

Extracting drug-drug interactions from literature using a rich feature-based linear kernel approach
- PMID: 25796456
- PMCID: PMC4464931
- DOI: 10.1016/j.jbi.2015.03.002
Extracting drug-drug interactions from literature using a rich feature-based linear kernel approach
Abstract
Identifying unknown drug interactions is of great benefit in the early detection of adverse drug reactions. Despite existence of several resources for drug-drug interaction (DDI) information, the wealth of such information is buried in a body of unstructured medical text which is growing exponentially. This calls for developing text mining techniques for identifying DDIs. The state-of-the-art DDI extraction methods use Support Vector Machines (SVMs) with non-linear composite kernels to explore diverse contexts in literature. While computationally less expensive, linear kernel-based systems have not achieved a comparable performance in DDI extraction tasks. In this work, we propose an efficient and scalable system using a linear kernel to identify DDI information. The proposed approach consists of two steps: identifying DDIs and assigning one of four different DDI types to the predicted drug pairs. We demonstrate that when equipped with a rich set of lexical and syntactic features, a linear SVM classifier is able to achieve a competitive performance in detecting DDIs. In addition, the one-against-one strategy proves vital for addressing an imbalance issue in DDI type classification. Applied to the DDIExtraction 2013 corpus, our system achieves an F1 score of 0.670, as compared to 0.651 and 0.609 reported by the top two participating teams in the DDIExtraction 2013 challenge, both based on non-linear kernel methods.
Keywords: Biomedical literature; Drug–drug interaction; Linear kernel approach.
Published by Elsevier Inc.
Figures
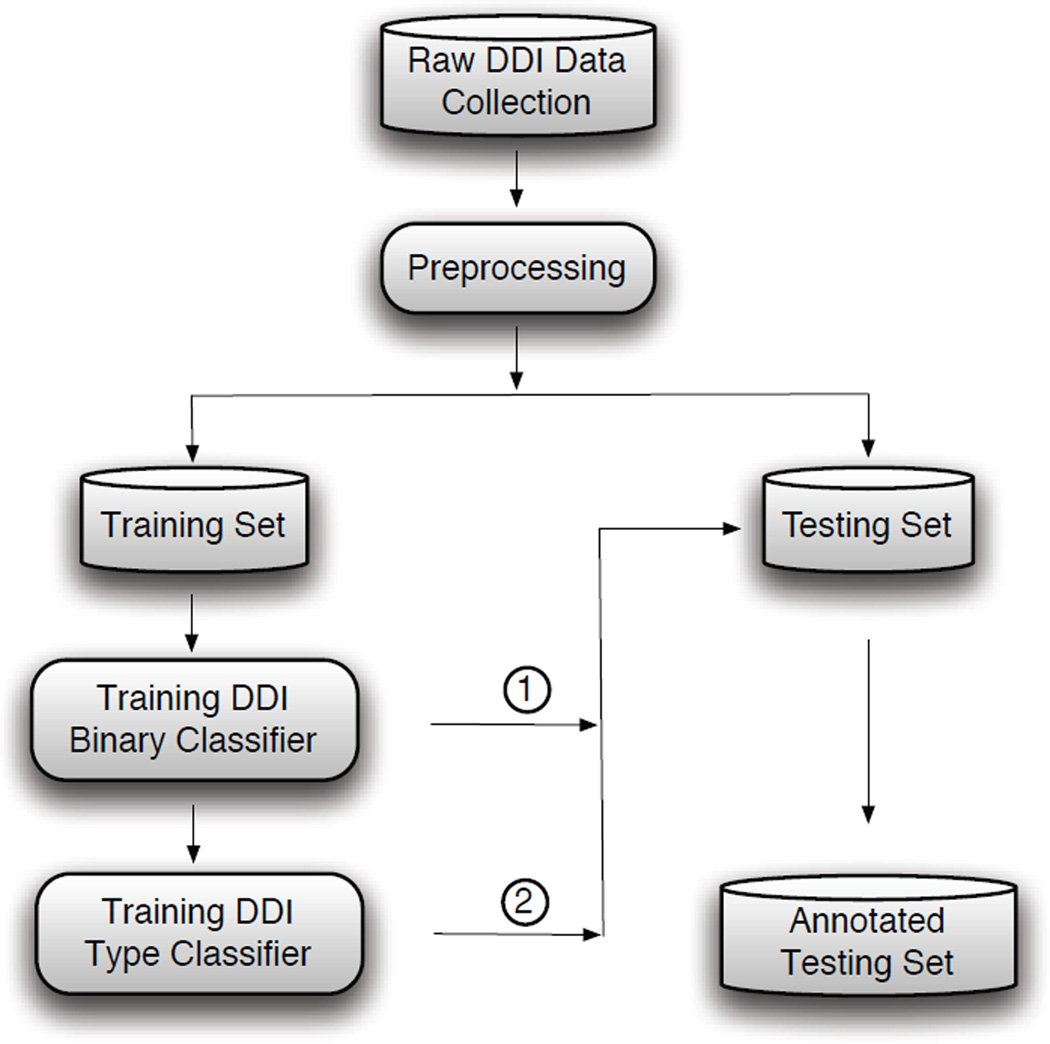
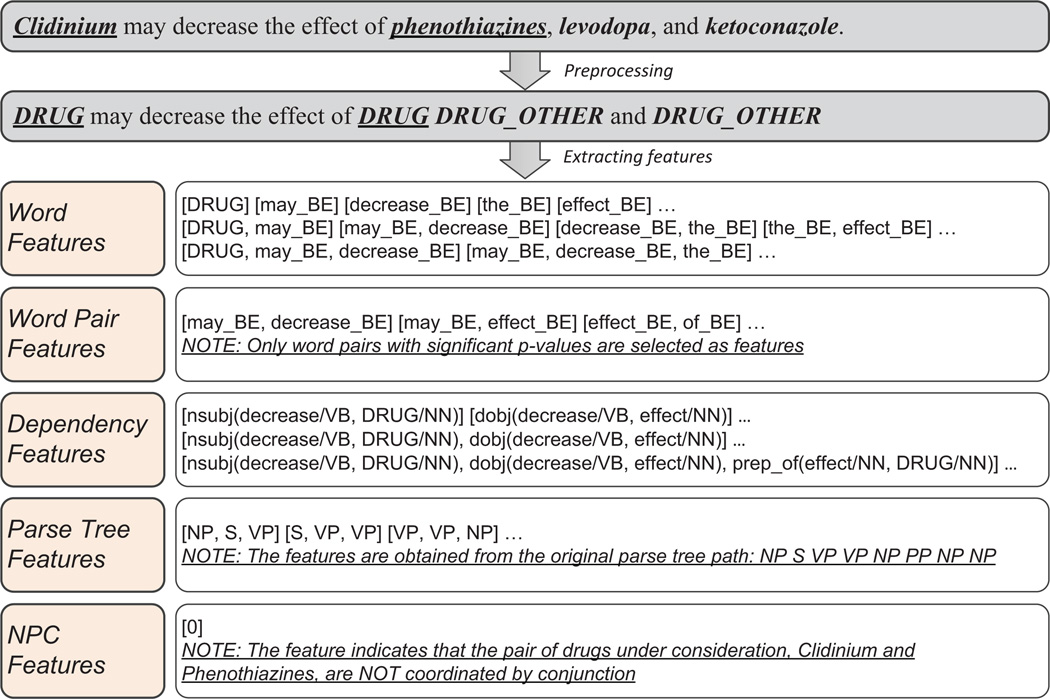



References
-
- Baxter K, Preston CL, editors. Stockley’s Drug Interactions. London, UK: Pharmaceutical Press; 2013.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
