

Invariant visual object recognition and shape processing in rats
- PMID: 25561421
- PMCID: PMC4383365
- DOI: 10.1016/j.bbr.2014.12.053
Invariant visual object recognition and shape processing in rats
Abstract
Invariant visual object recognition is the ability to recognize visual objects despite the vastly different images that each object can project onto the retina during natural vision, depending on its position and size within the visual field, its orientation relative to the viewer, etc. Achieving invariant recognition represents such a formidable computational challenge that is often assumed to be a unique hallmark of primate vision. Historically, this has limited the invasive investigation of its neuronal underpinnings to monkey studies, in spite of the narrow range of experimental approaches that these animal models allow. Meanwhile, rodents have been largely neglected as models of object vision, because of the widespread belief that they are incapable of advanced visual processing. However, the powerful array of experimental tools that have been developed to dissect neuronal circuits in rodents has made these species very attractive to vision scientists too, promoting a new tide of studies that have started to systematically explore visual functions in rats and mice. Rats, in particular, have been the subjects of several behavioral studies, aimed at assessing how advanced object recognition and shape processing is in this species. Here, I review these recent investigations, as well as earlier studies of rat pattern vision, to provide an historical overview and a critical summary of the status of the knowledge about rat object vision. The picture emerging from this survey is very encouraging with regard to the possibility of using rats as complementary models to monkeys in the study of higher-level vision.
Keywords: Invariant recognition; Pattern vision; Rat; Rodent; Shape processing.
Copyright © 2015 The Author. Published by Elsevier B.V. All rights reserved.
Figures
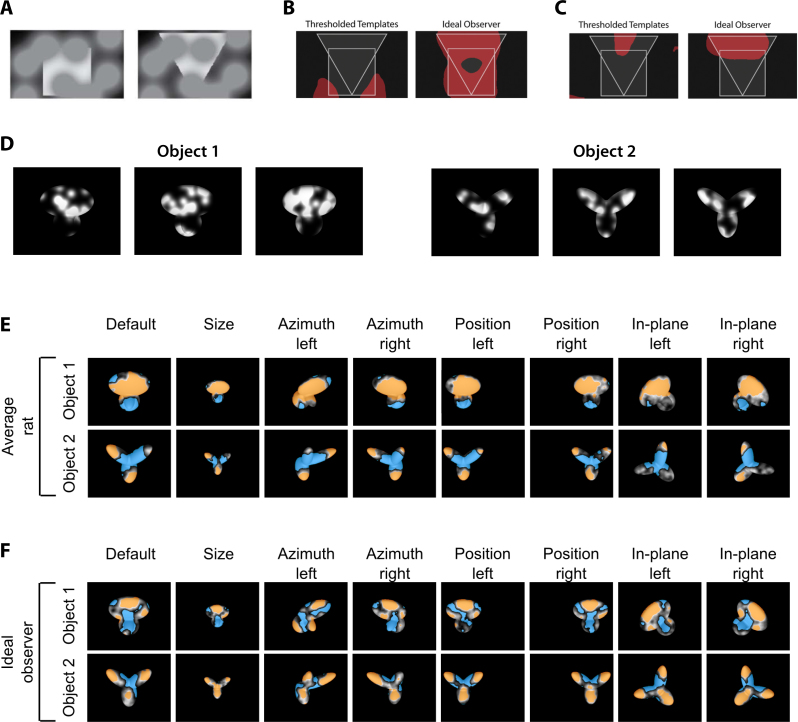
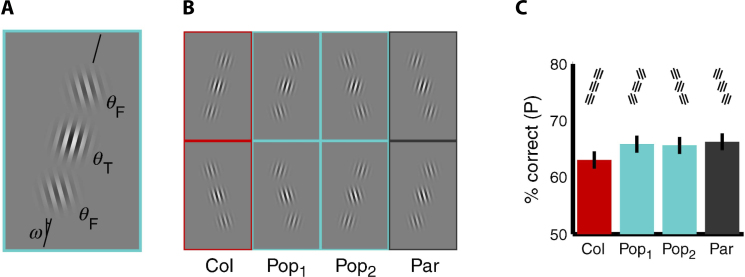
Similar articles
-
Multifeatural shape processing in rats engaged in invariant visual object recognition.J Neurosci. 2013 Apr 3;33(14):5939-56. doi: 10.1523/JNEUROSCI.3629-12.2013. J Neurosci. 2013. PMID: 23554476 Free PMC article.
-
Object similarity affects the perceptual strategy underlying invariant visual object recognition in rats.Front Neural Circuits. 2015 Mar 12;9:10. doi: 10.3389/fncir.2015.00010. eCollection 2015. Front Neural Circuits. 2015. PMID: 25814936 Free PMC article.
-
Accuracy of Rats in Discriminating Visual Objects Is Explained by the Complexity of Their Perceptual Strategy.Curr Biol. 2018 Apr 2;28(7):1005-1015.e5. doi: 10.1016/j.cub.2018.02.037. Epub 2018 Mar 15. Curr Biol. 2018. PMID: 29551414 Free PMC article.
-
How position dependent is visual object recognition?Trends Cogn Sci. 2008 Mar;12(3):114-22. doi: 10.1016/j.tics.2007.12.006. Epub 2008 Feb 11. Trends Cogn Sci. 2008. PMID: 18262829 Review.
-
Object recognition and segmentation by a fragment-based hierarchy.Trends Cogn Sci. 2007 Feb;11(2):58-64. doi: 10.1016/j.tics.2006.11.009. Epub 2006 Dec 22. Trends Cogn Sci. 2007. PMID: 17188555 Review.
Cited by
-
Using deep neural networks to evaluate object vision tasks in rats.PLoS Comput Biol. 2021 Mar 2;17(3):e1008714. doi: 10.1371/journal.pcbi.1008714. eCollection 2021 Mar. PLoS Comput Biol. 2021. PMID: 33651793 Free PMC article.
-
A Novel Method for Training Mice in Visuo-Tactile 3-D Object Discrimination and Recognition.Front Behav Neurosci. 2018 Nov 13;12:274. doi: 10.3389/fnbeh.2018.00274. eCollection 2018. Front Behav Neurosci. 2018. PMID: 30555307 Free PMC article.
-
Cross-Species Evidence for Psilocin-Induced Visual Distortions: Apparent Motion Is Perceived by Both Humans and Rats.Biol Psychiatry Glob Open Sci. 2025 May 2;5(5):100524. doi: 10.1016/j.bpsgos.2025.100524. eCollection 2025 Sep. Biol Psychiatry Glob Open Sci. 2025. PMID: 40599633 Free PMC article.
-
Mice recognize 3D objects from recalled 2D pictures, support for picture-object equivalence.Sci Rep. 2022 Mar 9;12(1):4184. doi: 10.1038/s41598-022-07782-4. Sci Rep. 2022. PMID: 35264621 Free PMC article.
-
Hierarchical stimulus processing in rodent primary and lateral visual cortex as assessed through neuronal selectivity and repetition suppression.J Neurophysiol. 2018 Sep 1;120(3):926-941. doi: 10.1152/jn.00673.2017. Epub 2018 May 9. J Neurophysiol. 2018. PMID: 29742022 Free PMC article.
References
-
- Cox D.D. Do we understand high-level vision? Curr Opin Neurobiol. 2014;25:187–193. - PubMed
-
- Rust N.C., Stocker A.A. Ambiguity and invariance: two fundamental challenges for visual processing. Curr Opin Neurobiol. 2010;20:382–388. - PubMed
-
- Ullman S. MIT Press; Cambridge, MA: 1996. High level vision.
-
- DiCarlo J.J., Cox D.D. Untangling invariant object recognition. Trends Cogn Sci. 2007;11:333–341. - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
