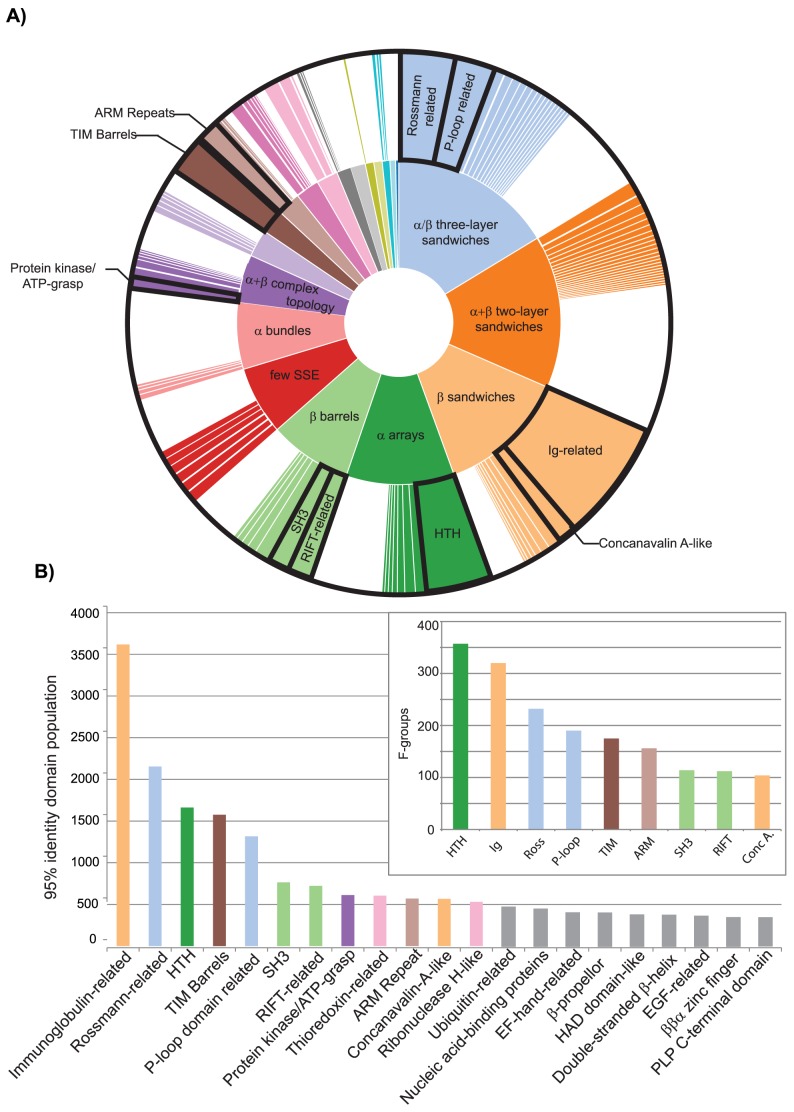
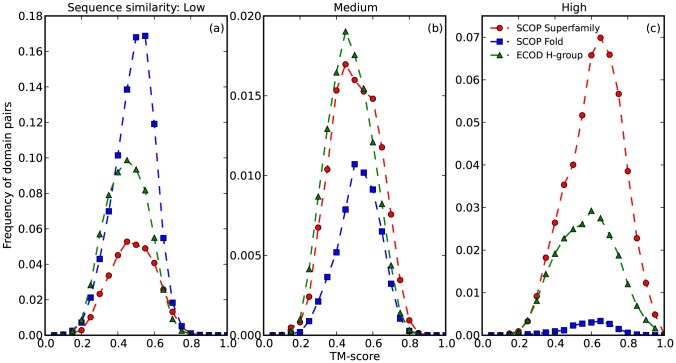
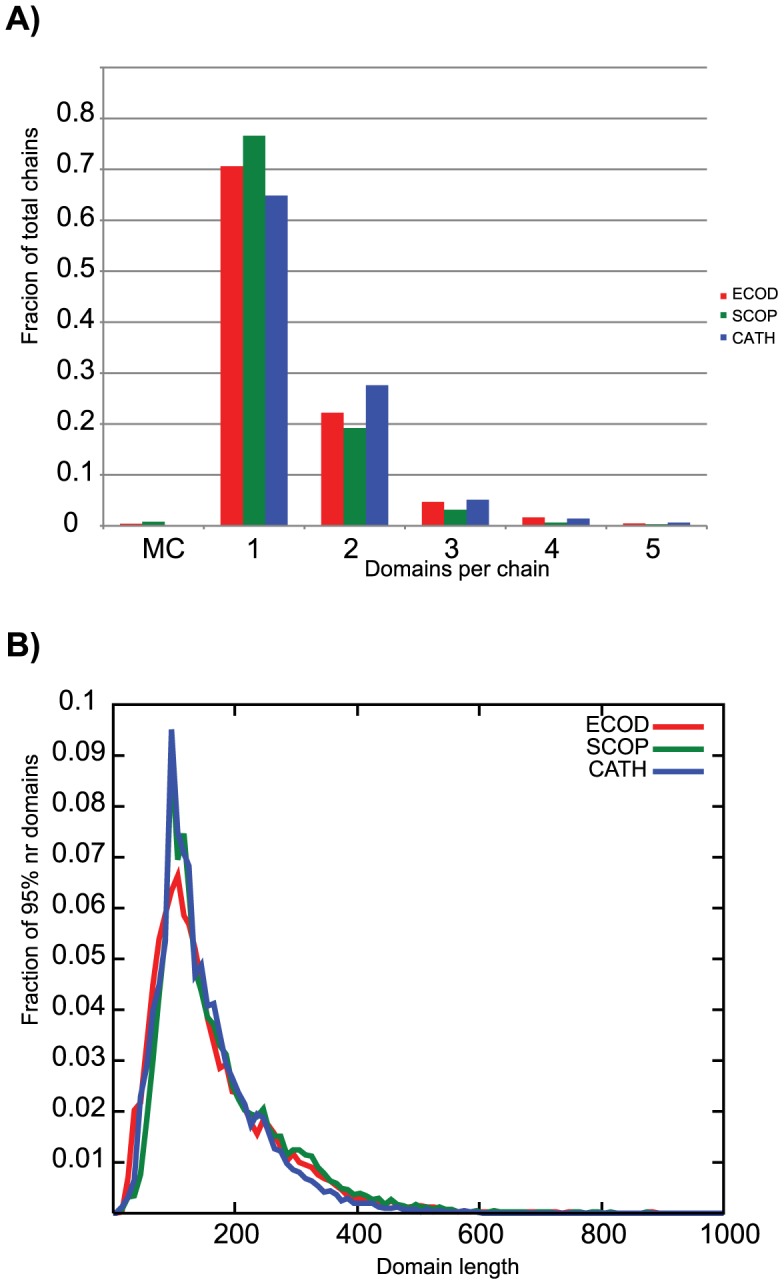
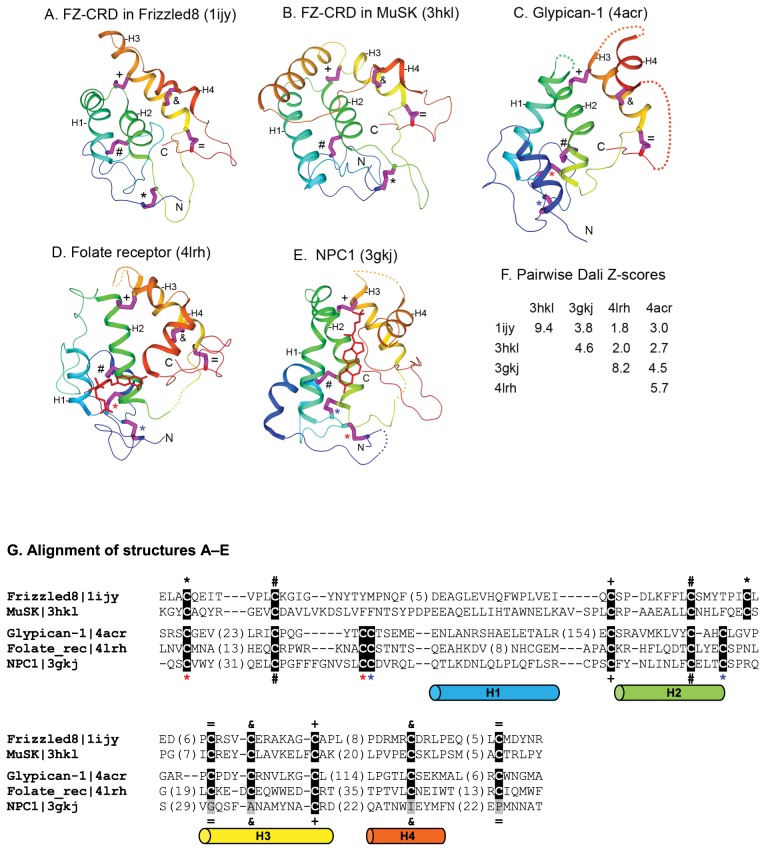
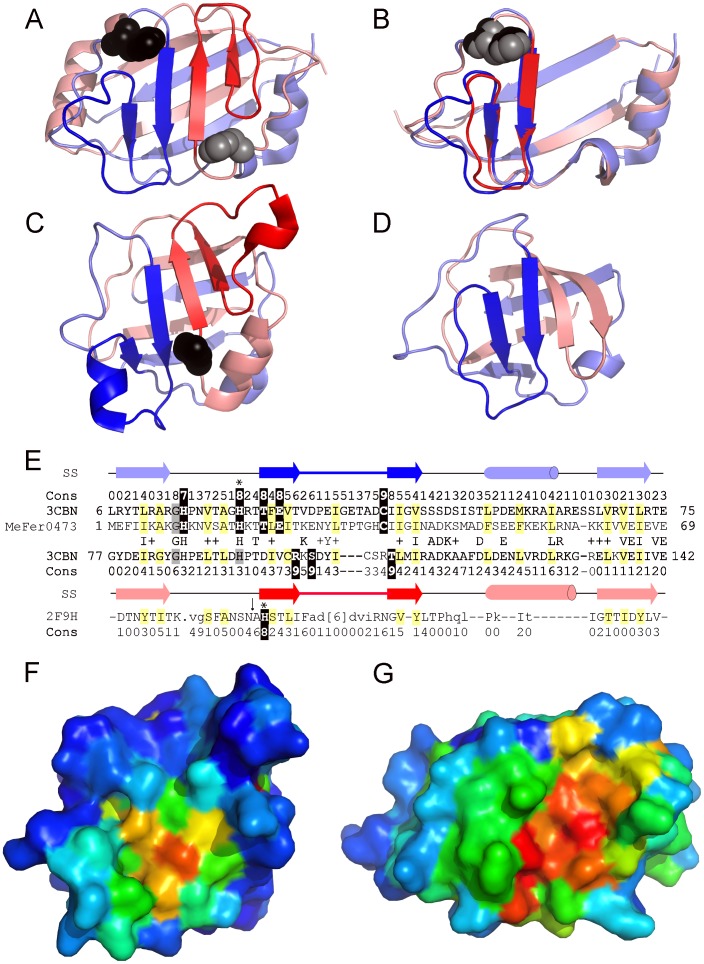
References
-
- Holm L, Sander C (1996) Mapping the protein universe. Science 273: 595–603. - PubMed
-
- Murzin AG, Brenner SE, Hubbard T, Chothia C (1995) SCOP: a structural classification of proteins database for the investigation of sequences and structures. J Mol Biol 247: 536–540. - PubMed
-
- Orengo CA, Michie AD, Jones S, Jones DT, Swindells MB, et al. (1997) CATH–a hierarchic classification of protein domain structures. Structure 5: 1093–1108. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
