

A bio-inspired feature extraction for robust speech recognition
- PMID: 25485194
- PMCID: PMC4230714
- DOI: 10.1186/2193-1801-3-651
A bio-inspired feature extraction for robust speech recognition
Abstract
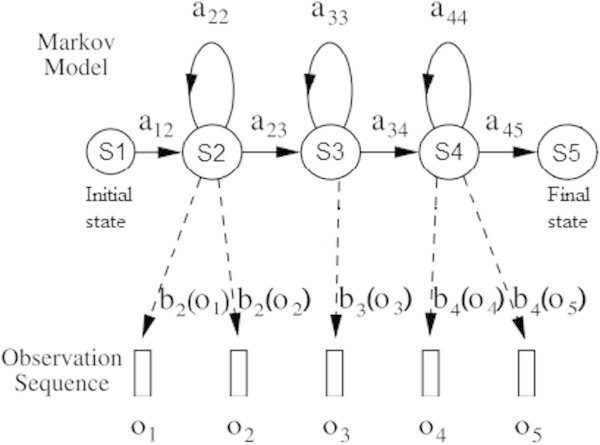
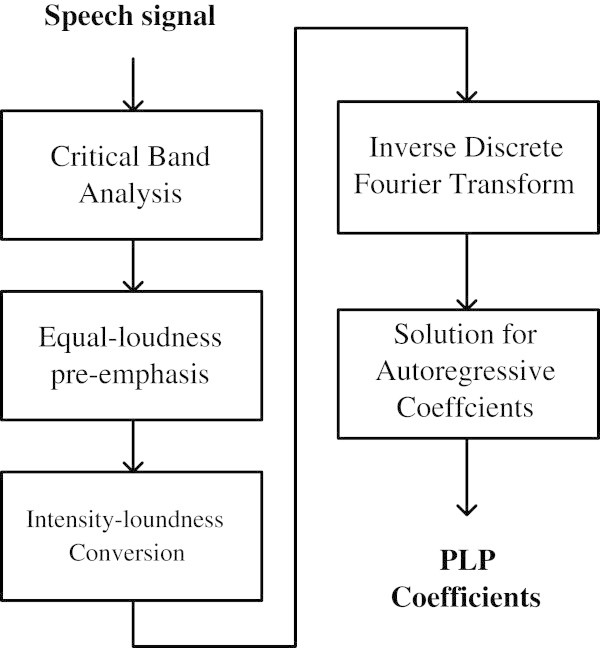
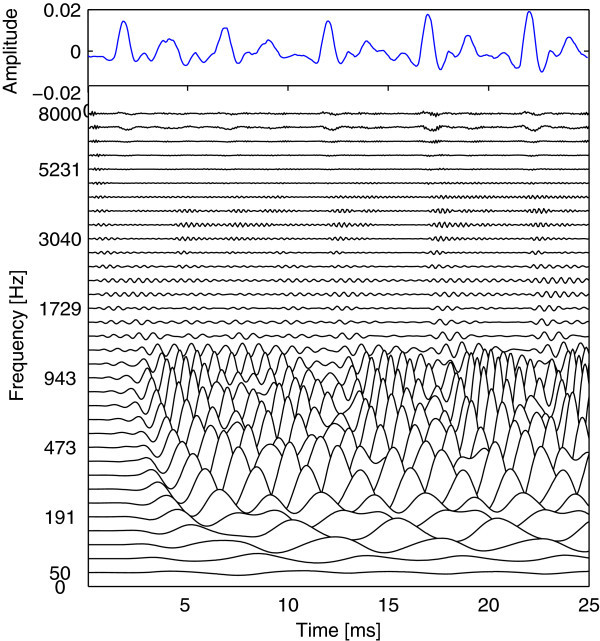
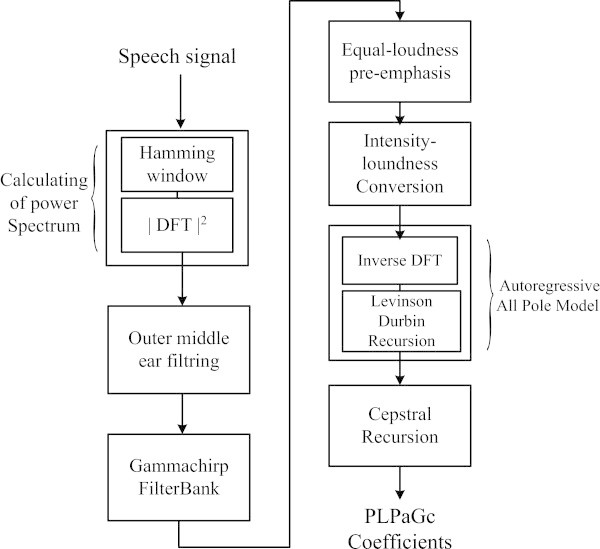
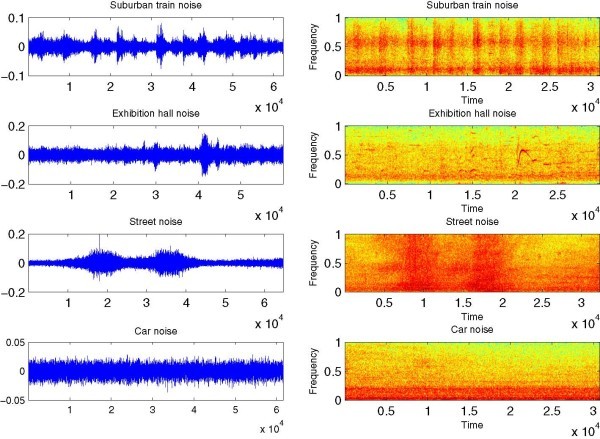
In this paper, a feature extraction method for robust speech recognition in noisy environments is proposed. The proposed method is motivated by a biologically inspired auditory model which simulates the outer/middle ear filtering by a low-pass filter and the spectral behaviour of the cochlea by the Gammachirp auditory filterbank (GcFB). The speech recognition performance of our method is tested on speech signals corrupted by real-world noises. The evaluation results show that the proposed method gives better recognition rates compared to the classic techniques such as Perceptual Linear Prediction (PLP), Linear Predictive Coding (LPC), Linear Prediction Cepstral coefficients (LPCC) and Mel Frequency Cepstral Coefficients (MFCC). The used recognition system is based on the Hidden Markov Models with continuous Gaussian Mixture densities (HMM-GM).
Keywords: Auditory filter model; Feature extraction; Hidden Markov Models; Noisy speech recognition.
Figures

Similar articles
-
Cochlea-inspired speech recognition interface.Med Biol Eng Comput. 2019 Jun;57(6):1393-1403. doi: 10.1007/s11517-019-01963-6. Epub 2019 Mar 4. Med Biol Eng Comput. 2019. PMID: 30830542
-
[Research on biometric method of heart sound signal based on GMM].Zhongguo Yi Liao Qi Xie Za Zhi. 2013 Mar;37(2):92-5, 99. Zhongguo Yi Liao Qi Xie Za Zhi. 2013. PMID: 23777060 Chinese.
-
A Robust Speaker Identification System Using the Responses from a Model of the Auditory Periphery.PLoS One. 2016 Jul 8;11(7):e0158520. doi: 10.1371/journal.pone.0158520. eCollection 2016. PLoS One. 2016. PMID: 27392046 Free PMC article.
-
Statistical modeling of speech Poincaré sections in combination of frequency analysis to improve speech recognition performance.Chaos. 2010 Sep;20(3):033106. doi: 10.1063/1.3463722. Chaos. 2010. PMID: 20887046
-
Exploiting independent filter bandwidth of human factor cepstral coefficients in automatic speech recognition.J Acoust Soc Am. 2004 Sep;116(3):1774-80. doi: 10.1121/1.1777872. J Acoust Soc Am. 2004. PMID: 15478444
References
-
- Beigi H. Fundamentals of Speaker Recognition. New York: Springer; 2011.
-
- Bleeck S, Ives T, Patterson RD. Aim-mat: the auditry image model in MATLAB. Acta Acustica United Ac. 2004;90(4):781–787.
-
- Davis SB, Mermelstein P. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Trans Acoust, Speech, Signal Processing. 1980;28(4):357–66. doi: 10.1109/TASSP.1980.1163420. - DOI
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
