

Fluorescent in situ sequencing (FISSEQ) of RNA for gene expression profiling in intact cells and tissues
- PMID: 25675209
- PMCID: PMC4327781
- DOI: 10.1038/nprot.2014.191
Fluorescent in situ sequencing (FISSEQ) of RNA for gene expression profiling in intact cells and tissues
Abstract
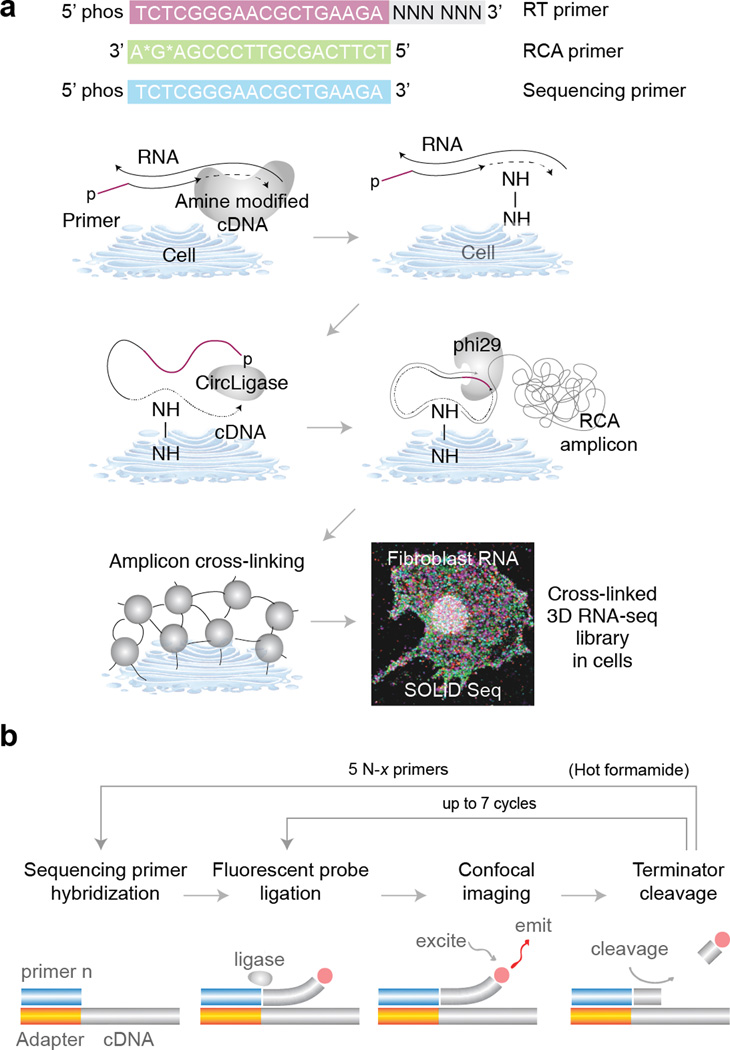
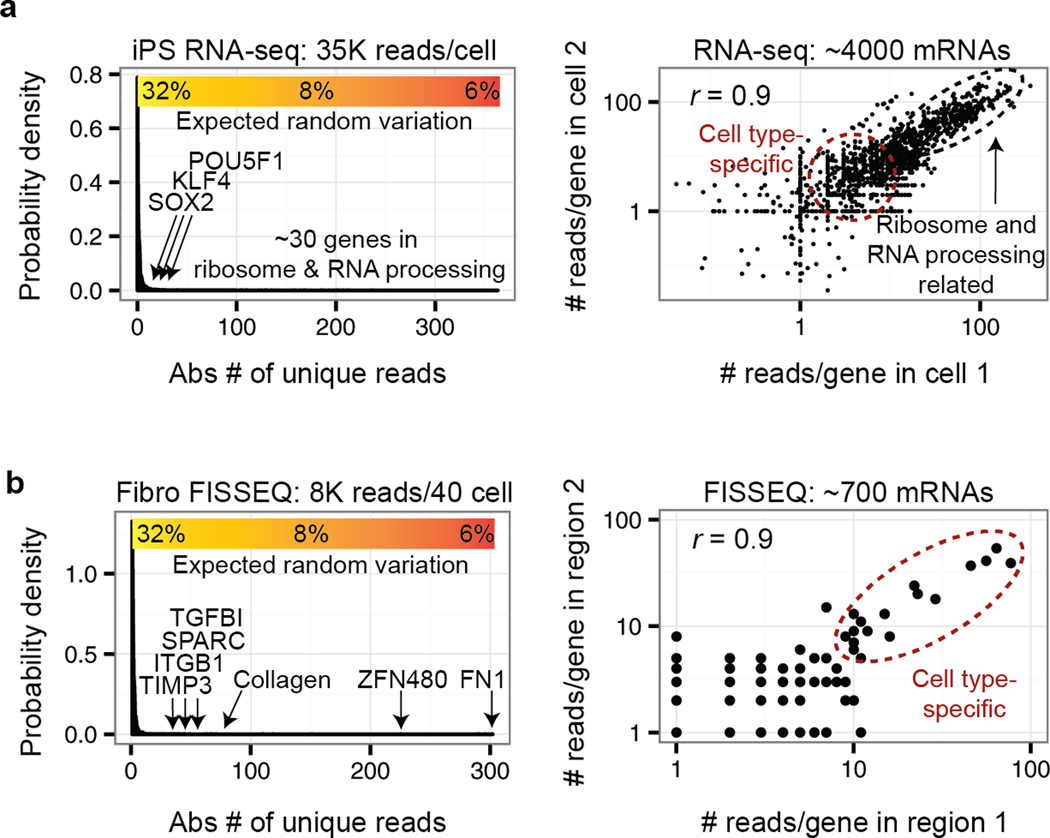
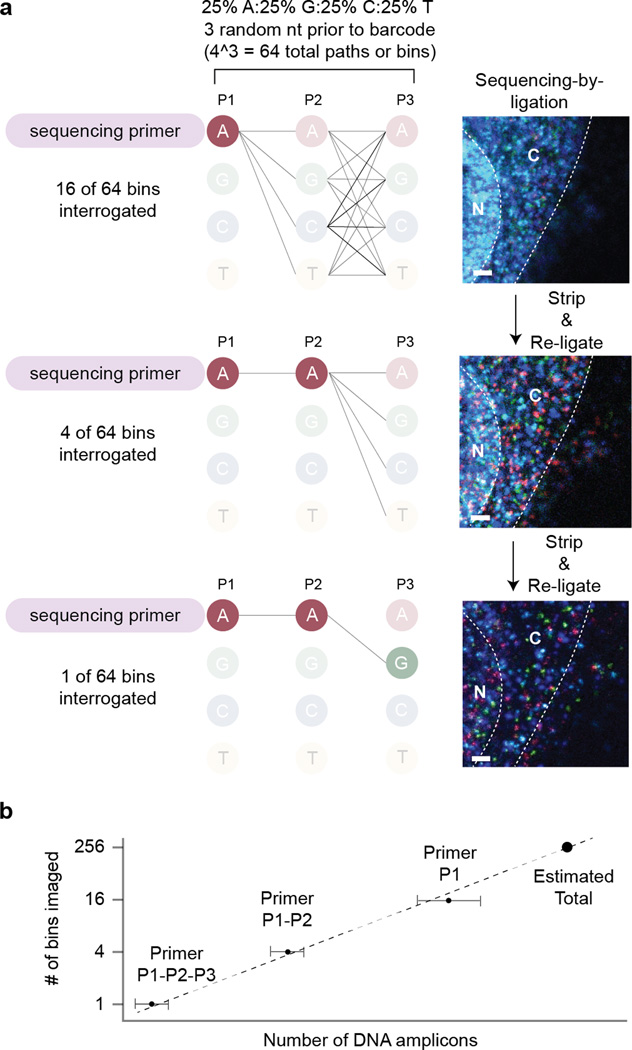
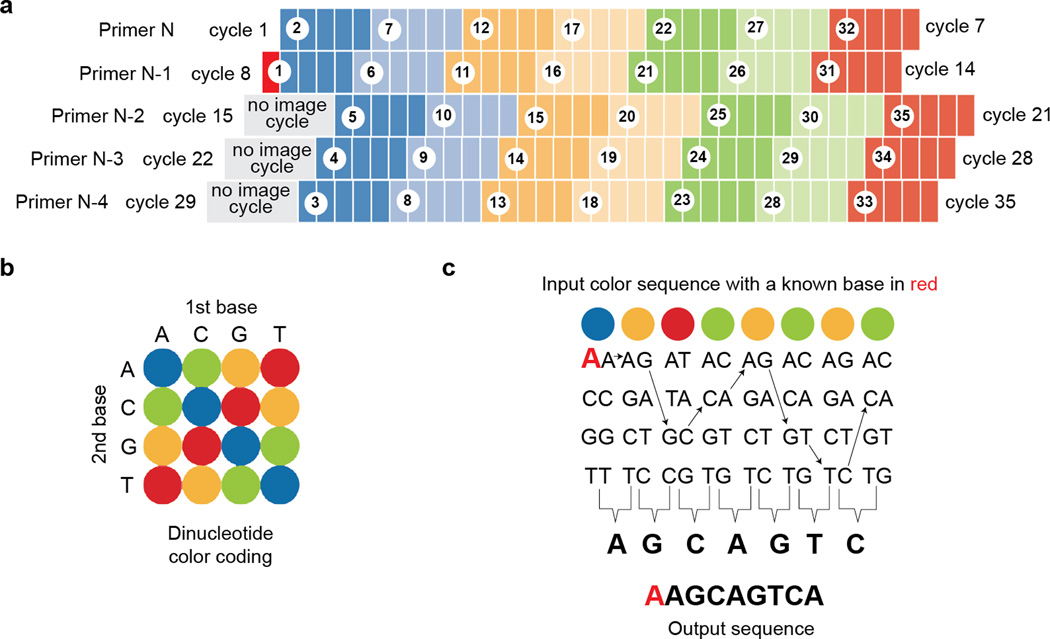
RNA-sequencing (RNA-seq) measures the quantitative change in gene expression over the whole transcriptome, but it lacks spatial context. In contrast, in situ hybridization provides the location of gene expression, but only for a small number of genes. Here we detail a protocol for genome-wide profiling of gene expression in situ in fixed cells and tissues, in which RNA is converted into cross-linked cDNA amplicons and sequenced manually on a confocal microscope. Unlike traditional RNA-seq, our method enriches for context-specific transcripts over housekeeping and/or structural RNA, and it preserves the tissue architecture for RNA localization studies. Our protocol is written for researchers experienced in cell microscopy with minimal computing skills. Library construction and sequencing can be completed within 14 d, with image analysis requiring an additional 2 d.
Conflict of interest statement
Potential conflicts of interests for G.M.C. are listed on
Figures
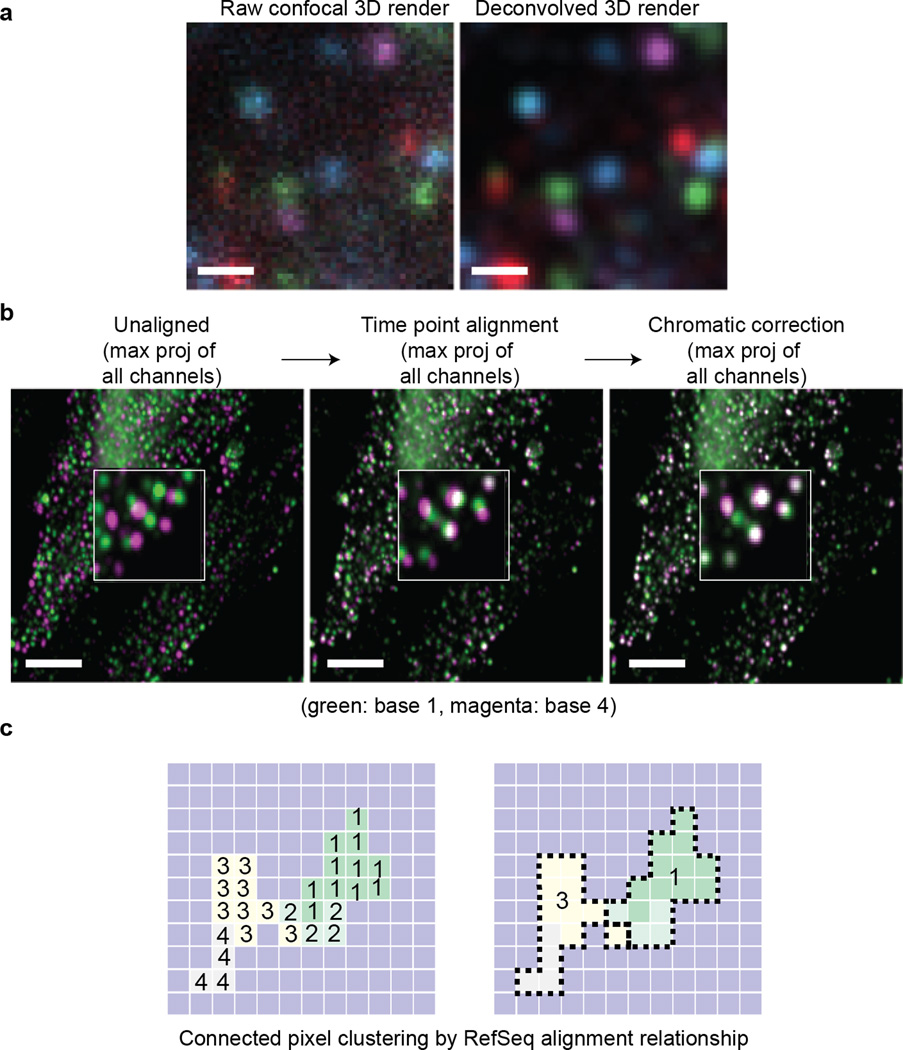
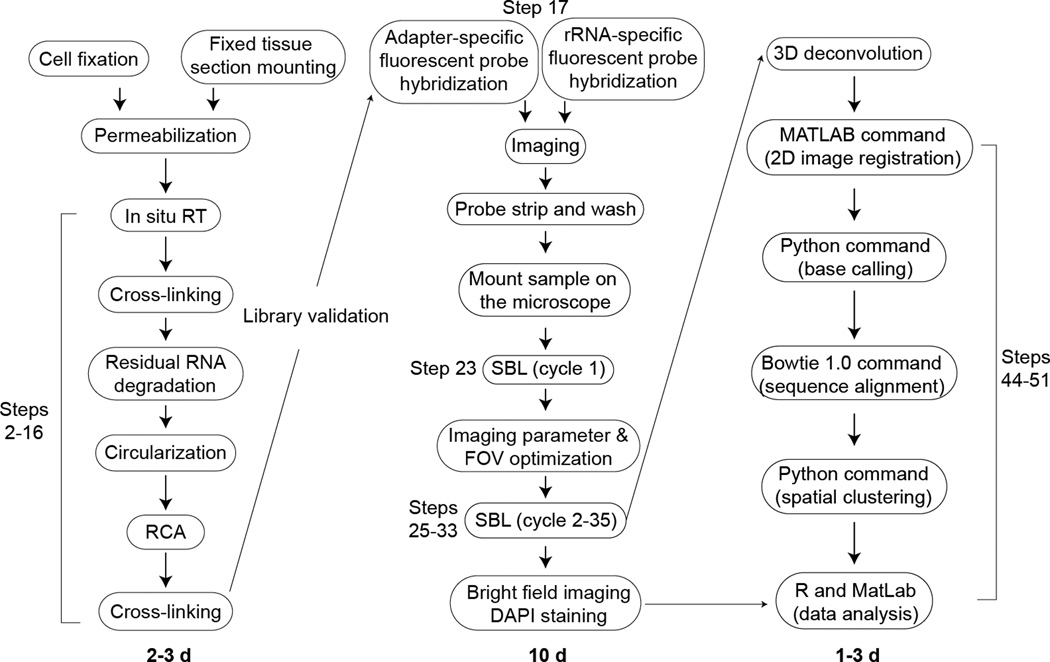
References
-
- Rifai N, Gillette MA, Carr SA. Protein biomarker discovery and validation: the long and uncertain path to clinical utility. Nat Biotechnol. 2006;24:971–983. - PubMed
-
- Battich N, Stoeger T, Pelkmans L. Image-based transcriptomics in thousands of single human cells at single-molecule resolution. Nat Methods. 2013 - PubMed
-
- Lein ES, et al. Genome-wide atlas of gene expression in the adult mouse brain. Nature. 2007;445:168–176. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
