

The effect of cluster size variability on statistical power in cluster-randomized trials
- PMID: 25830416
- PMCID: PMC4382318
- DOI: 10.1371/journal.pone.0119074
The effect of cluster size variability on statistical power in cluster-randomized trials
Abstract
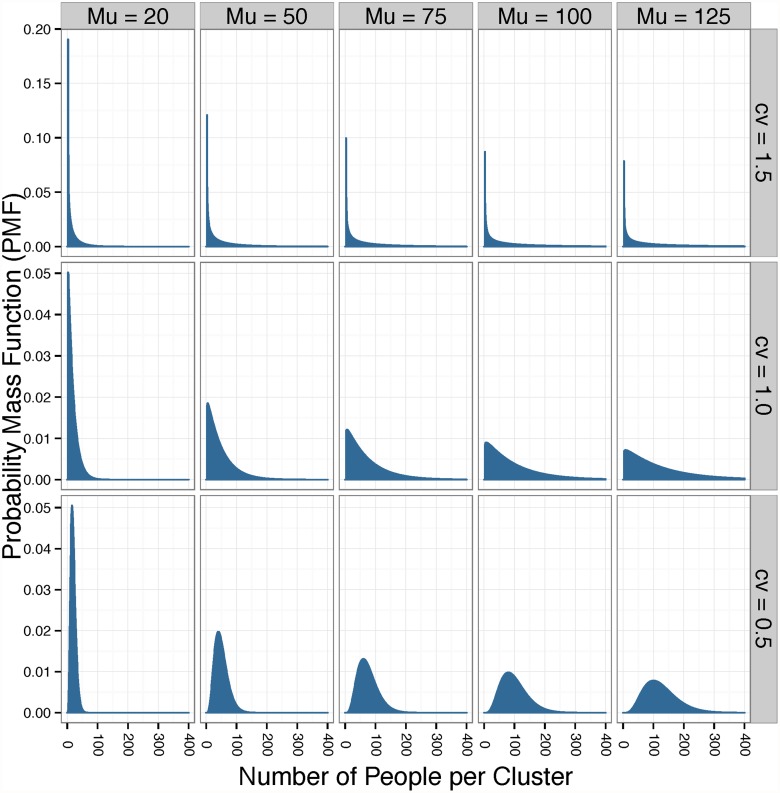
The frequency of cluster-randomized trials (CRTs) in peer-reviewed literature has increased exponentially over the past two decades. CRTs are a valuable tool for studying interventions that cannot be effectively implemented or randomized at the individual level. However, some aspects of the design and analysis of data from CRTs are more complex than those for individually randomized controlled trials. One of the key components to designing a successful CRT is calculating the proper sample size (i.e. number of clusters) needed to attain an acceptable level of statistical power. In order to do this, a researcher must make assumptions about the value of several variables, including a fixed mean cluster size. In practice, cluster size can often vary dramatically. Few studies account for the effect of cluster size variation when assessing the statistical power for a given trial. We conducted a simulation study to investigate how the statistical power of CRTs changes with variable cluster sizes. In general, we observed that increases in cluster size variability lead to a decrease in power.
Trial registration: ClinicalTrials.gov NCT01249625.
Conflict of interest statement
Figures



References
-
- Donner A, Birkett N, Buck C (1981) Randomization by cluster: sample size requirements and analysis. American Journal of Epidemiology 114: 906–914. - PubMed
Publication types
MeSH terms
Associated data
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Research Materials
Miscellaneous
