

Reversal learning and dopamine: a bayesian perspective
- PMID: 25673835
- PMCID: PMC4323525
- DOI: 10.1523/JNEUROSCI.1989-14.2015
Reversal learning and dopamine: a bayesian perspective
Abstract
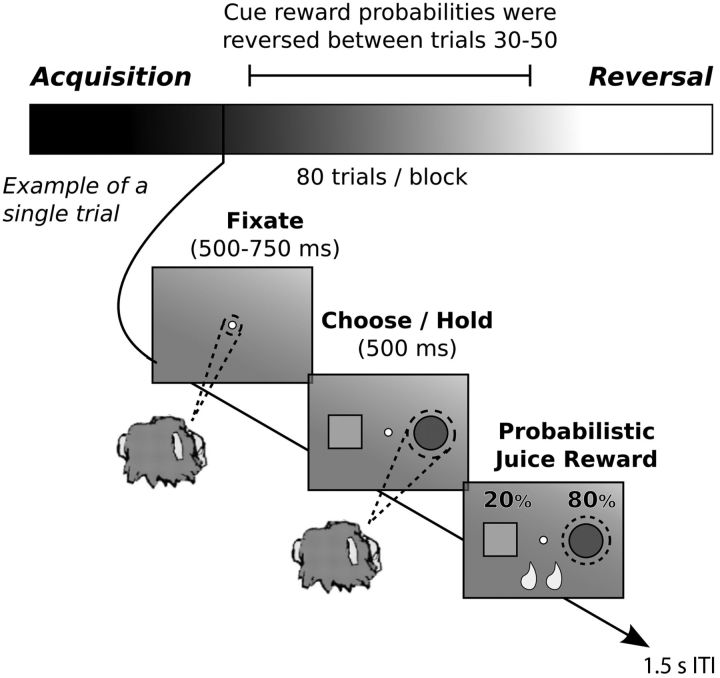
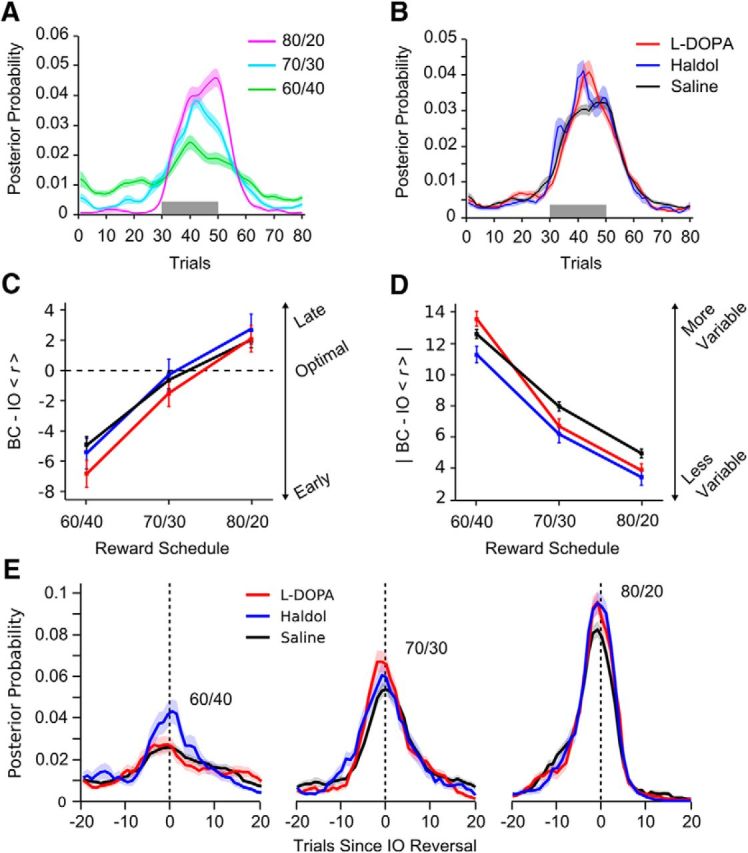
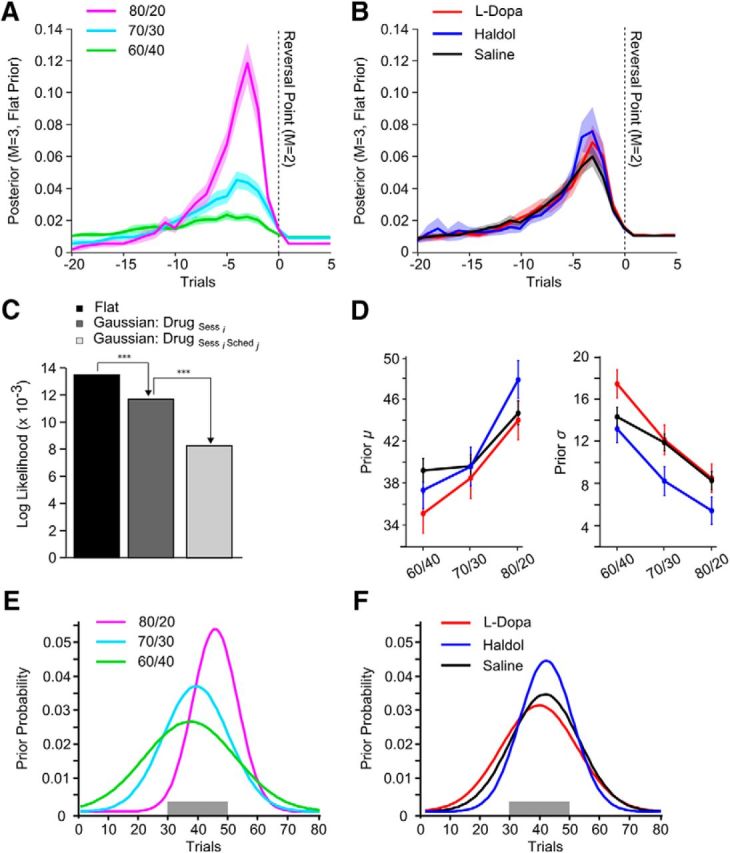
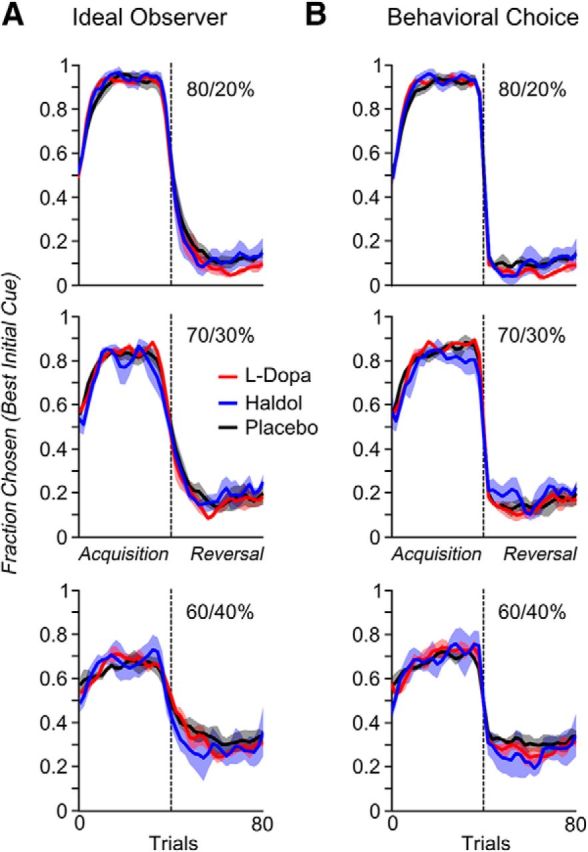
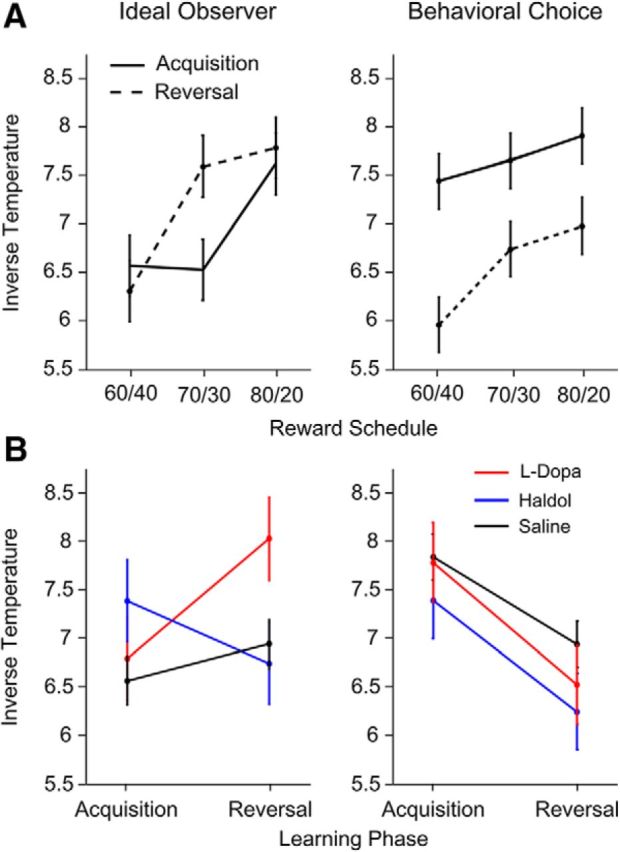
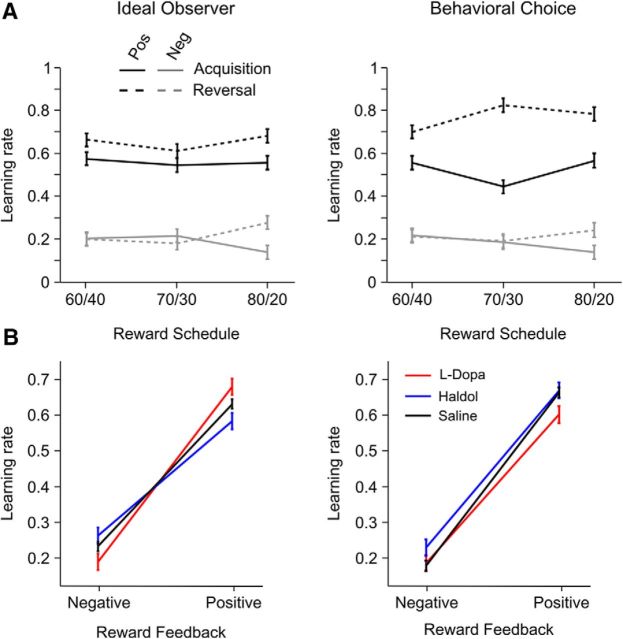
Reversal learning has been studied as the process of learning to inhibit previously rewarded actions. Deficits in reversal learning have been seen after manipulations of dopamine and lesions of the orbitofrontal cortex. However, reversal learning is often studied in animals that have limited experience with reversals. As such, the animals are learning that reversals occur during data collection. We have examined a task regime in which monkeys have extensive experience with reversals and stable behavioral performance on a probabilistic two-arm bandit reversal learning task. We developed a Bayesian analysis approach to examine the effects of manipulations of dopamine on reversal performance in this regime. We find that the analysis can clarify the strategy of the animal. Specifically, at reversal, the monkeys switch quickly from choosing one stimulus to choosing the other, as opposed to gradually transitioning, which might be expected if they were using a naive reinforcement learning (RL) update of value. Furthermore, we found that administration of haloperidol affects the way the animals integrate prior knowledge into their choice behavior. Animals had a stronger prior on where reversals would occur on haloperidol than on levodopa (l-DOPA) or placebo. This strong prior was appropriate, because the animals had extensive experience with reversals occurring in the middle of the block. Overall, we find that Bayesian dissection of the behavior clarifies the strategy of the animals and reveals an effect of haloperidol on integration of prior information with evidence in favor of a choice reversal.
Keywords: Bayesian; dopamine; haloperidol; l-DOPA; reinforcement learning; reversal learning.
Copyright © 2015 the authors 0270-6474/15/352407-10$15.00/0.
Figures
References
-
- Clarke HF, Cardinal RN, Rygula R, Hong YT, Fryer TD, Sawiak SJ, Ferrari V, Cockcroft G, Aigbirhio FI, Robbins TW, Roberts AC. Orbitofrontal dopamine depletion upregulates caudate dopamine and alters behavior via changes in reinforcement sensitivity. J Neurosci. 2014;34:7663–7676. doi: 10.1523/JNEUROSCI.0718-14.2014. - DOI - PMC - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources