

Model-based learning protects against forming habits
- PMID: 25801925
- PMCID: PMC4526597
- DOI: 10.3758/s13415-015-0347-6
Model-based learning protects against forming habits
Abstract
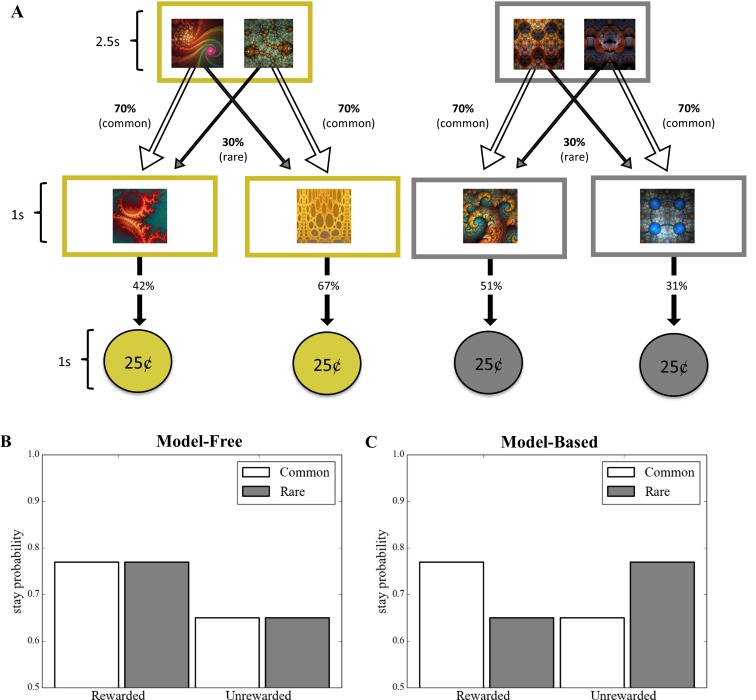
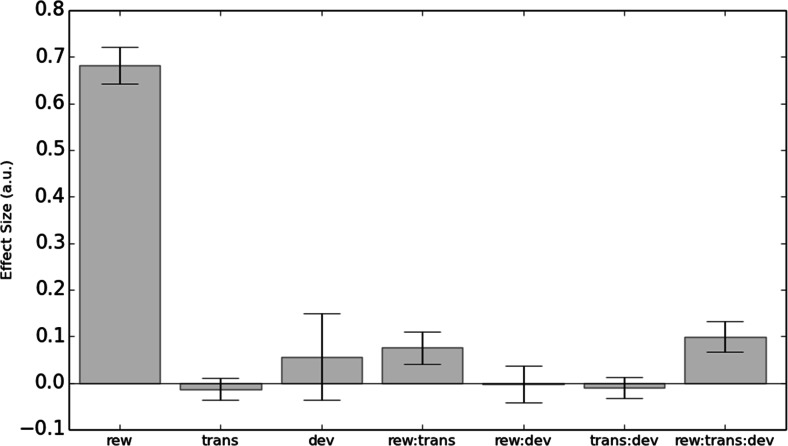
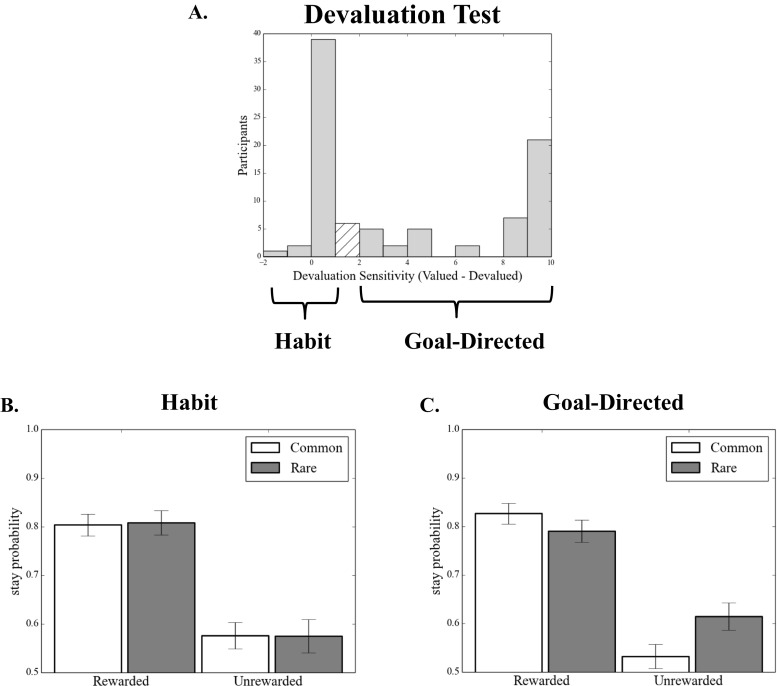
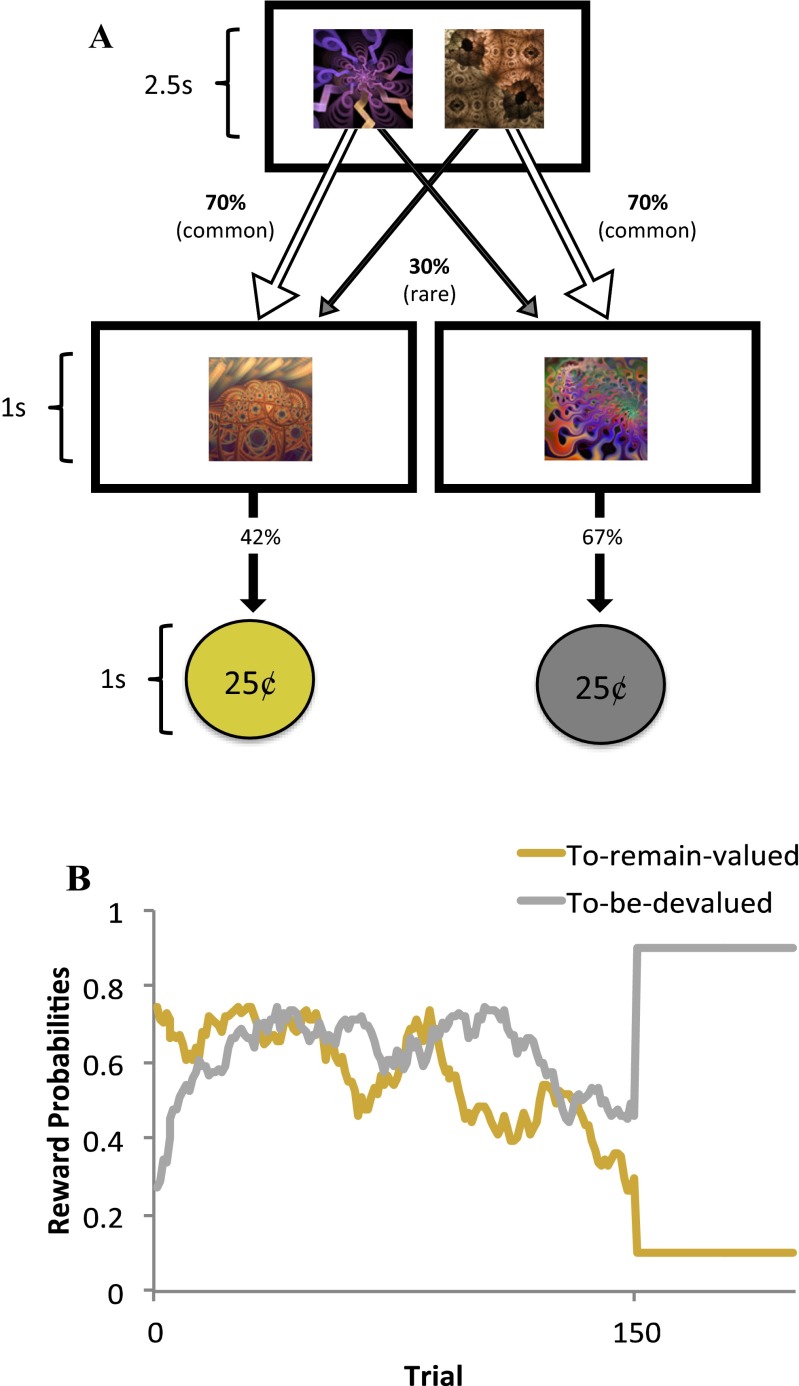
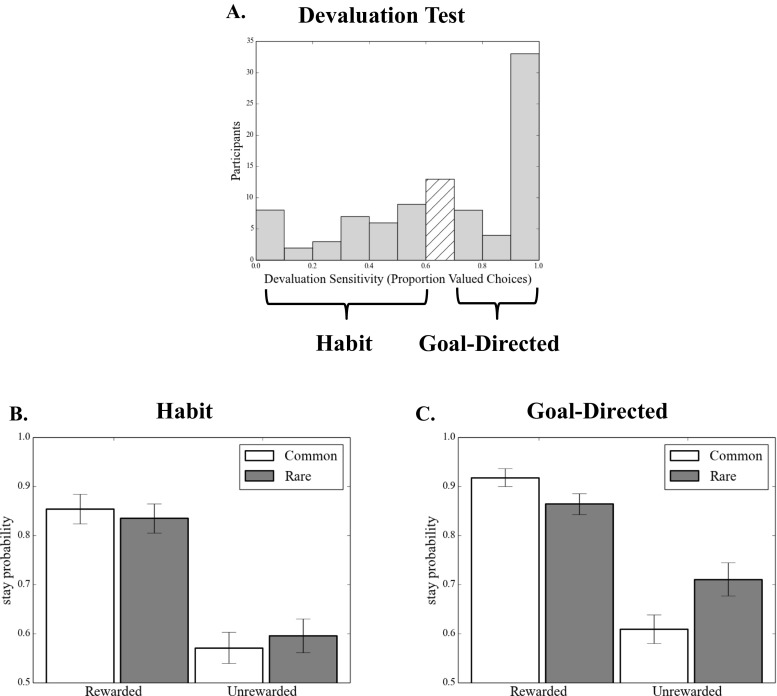
Studies in humans and rodents have suggested that behavior can at times be "goal-directed"-that is, planned, and purposeful-and at times "habitual"-that is, inflexible and automatically evoked by stimuli. This distinction is central to conceptions of pathological compulsion, as in drug abuse and obsessive-compulsive disorder. Evidence for the distinction has primarily come from outcome devaluation studies, in which the sensitivity of a previously learned behavior to motivational change is used to assay the dominance of habits versus goal-directed actions. However, little is known about how habits and goal-directed control arise. Specifically, in the present study we sought to reveal the trial-by-trial dynamics of instrumental learning that would promote, and protect against, developing habits. In two complementary experiments with independent samples, participants completed a sequential decision task that dissociated two computational-learning mechanisms, model-based and model-free. We then tested for habits by devaluing one of the rewards that had reinforced behavior. In each case, we found that individual differences in model-based learning predicted the participants' subsequent sensitivity to outcome devaluation, suggesting that an associative mechanism underlies a bias toward habit formation in healthy individuals.
Figures

References
-
- Adams CD. Variations in the sensitivity of instrumental responding to reinforcer devaluation. Quarterly Journal of Experimental Psychology. 1982;34B:77–98. doi: 10.1080/14640748208400878. - DOI
-
- Adams CD, Dickinson A. Instrumental responding following reinforcer devaluation. Quarterly Journal of Experimental Psychology. 1981;33B:109–121. doi: 10.1080/14640748108400816. - DOI
-
- Akam, T., Dayan, P., & Costa, R. (2013). Multi-step decision tasks for dissociating model-based and model-free learning in rodents. Paper presented at the Cosyne 2013, Salt Lake City, UT.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
