

Processing speed enhances model-based over model-free reinforcement learning in the presence of high working memory functioning
- PMID: 25566131
- PMCID: PMC4269125
- DOI: 10.3389/fpsyg.2014.01450
Processing speed enhances model-based over model-free reinforcement learning in the presence of high working memory functioning
Abstract
Theories of decision-making and its neural substrates have long assumed the existence of two distinct and competing valuation systems, variously described as goal-directed vs. habitual, or, more recently and based on statistical arguments, as model-free vs. model-based reinforcement-learning. Though both have been shown to control choices, the cognitive abilities associated with these systems are under ongoing investigation. Here we examine the link to cognitive abilities, and find that individual differences in processing speed covary with a shift from model-free to model-based choice control in the presence of above-average working memory function. This suggests shared cognitive and neural processes; provides a bridge between literatures on intelligence and valuation; and may guide the development of process models of different valuation components. Furthermore, it provides a rationale for individual differences in the tendency to deploy valuation systems, which may be important for understanding the manifold neuropsychiatric diseases associated with malfunctions of valuation.
Keywords: cognitive abilities; decision-making; fluid intelligence; habitual and goal-directed system; model-based and model-free learning; reward.
Figures
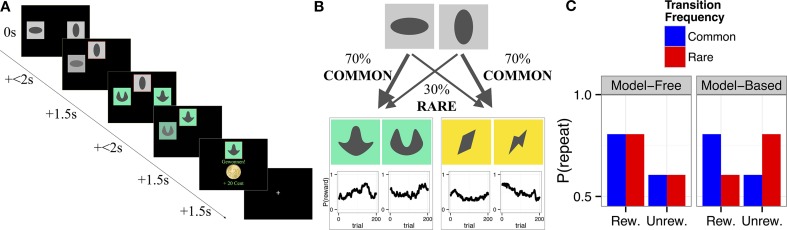
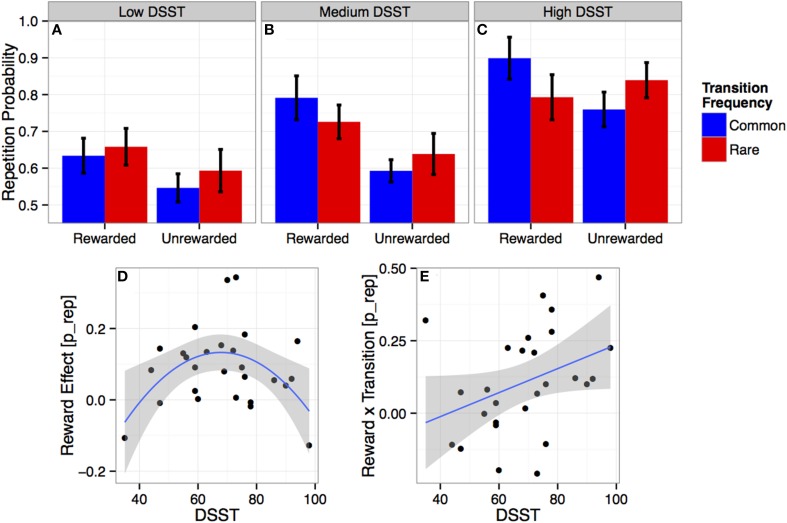
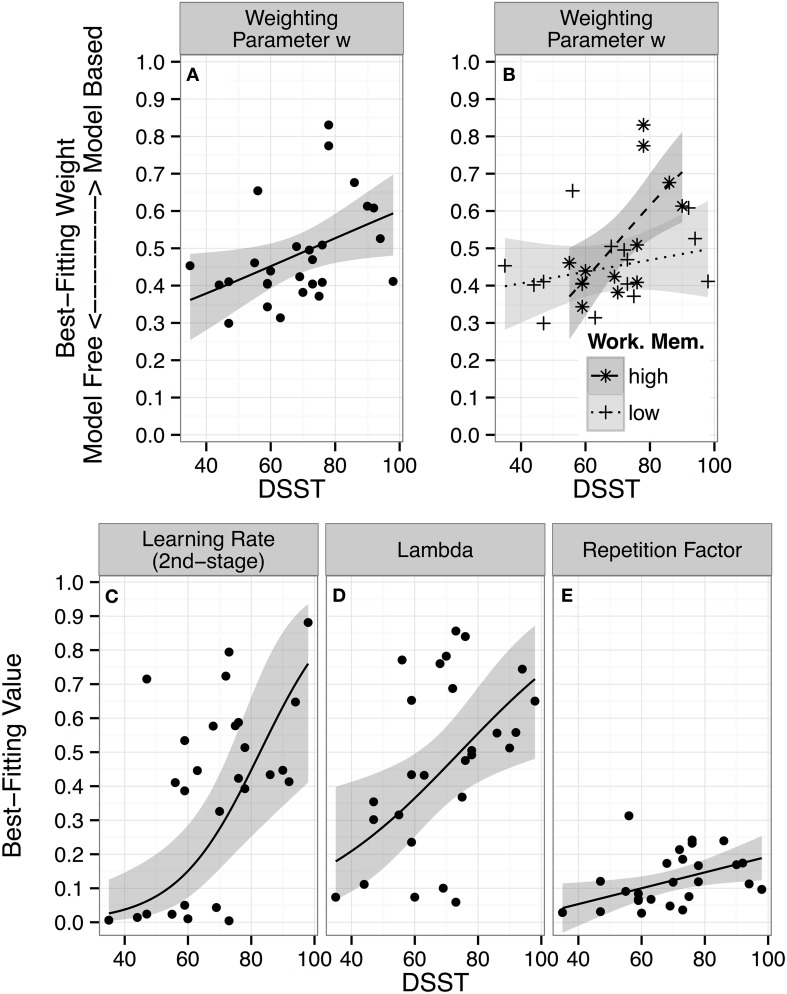
References
-
- Army Individual Test Battery. (1944). Manual of Directions and Scoring. Washington, DC: War Department, Adjutant General's Office.
-
- Bates D., Maechler M., Bolker B. (2013). Linear mixed-Effects Models Using S4 Classes, [Software] Version: 0.999999-2. Available online at: http://www.R-project.org
-
- Benjamini Y., Hochberg Y. (1995). Controlling the false discovery rate: a practical and powerful approach to multiple testing. J. R. Statist. Soc. B 57, 289–300.
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources