

Estimating the global abundance of ground level presence of particulate matter (PM2.5)
- PMID: 25599634
- PMCID: PMC10187881
- DOI: 10.4081/gh.2014.292
Estimating the global abundance of ground level presence of particulate matter (PM2.5)
Abstract
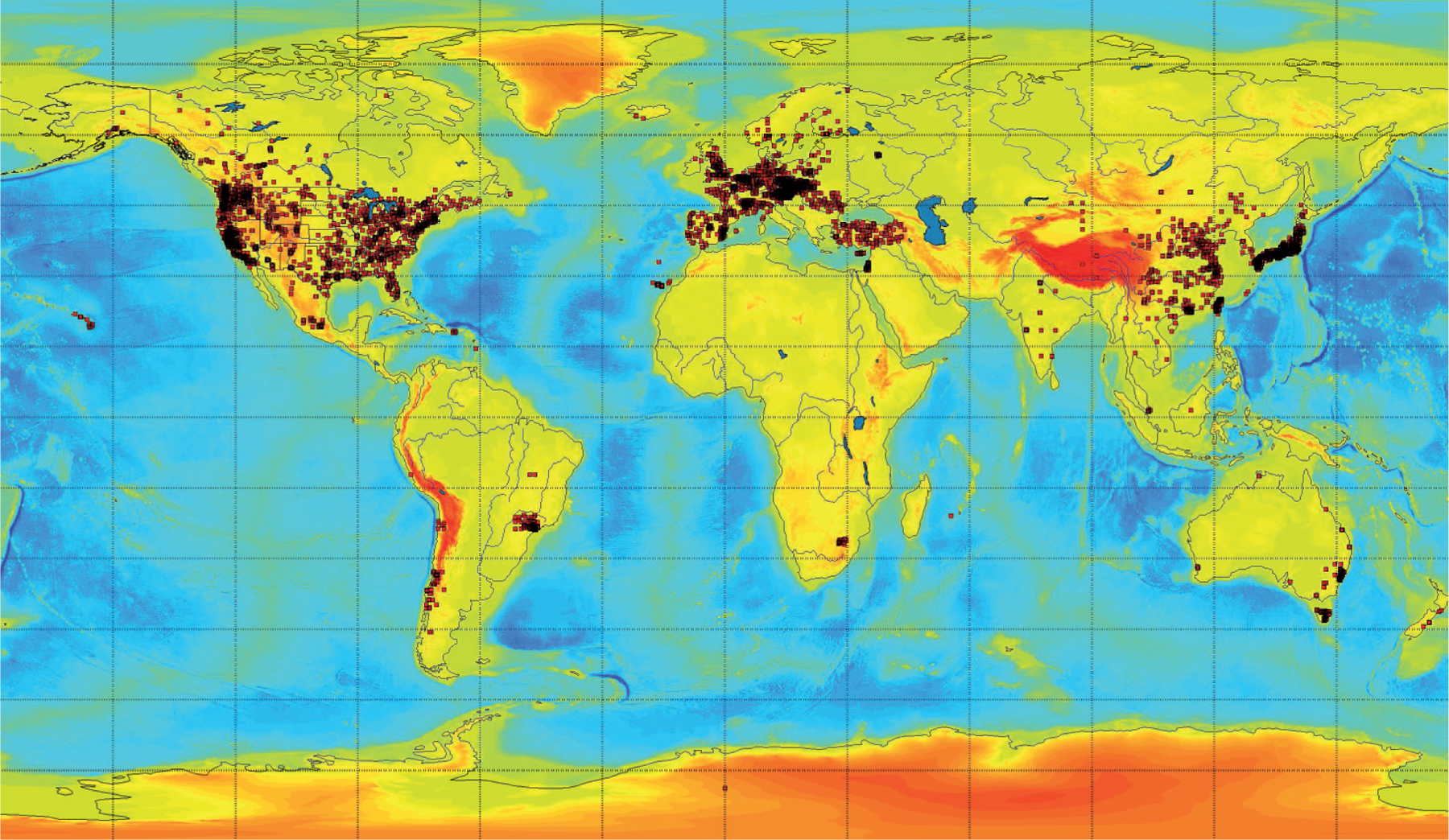
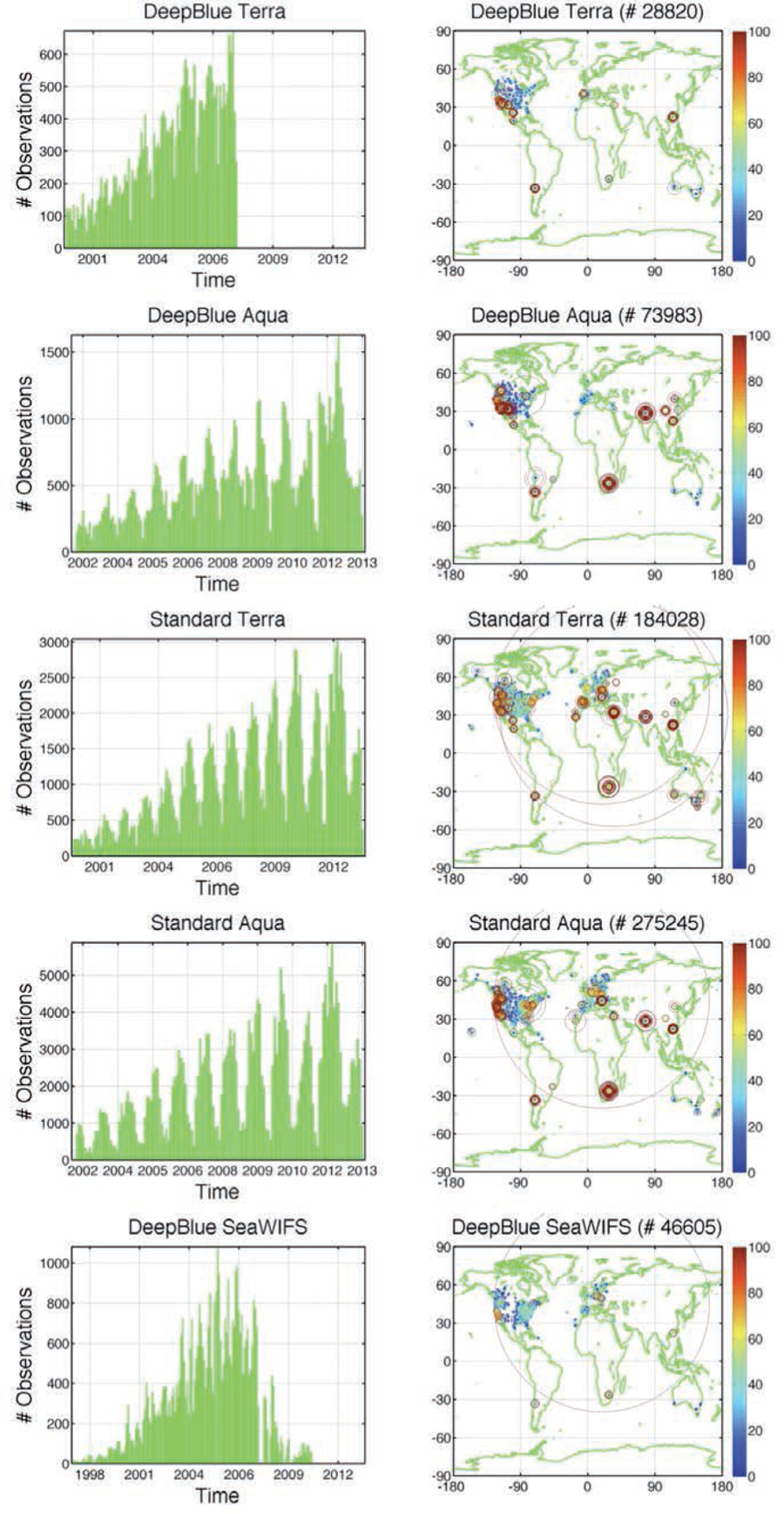
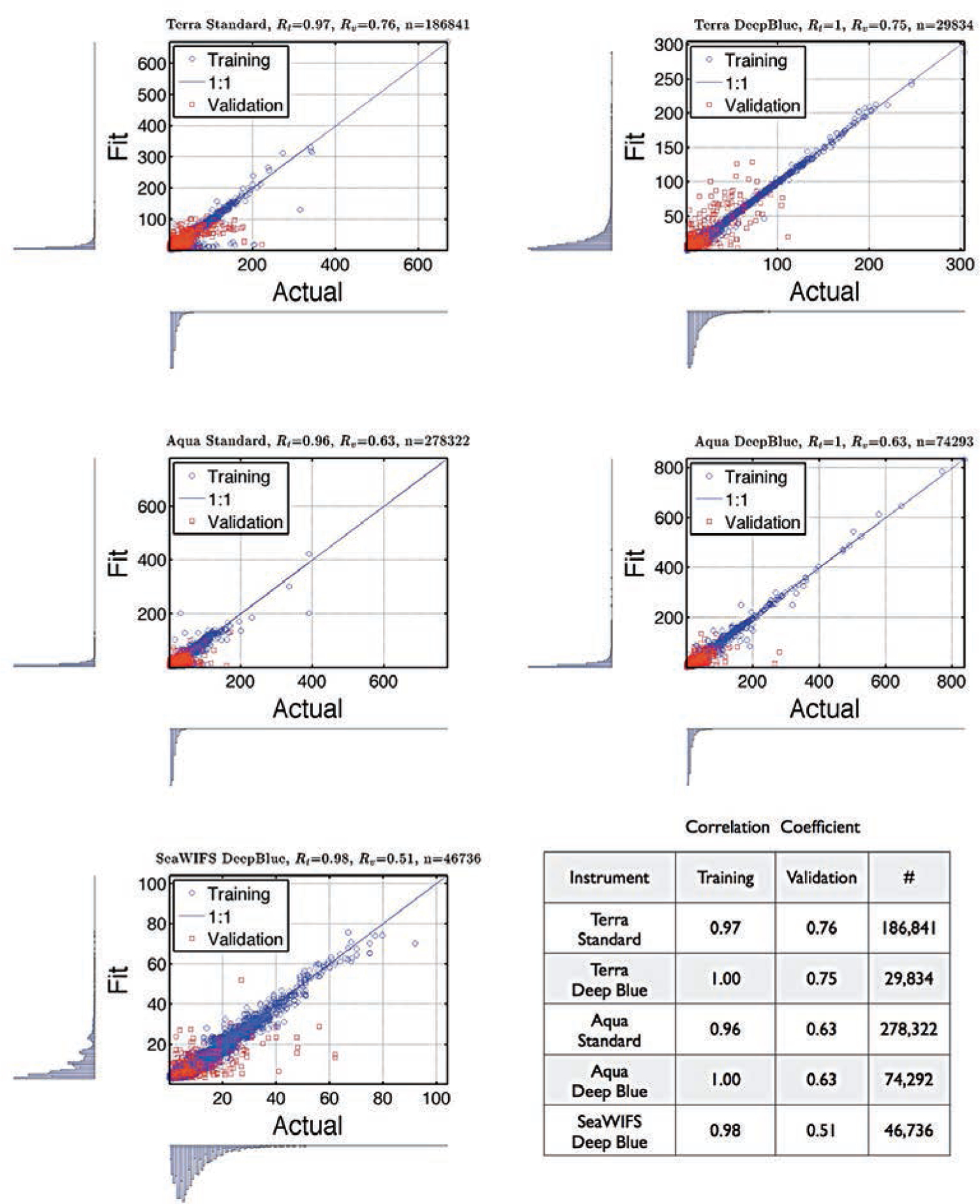
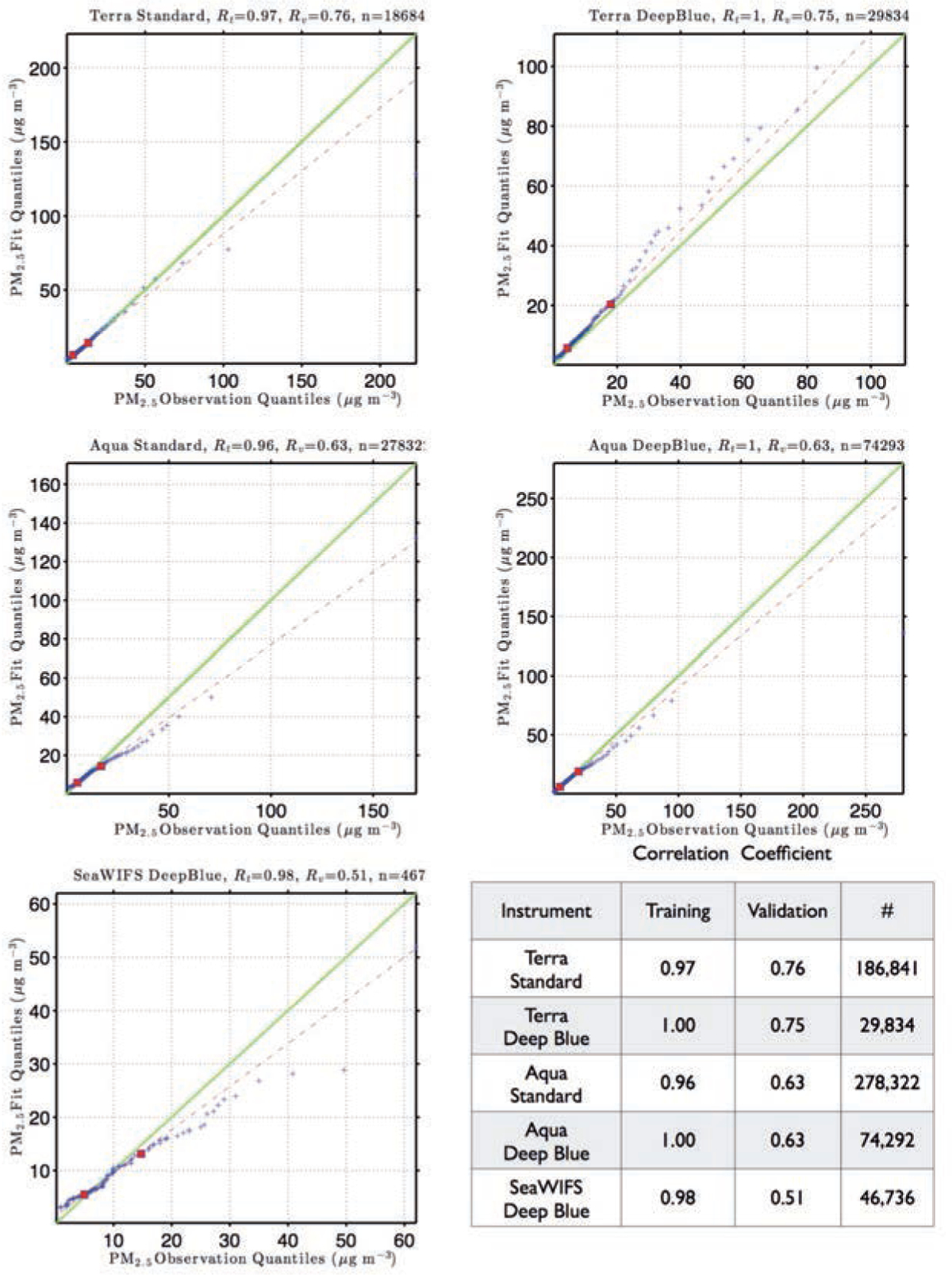
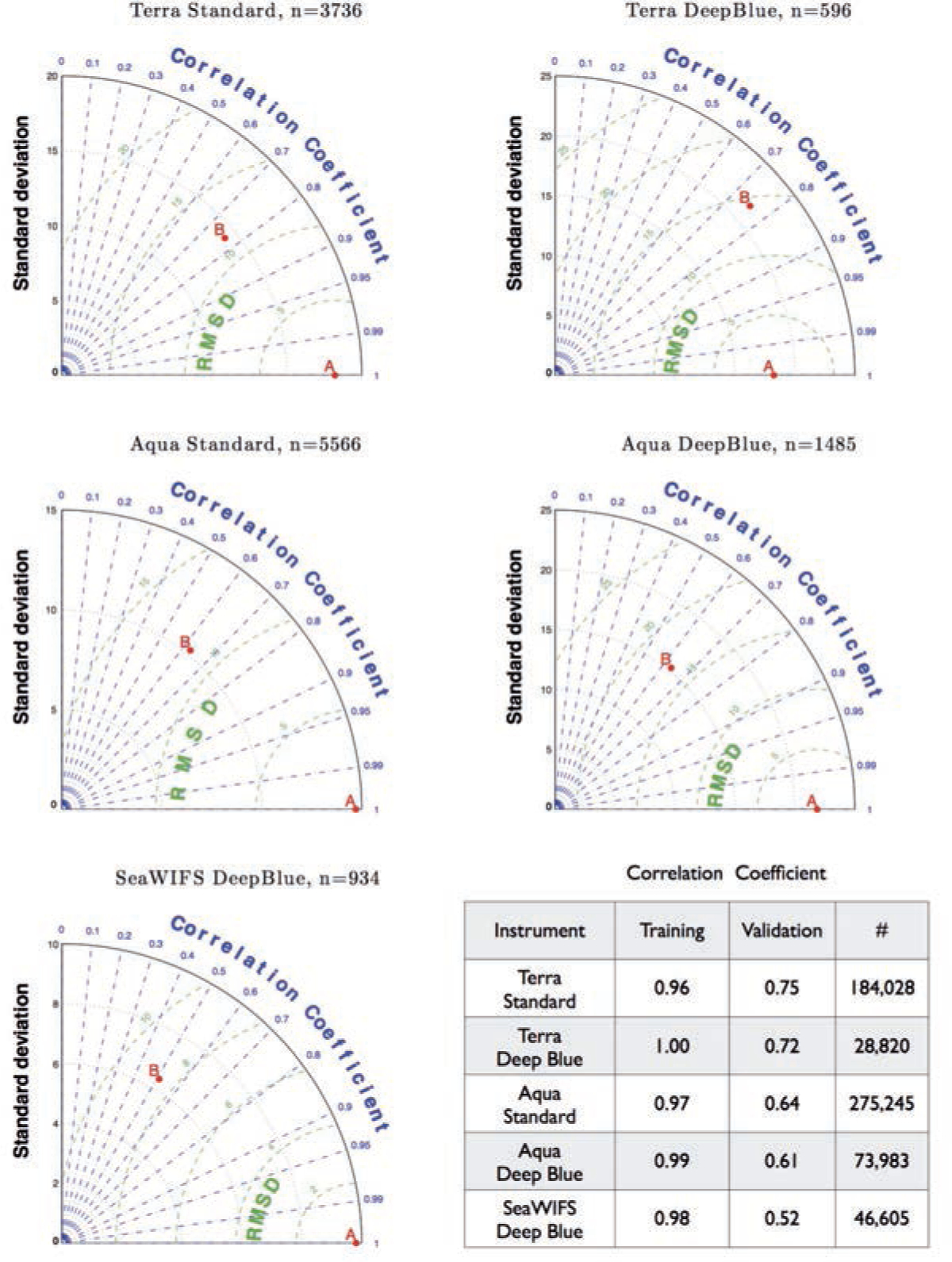
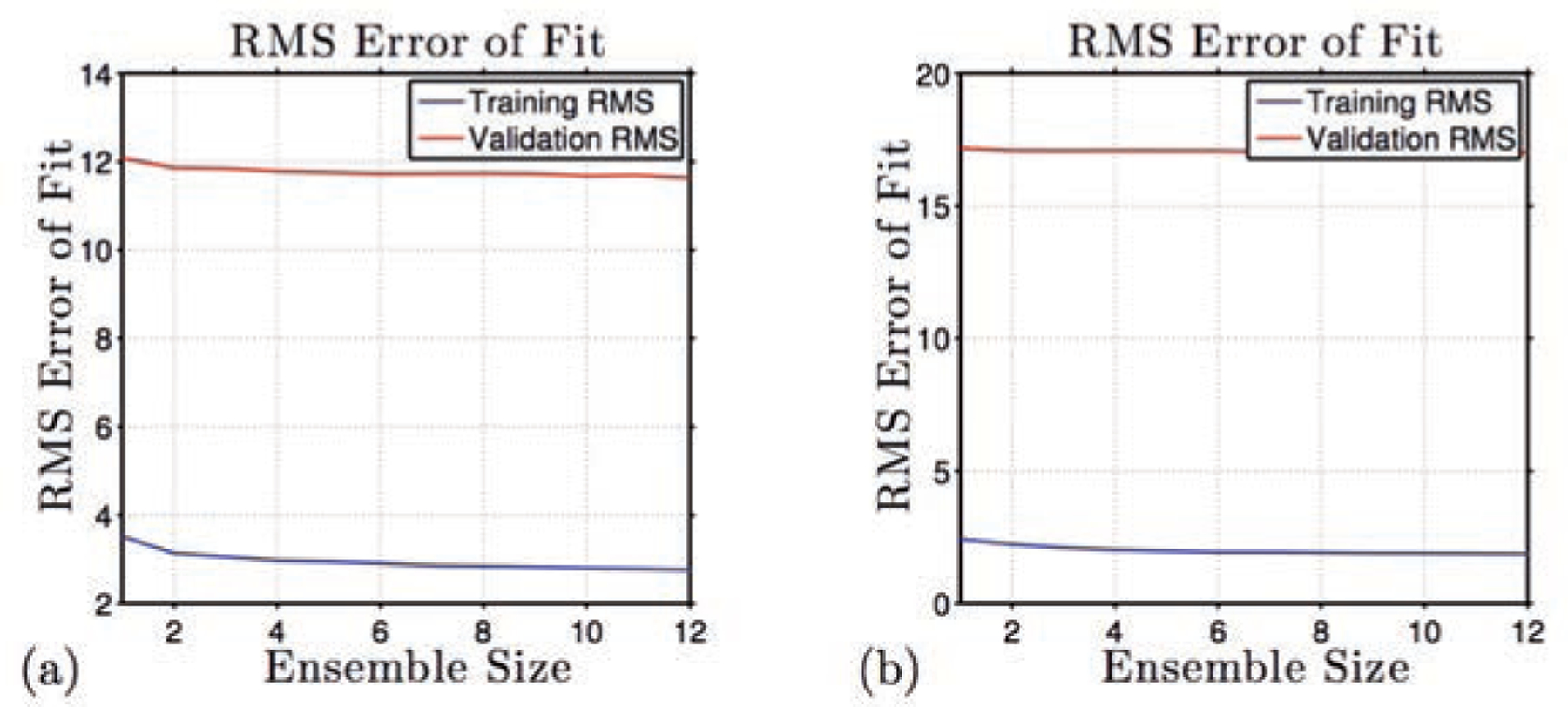
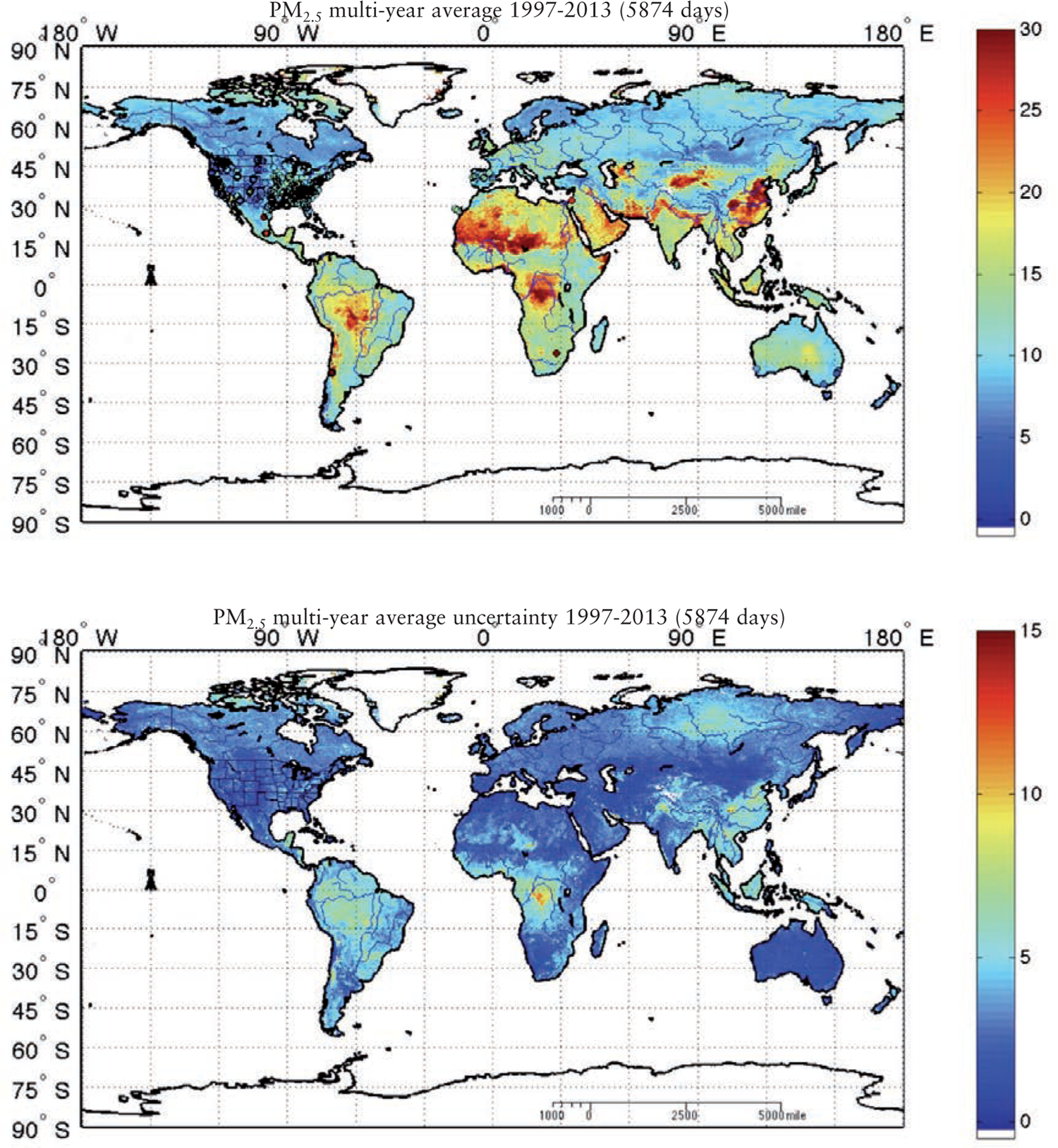
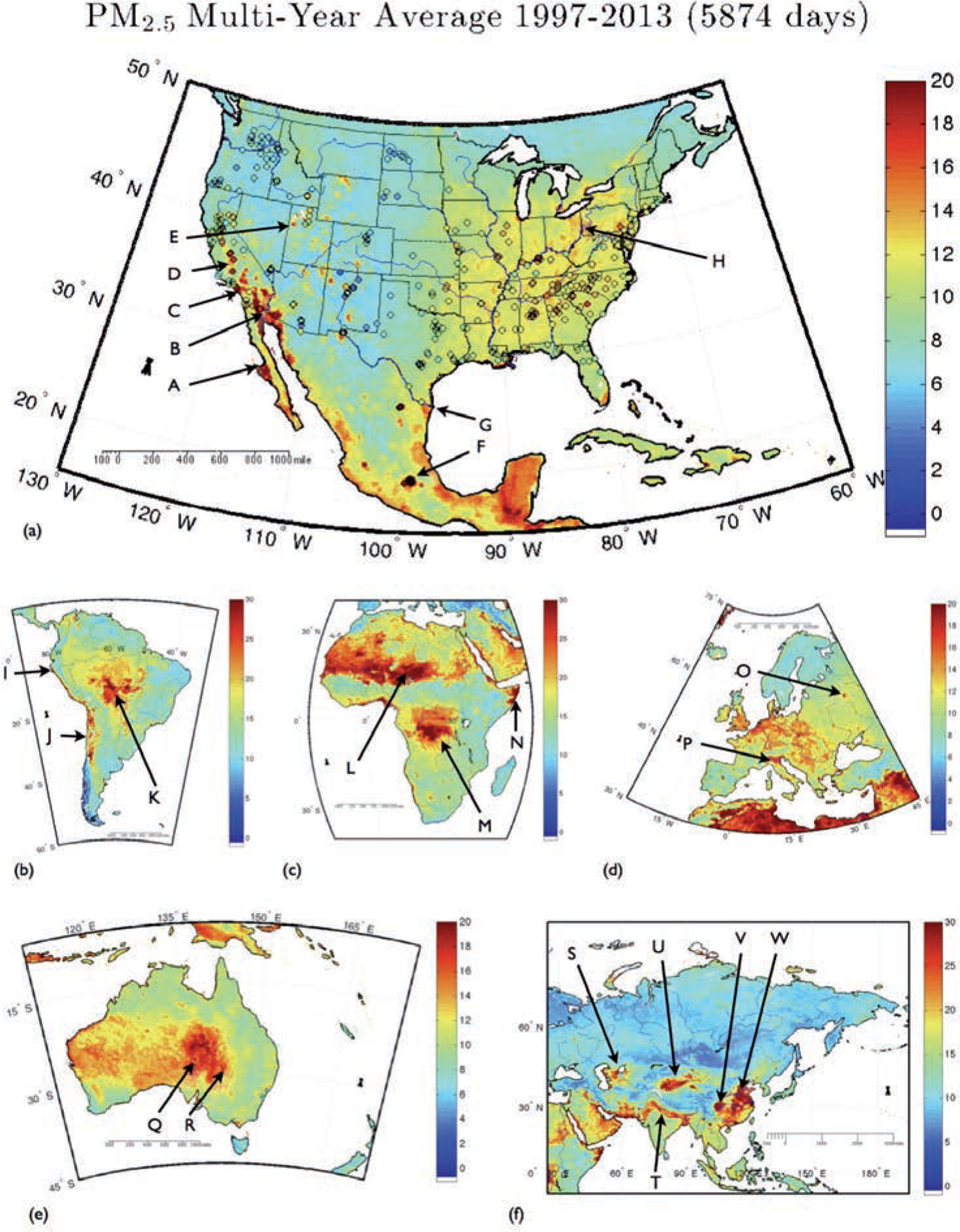
With the increasing awareness of the health impacts of particulate matter, there is a growing need to comprehend the spatial and temporal variations of the global abundance of ground level airborne particulate matter with a diameter of 2.5 microns or less (PM2.5). Here we use a suite of remote sensing and meteorological data products together with ground-based observations of particulate matter from 8,329 measurement sites in 55 countries taken 1997-2014 to train a machine-learning algorithm to estimate the daily distributions of PM2.5 from 1997 to the present. In this first paper of a series, we present the methodology and global average results from this period and demonstrate that the new PM2.5 data product can reliably represent global observations of PM2.5 for epidemiological studies.
Figures
References
-
- Andersen ZJ, 2012. Health effects of long-term exposure to air pollution: an overview of major respiratory and cardiovascular diseases and diabetes. Chem Ind Chem Eng Q 18, 617–622.
-
- Anderson RR, Martello DV, White CM, Crist KC, John K, Modey WK, Eatough DJ, 2004. The regional nature of PM2.5 episodes in the upper Ohio River Valley. J Air Waste Manag Assoc 54, 971–984. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
