

Interplay of approximate planning strategies
- PMID: 25675480
- PMCID: PMC4364207
- DOI: 10.1073/pnas.1414219112
Interplay of approximate planning strategies
Abstract
Humans routinely formulate plans in domains so complex that even the most powerful computers are taxed. To do so, they seem to avail themselves of many strategies and heuristics that efficiently simplify, approximate, and hierarchically decompose hard tasks into simpler subtasks. Theoretical and cognitive research has revealed several such strategies; however, little is known about their establishment, interaction, and efficiency. Here, we use model-based behavioral analysis to provide a detailed examination of the performance of human subjects in a moderately deep planning task. We find that subjects exploit the structure of the domain to establish subgoals in a way that achieves a nearly maximal reduction in the cost of computing values of choices, but then combine partial searches with greedy local steps to solve subtasks, and maladaptively prune the decision trees of subtasks in a reflexive manner upon encountering salient losses. Subjects come idiosyncratically to favor particular sequences of actions to achieve subgoals, creating novel complex actions or "options."
Keywords: hierarchical reinforcement learning; memoization; planning; pruning.
Conflict of interest statement
The authors declare no conflict of interest.
Figures

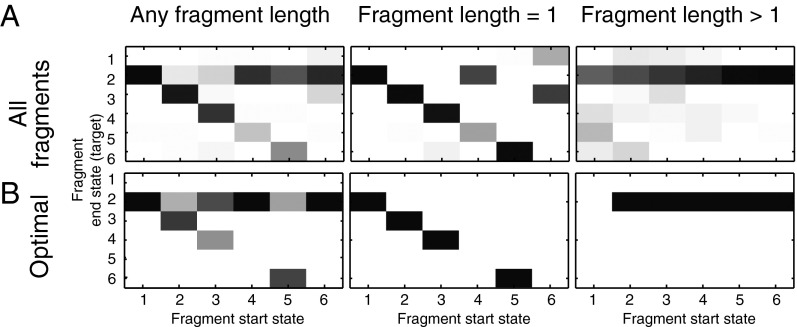
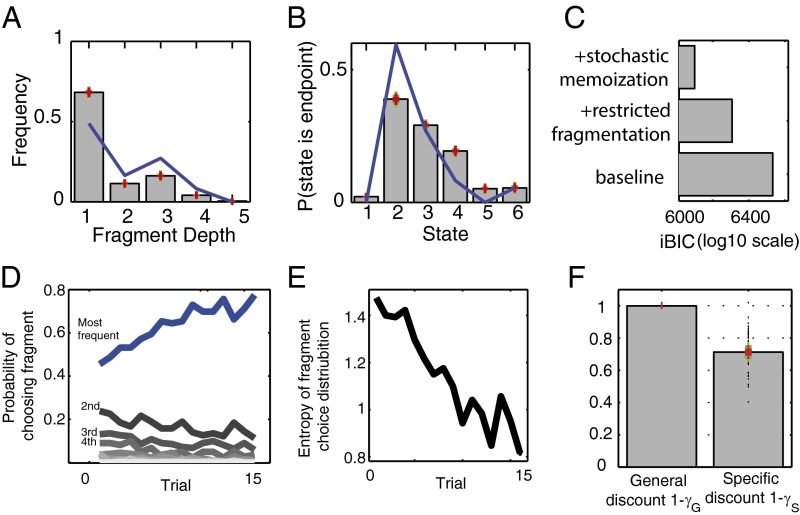
Comment in
-
How to divide and conquer the world, one step at a time.Proc Natl Acad Sci U S A. 2015 Mar 10;112(10):2929-30. doi: 10.1073/pnas.1500975112. Epub 2015 Mar 2. Proc Natl Acad Sci U S A. 2015. PMID: 25733879 Free PMC article. No abstract available.
Similar articles
-
The Neural Basis of Aversive Pavlovian Guidance during Planning.J Neurosci. 2017 Oct 18;37(42):10215-10229. doi: 10.1523/JNEUROSCI.0085-17.2017. Epub 2017 Sep 18. J Neurosci. 2017. PMID: 28924006 Free PMC article.
-
Heuristic pruning of decision trees at low probabilities and probability discounting in sequential planning in young and older adults.Sci Rep. 2025 May 9;15(1):16260. doi: 10.1038/s41598-025-00905-7. Sci Rep. 2025. PMID: 40346145 Free PMC article.
-
Habitual control of goal selection in humans.Proc Natl Acad Sci U S A. 2015 Nov 10;112(45):13817-22. doi: 10.1073/pnas.1506367112. Epub 2015 Oct 12. Proc Natl Acad Sci U S A. 2015. PMID: 26460050 Free PMC article.
-
The role of prediction and outcomes in adaptive cognitive control.J Physiol Paris. 2015 Feb-Jun;109(1-3):38-52. doi: 10.1016/j.jphysparis.2015.02.001. Epub 2015 Feb 17. J Physiol Paris. 2015. PMID: 25698177 Review.
-
Dynamic planning in hierarchical active inference.Neural Netw. 2025 May;185:107075. doi: 10.1016/j.neunet.2024.107075. Epub 2025 Jan 8. Neural Netw. 2025. PMID: 39817980 Review.
Cited by
-
Modeling Search Behaviors during the Acquisition of Expertise in a Sequential Decision-Making Task.Front Comput Neurosci. 2017 Sep 8;11:80. doi: 10.3389/fncom.2017.00080. eCollection 2017. Front Comput Neurosci. 2017. PMID: 28943847 Free PMC article.
-
Optimizing competence in the service of collaboration.Cogn Psychol. 2024 May;150:101653. doi: 10.1016/j.cogpsych.2024.101653. Epub 2024 Mar 18. Cogn Psychol. 2024. PMID: 38503178 Free PMC article.
-
Rational use of cognitive resources in human planning.Nat Hum Behav. 2022 Aug;6(8):1112-1125. doi: 10.1038/s41562-022-01332-8. Epub 2022 Apr 28. Nat Hum Behav. 2022. PMID: 35484209
-
What to Choose Next? A Paradigm for Testing Human Sequential Decision Making.Front Psychol. 2017 Mar 7;8:312. doi: 10.3389/fpsyg.2017.00312. eCollection 2017. Front Psychol. 2017. PMID: 28326050 Free PMC article.
-
Songbirds work around computational complexity by learning song vocabulary independently of sequence.Nat Commun. 2017 Nov 1;8(1):1247. doi: 10.1038/s41467-017-01436-0. Nat Commun. 2017. PMID: 29089517 Free PMC article.
References
-
- Sutton RS, Precup D, Singh S. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning. Artif Intell. 1999;112:181–211.
-
- Daw ND, Niv Y, Dayan P. Uncertainty-based competition between prefrontal and dorsolateral striatal systems for behavioral control. Nat Neurosci. 2005;8(12):1704–1711. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
