

Structured Correspondence Topic Models for Mining Captioned Figures in Biological Literature
- PMID: 25485170
- PMCID: PMC4256960
- DOI: 10.1145/1557019.1557031
Structured Correspondence Topic Models for Mining Captioned Figures in Biological Literature
Abstract
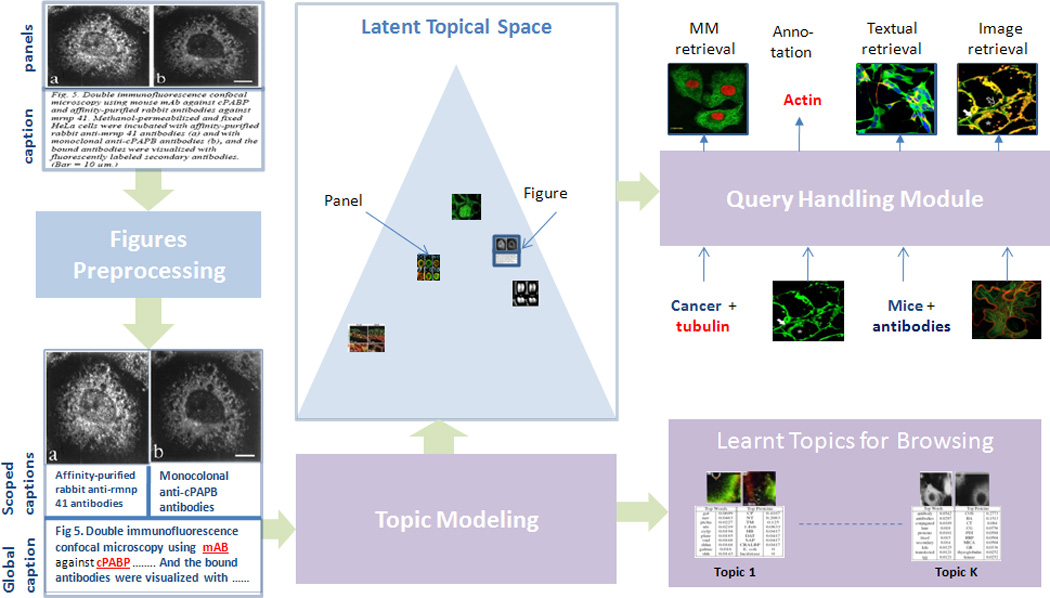
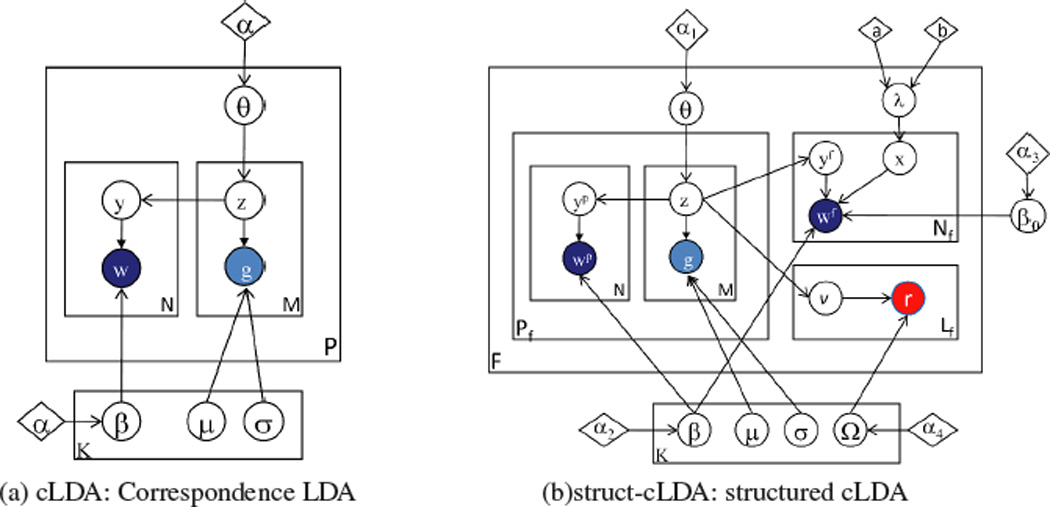
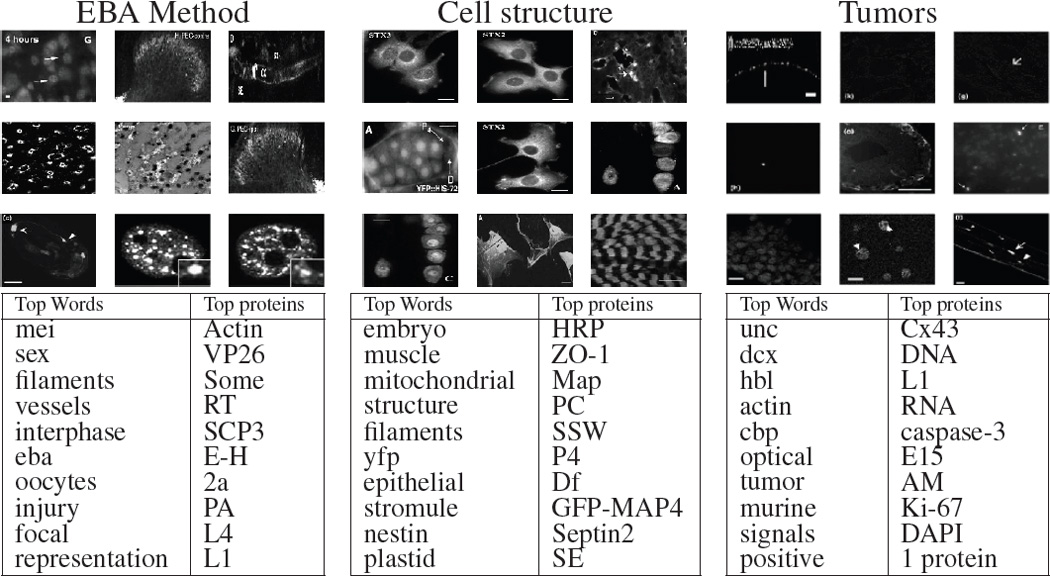
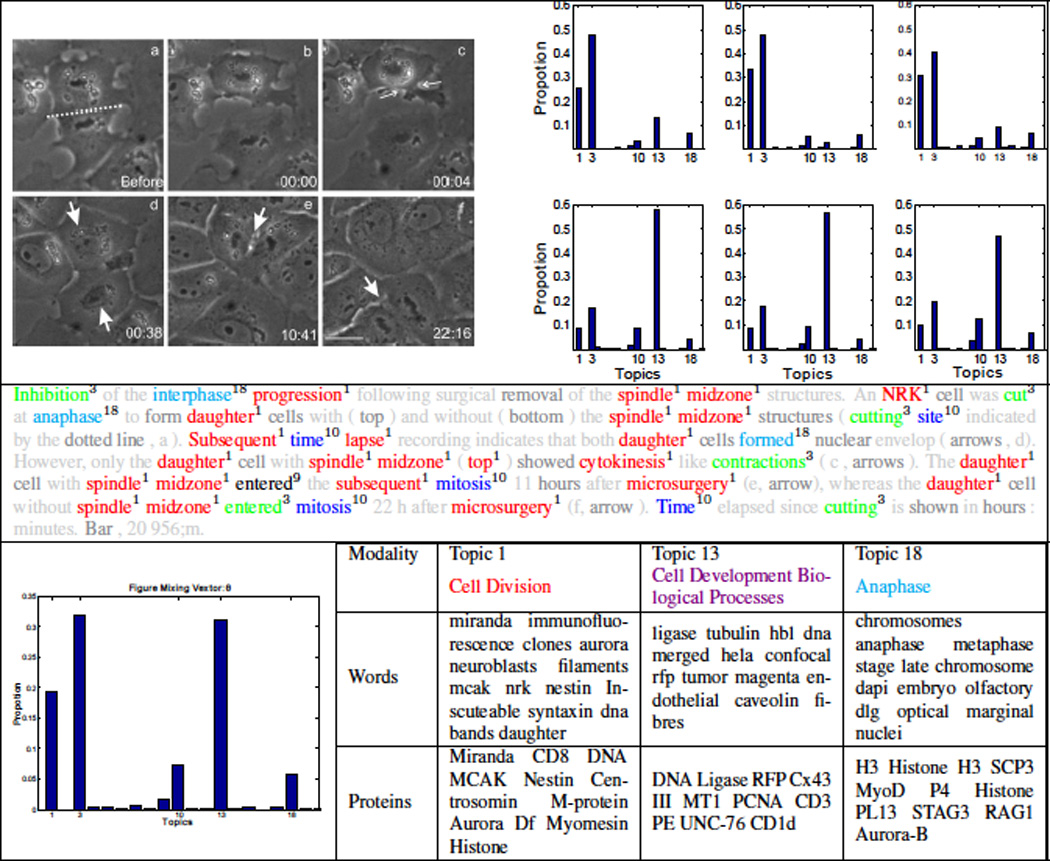
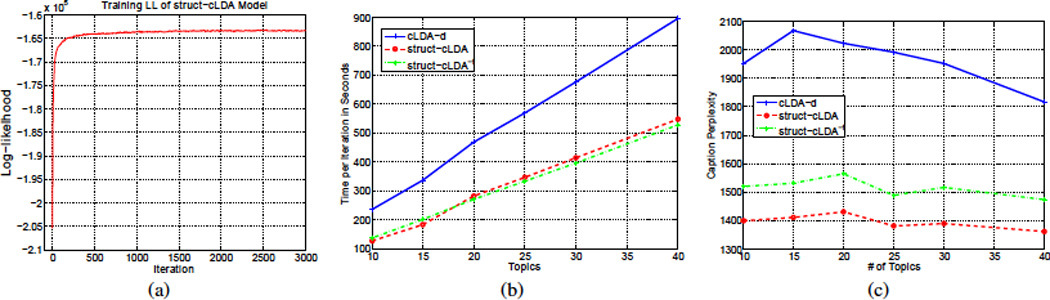
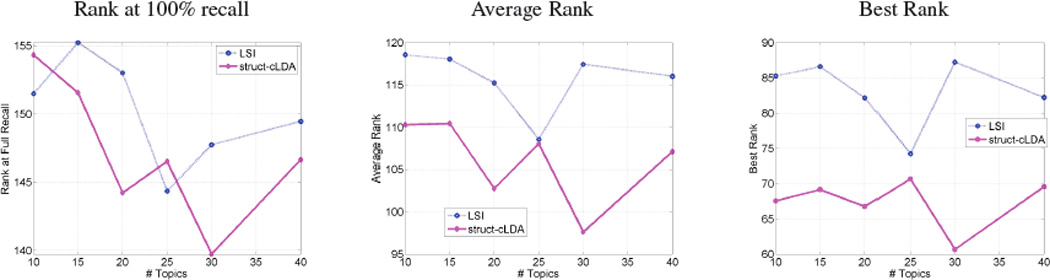
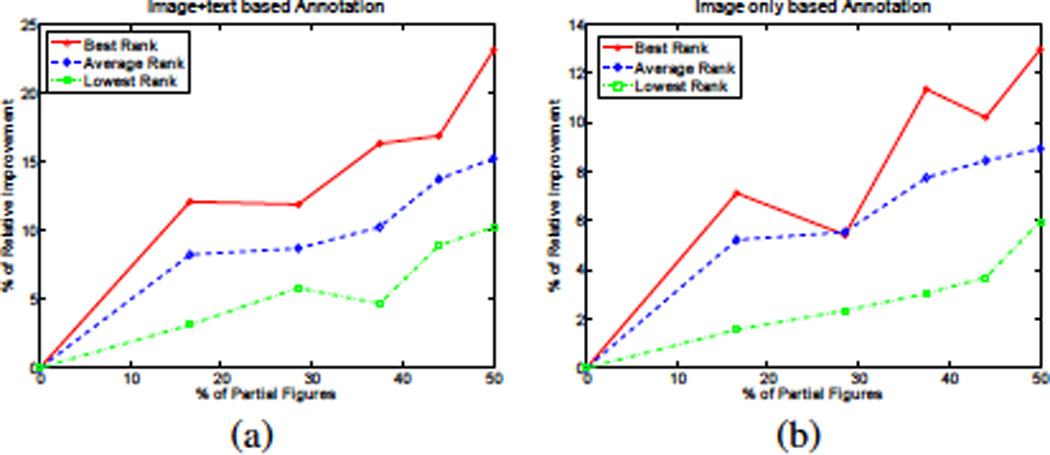
A major source of information (often the most crucial and informative part) in scholarly articles from scientific journals, proceedings and books are the figures that directly provide images and other graphical illustrations of key experimental results and other scientific contents. In biological articles, a typical figure often comprises multiple panels, accompanied by either scoped or global captioned text. Moreover, the text in the caption contains important semantic entities such as protein names, gene ontology, tissues labels, etc., relevant to the images in the figure. Due to the avalanche of biological literature in recent years, and increasing popularity of various bio-imaging techniques, automatic retrieval and summarization of biological information from literature figures has emerged as a major unsolved challenge in computational knowledge extraction and management in the life science. We present a new structured probabilistic topic model built on a realistic figure generation scheme to model the structurally annotated biological figures, and we derive an efficient inference algorithm based on collapsed Gibbs sampling for information retrieval and visualization. The resulting program constitutes one of the key IR engines in our SLIF system that has recently entered the final round (4 out 70 competing systems) of the Elsevier Grand Challenge on Knowledge Enhancement in the Life Science. Here we present various evaluations on a number of data mining tasks to illustrate our method.
Keywords: Algorithms; Experimentation.
Figures

References
-
- Barnard K, Duygulu P, de Freitas N, Forsyth D, Blei D, Jordan M. Matching words and pictures. JMLR. 2003;3:1107–1135.
-
- Blei D, Jordan M. Modeling annotated data. ACM SIGIR. 2003
-
- Chemudugunta C, Smyth P, Steyvers M. Modeling general and specific aspects of documents with a probabilistic topic model. NIPS. 2006
-
- Cohen WW, Wang R, Murphy RF. Understanding captions in biological publications. ACM KDD. 2005
Grants and funding
LinkOut - more resources
Full Text Sources