

Automated Cough Assessment on a Mobile Platform
- PMID: 25506590
- PMCID: PMC4264627
- DOI: 10.1155/2014/951621
Automated Cough Assessment on a Mobile Platform
Abstract
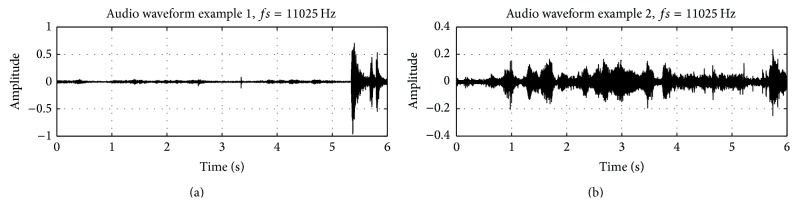
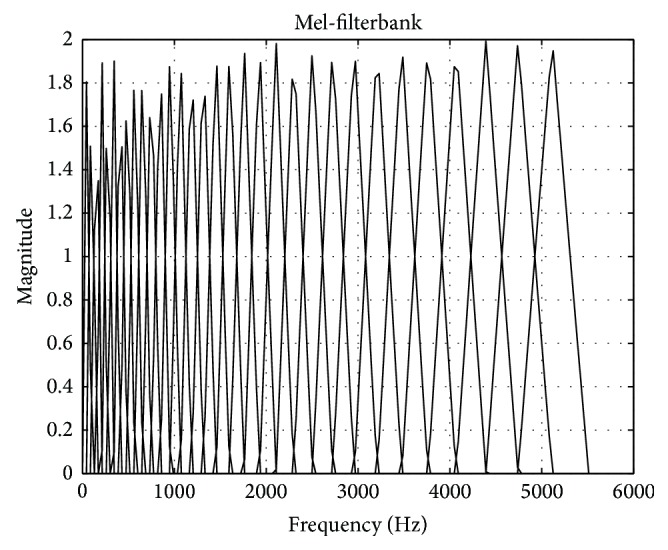
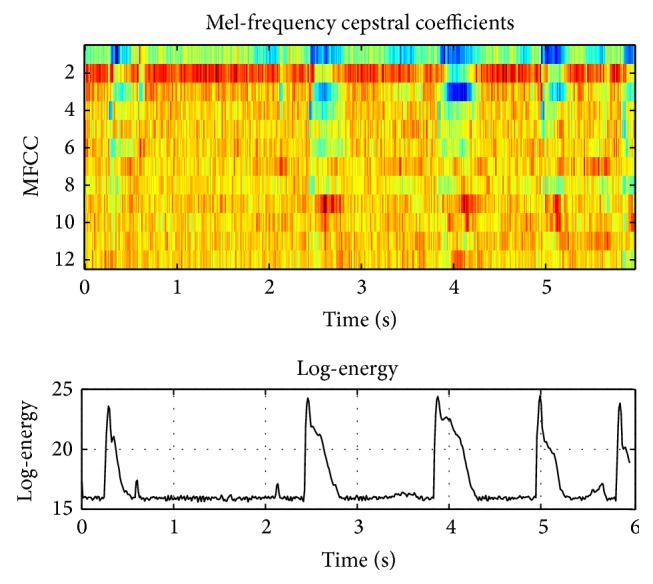
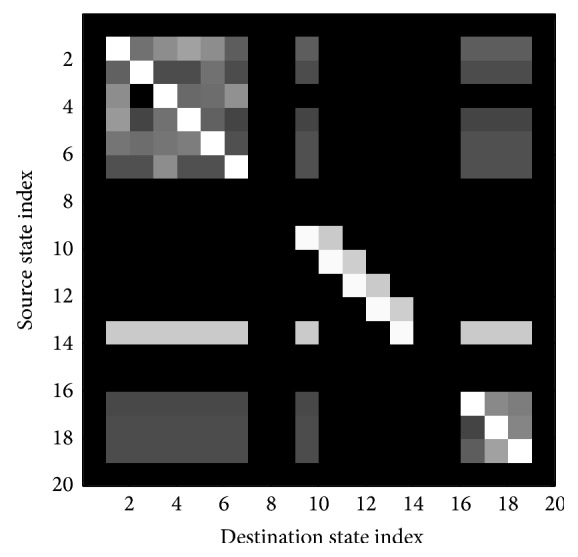
The development of an Automated System for Asthma Monitoring (ADAM) is described. This consists of a consumer electronics mobile platform running a custom application. The application acquires an audio signal from an external user-worn microphone connected to the device analog-to-digital converter (microphone input). This signal is processed to determine the presence or absence of cough sounds. Symptom tallies and raw audio waveforms are recorded and made easily accessible for later review by a healthcare provider. The symptom detection algorithm is based upon standard speech recognition and machine learning paradigms and consists of an audio feature extraction step followed by a Hidden Markov Model based Viterbi decoder that has been trained on a large database of audio examples from a variety of subjects. Multiple Hidden Markov Model topologies and orders are studied. Performance of the recognizer is presented in terms of the sensitivity and the rate of false alarm as determined in a cross-validation test.
Figures

Similar articles
-
The development of an automated device for asthma monitoring for adolescents: methodologic approach and user acceptability.JMIR Mhealth Uhealth. 2014 Jun 19;2(2):e27. doi: 10.2196/mhealth.3118. JMIR Mhealth Uhealth. 2014. PMID: 25100184 Free PMC article.
-
Detection of cough signals in continuous audio recordings using hidden Markov models.IEEE Trans Biomed Eng. 2006 Jun;53(6):1078-83. doi: 10.1109/TBME.2006.873548. IEEE Trans Biomed Eng. 2006. PMID: 16761835 Clinical Trial.
-
Evaluating the Validity of an Automated Device for Asthma Monitoring for Adolescents: Correlational Design.J Med Internet Res. 2015 Oct 16;17(10):e234. doi: 10.2196/jmir.4975. J Med Internet Res. 2015. PMID: 26475634 Free PMC article.
-
The present and future of cough counting tools.J Thorac Dis. 2020 Sep;12(9):5207-5223. doi: 10.21037/jtd-2020-icc-003. J Thorac Dis. 2020. PMID: 33145097 Free PMC article. Review.
-
Hidden Markov models for speech and signal recognition.Electroencephalogr Clin Neurophysiol Suppl. 1996;45:137-52. Electroencephalogr Clin Neurophysiol Suppl. 1996. PMID: 8930521 Review.
Cited by
-
Mobile Applications for Patient-centered Care Coordination: A Review of Human Factors Methods Applied to their Design, Development, and Evaluation.Yearb Med Inform. 2015 Aug 13;10(1):47-54. doi: 10.15265/IY-2015-011. Yearb Med Inform. 2015. PMID: 26293851 Free PMC article. Review.
-
Protocol for studying cough frequency in people with pulmonary tuberculosis.BMJ Open. 2016 Apr 22;6(4):e010365. doi: 10.1136/bmjopen-2015-010365. BMJ Open. 2016. PMID: 27105713 Free PMC article.
-
Asthma Symptom Self-Monitoring Methods for Children and Adolescents: Present and Future.Children (Basel). 2025 Jul 29;12(8):997. doi: 10.3390/children12080997. Children (Basel). 2025. PMID: 40868448 Free PMC article. Review.
-
Side-Channel Sensing: Exploiting Side-Channels to Extract Information for Medical Diagnostics and Monitoring.IEEE J Transl Eng Health Med. 2020 Oct 6;8:4900213. doi: 10.1109/JTEHM.2020.3028996. eCollection 2020. IEEE J Transl Eng Health Med. 2020. PMID: 33094036 Free PMC article.
-
Cough frequency monitors: can they discriminate patient from environmental coughs?J Thorac Dis. 2016 Nov;8(11):3152-3159. doi: 10.21037/jtd.2016.11.02. J Thorac Dis. 2016. PMID: 28066594 Free PMC article.
References
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical