

Deep neural networks rival the representation of primate IT cortex for core visual object recognition
- PMID: 25521294
- PMCID: PMC4270441
- DOI: 10.1371/journal.pcbi.1003963
Deep neural networks rival the representation of primate IT cortex for core visual object recognition
Abstract
The primate visual system achieves remarkable visual object recognition performance even in brief presentations, and under changes to object exemplar, geometric transformations, and background variation (a.k.a. core visual object recognition). This remarkable performance is mediated by the representation formed in inferior temporal (IT) cortex. In parallel, recent advances in machine learning have led to ever higher performing models of object recognition using artificial deep neural networks (DNNs). It remains unclear, however, whether the representational performance of DNNs rivals that of the brain. To accurately produce such a comparison, a major difficulty has been a unifying metric that accounts for experimental limitations, such as the amount of noise, the number of neural recording sites, and the number of trials, and computational limitations, such as the complexity of the decoding classifier and the number of classifier training examples. In this work, we perform a direct comparison that corrects for these experimental limitations and computational considerations. As part of our methodology, we propose an extension of "kernel analysis" that measures the generalization accuracy as a function of representational complexity. Our evaluations show that, unlike previous bio-inspired models, the latest DNNs rival the representational performance of IT cortex on this visual object recognition task. Furthermore, we show that models that perform well on measures of representational performance also perform well on measures of representational similarity to IT, and on measures of predicting individual IT multi-unit responses. Whether these DNNs rely on computational mechanisms similar to the primate visual system is yet to be determined, but, unlike all previous bio-inspired models, that possibility cannot be ruled out merely on representational performance grounds.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures


 ), is plotted against complexity, the inverse of the regularization parameter (
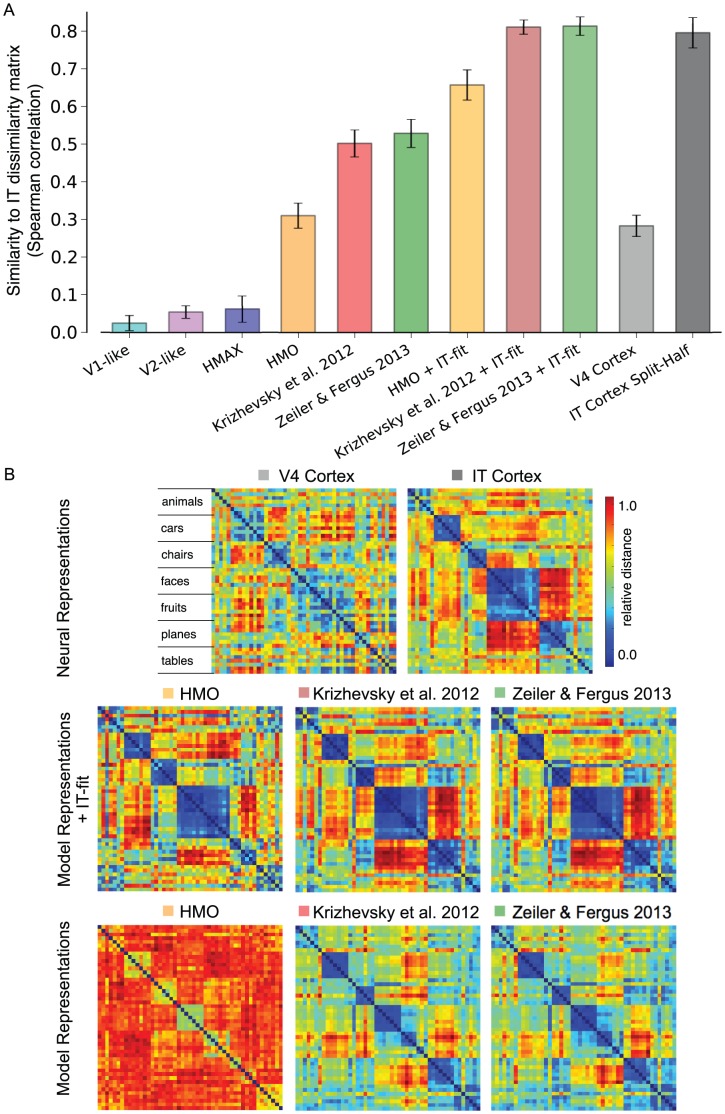
), is plotted against complexity, the inverse of the regularization parameter ( ). Shaded regions indicate the standard deviation of the measurement over image set randomizations, which are often smaller than the line thickness. The Zeiler & Fergus 2013, Krizhevsky et al. 2012 and HMO models are all hierarchical deep neural networks. HMAX is a model of the ventral visual stream and the V1-like and V2-like models attempt to replicate response properties of visual areas V1 and V2, respectively. These analyses indicate that the task we are measuring proves difficult for V1-like and V2-like models, with these models barely moving from 0.0 precision for all levels of complexity. Furthermore, the HMAX model, which has previously been shown to perform relatively well on object recognition tasks, performs only marginally better. Each of the remaining deep neural network models performs drastically better, with the Zeiler & Fergus 2013 model performing best for all levels of complexity. These results indicate that the visual object recognition task we evaluate is computationally challenging for all but the latest deep neural networks.
). Shaded regions indicate the standard deviation of the measurement over image set randomizations, which are often smaller than the line thickness. The Zeiler & Fergus 2013, Krizhevsky et al. 2012 and HMO models are all hierarchical deep neural networks. HMAX is a model of the ventral visual stream and the V1-like and V2-like models attempt to replicate response properties of visual areas V1 and V2, respectively. These analyses indicate that the task we are measuring proves difficult for V1-like and V2-like models, with these models barely moving from 0.0 precision for all levels of complexity. Furthermore, the HMAX model, which has previously been shown to perform relatively well on object recognition tasks, performs only marginally better. Each of the remaining deep neural network models performs drastically better, with the Zeiler & Fergus 2013 model performing best for all levels of complexity. These results indicate that the visual object recognition task we evaluate is computationally challenging for all but the latest deep neural networks.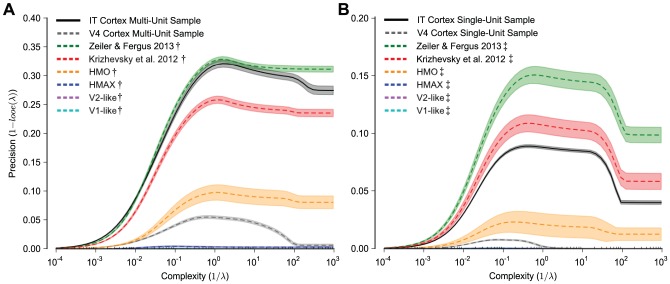
 symbol for noise matched to the multi-unit IT cortex sample and by the
symbol for noise matched to the multi-unit IT cortex sample and by the  symbol for noise matched to the single-unit IT cortex sample. To correct for sampling bias, the multi-unit analysis uses 80 samples, either 80 neural multi-units from V4 or IT cortex, or 80 features from the model representations, and the single-unit analysis uses 40 samples. To correct for experimental and intrinsic neural noise, we added noise to the subsampled model representation (no additional noise is added to the neural representations) that is commensurate to the observed noise from the IT measurements. Note that we observed similar noise between the V4 and IT Cortex samples and we do not attempt to correct the V4 cortex sample of the noise observed in the IT cortex sample. We observed substantially higher noise levels in IT single-unit recordings than multi-unit recordings due to both higher trial-to-trial variability and more trials for the multi-unit recordings. All model representations suffer decreases in accuracy after correcting for sampling and adding noise (compare absolute precision values to Fig. 2). All three deep neural networks perform significantly better than the V4 cortex sample. For the multi-unit analysis (A), IT cortex sample achieves high precision and is only matched in performance by the Zeiler & Fergus 2013 representation. For the single-unit analysis (B), both the Krizhevsky et al. 2012 and the Zeiler & Fergus 2013 representations surpass the IT representational performance.
symbol for noise matched to the single-unit IT cortex sample. To correct for sampling bias, the multi-unit analysis uses 80 samples, either 80 neural multi-units from V4 or IT cortex, or 80 features from the model representations, and the single-unit analysis uses 40 samples. To correct for experimental and intrinsic neural noise, we added noise to the subsampled model representation (no additional noise is added to the neural representations) that is commensurate to the observed noise from the IT measurements. Note that we observed similar noise between the V4 and IT Cortex samples and we do not attempt to correct the V4 cortex sample of the noise observed in the IT cortex sample. We observed substantially higher noise levels in IT single-unit recordings than multi-unit recordings due to both higher trial-to-trial variability and more trials for the multi-unit recordings. All model representations suffer decreases in accuracy after correcting for sampling and adding noise (compare absolute precision values to Fig. 2). All three deep neural networks perform significantly better than the V4 cortex sample. For the multi-unit analysis (A), IT cortex sample achieves high precision and is only matched in performance by the Zeiler & Fergus 2013 representation. For the single-unit analysis (B), both the Krizhevsky et al. 2012 and the Zeiler & Fergus 2013 representations surpass the IT representational performance.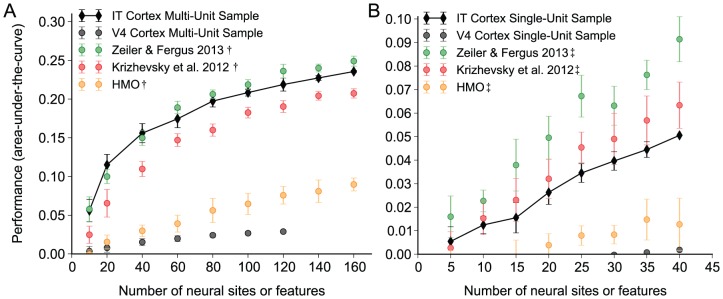
 symbol) or single-unit measurements (B, as indicated by the
symbol) or single-unit measurements (B, as indicated by the  symbol). For the multi-unit analysis, the Zeiler & Fergus 2013 representation rivals the IT cortex representation over our measured sample. For the single-unit analysis, the Krizhevsky et al. 2012 representation rivals the IT cortex representation for low number of features and slightly surpasses it for higher number of features. The Zeiler & Fergus 2013 representation surpasses the IT cortex representation over our measured sample.
symbol). For the multi-unit analysis, the Zeiler & Fergus 2013 representation rivals the IT cortex representation over our measured sample. For the single-unit analysis, the Krizhevsky et al. 2012 representation rivals the IT cortex representation for low number of features and slightly surpasses it for higher number of features. The Zeiler & Fergus 2013 representation surpasses the IT cortex representation over our measured sample.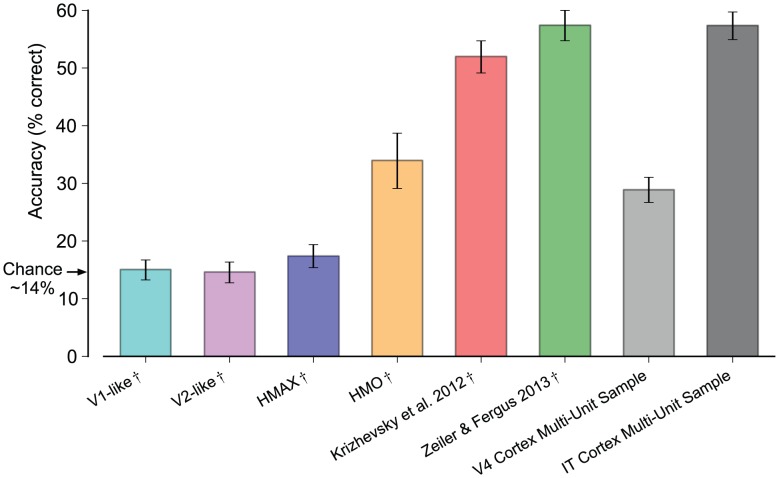
 symbol. Both model and neural representations are subsampled to 80 multi-unit samples or 80 features. Mirroring the results using kernel analysis, the IT cortex multi-unit sample achieves high generalization accuracy and is only matched in performance by the Zeiler & Fergus 2013 representation.
symbol. Both model and neural representations are subsampled to 80 multi-unit samples or 80 features. Mirroring the results using kernel analysis, the IT cortex multi-unit sample achieves high generalization accuracy and is only matched in performance by the Zeiler & Fergus 2013 representation.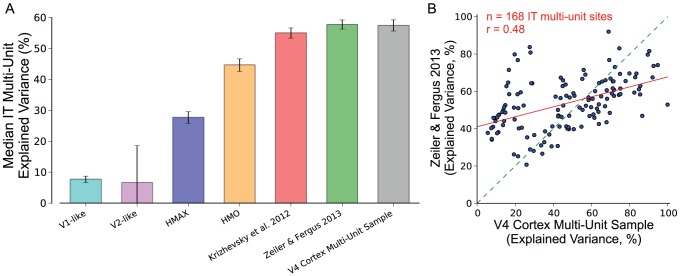
References
-
- Thorpe S, Fize D, Marlot C (1996) Speed of processing in the human visual system. Nature 381: 520–522. - PubMed
-
- Fabre-Thorpe M, Richard G, Thorpe SJ (1998) Rapid categorization of natural images by rhesus monkeys. Neuroreport 9: 303–308. - PubMed
-
- Keysers C, Xiao D, F 246 ldi 225 k P Perrett D (2001) The Speed of Sight. Journal of Cognitive Neuroscience 13: 90–101. - PubMed
-
- Potter MC, Wyble B, Hagmann CE, McCourt ES (2013) Detecting meaning in RSVP at 13 ms per picture. Attention, Perception, & Psychophysics 76: 270–279. - PubMed
-
- Andrews TJ, Coppola DM (1999) Idiosyncratic characteristics of saccadic eye movements when viewing different visual environments. Vision Research 39: 2947–2953. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
