

Identification and Prioritization of Relationships between Environmental Stressors and Adverse Human Health Impacts
- PMID: 25859761
- PMCID: PMC4629746
- DOI: 10.1289/ehp.1409138
Identification and Prioritization of Relationships between Environmental Stressors and Adverse Human Health Impacts
Abstract
Background: There are > 80,000 chemicals in commerce with few data available describing their impacts on human health. Biomonitoring surveys, such as the NHANES (National Health and Nutrition Examination Survey), offer one route to identifying possible relationships between environmental chemicals and health impacts, but sparse data and the complexity of traditional models make it difficult to leverage effectively.
Objective: We describe a workflow to efficiently and comprehensively evaluate and prioritize chemical-health impact relationships from the NHANES biomonitoring survey studies.
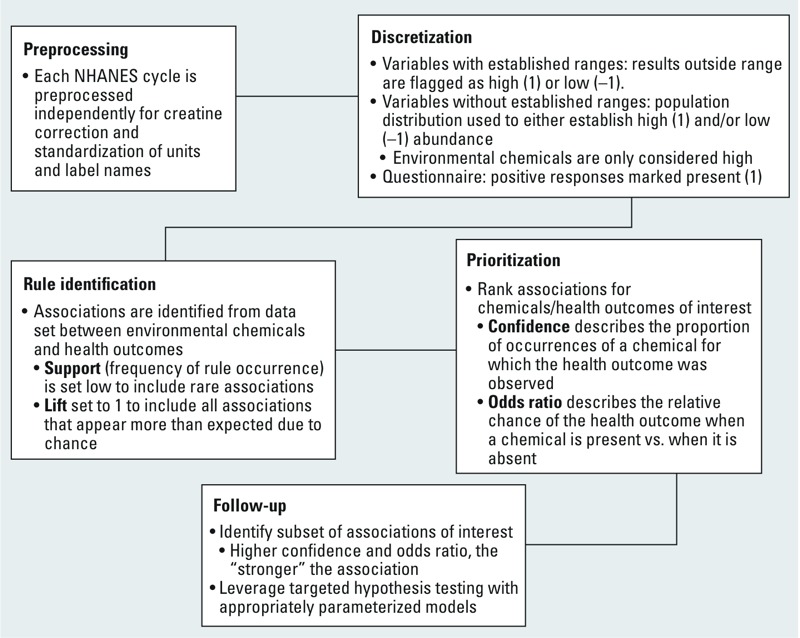
Methods: Using a frequent itemset mining (FIM) approach, we identified relationships between chemicals and health biomarkers and diseases.
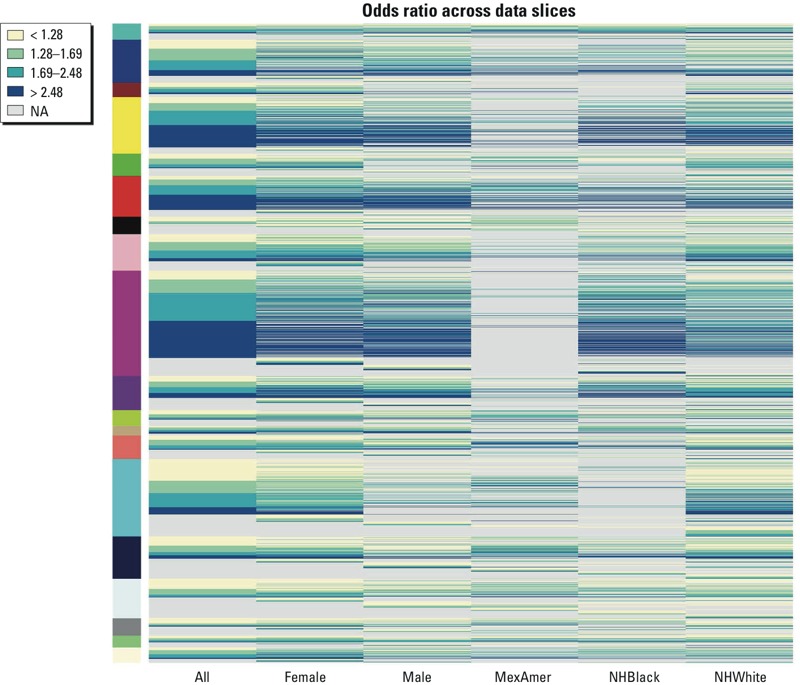
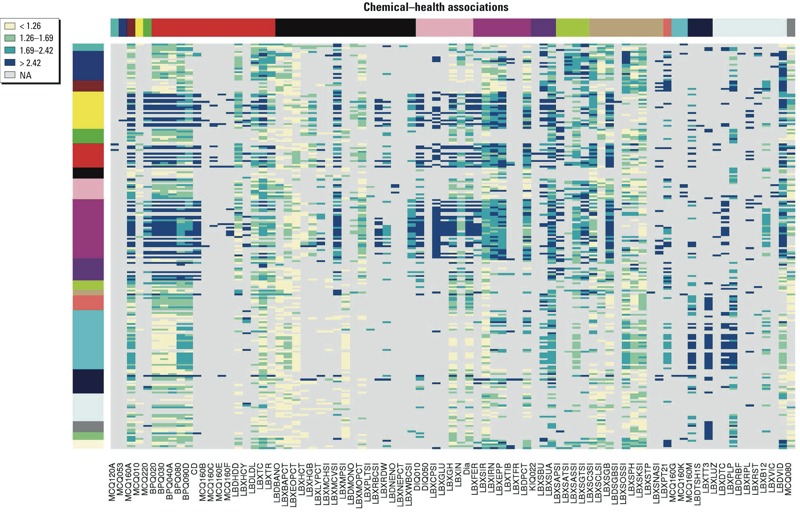
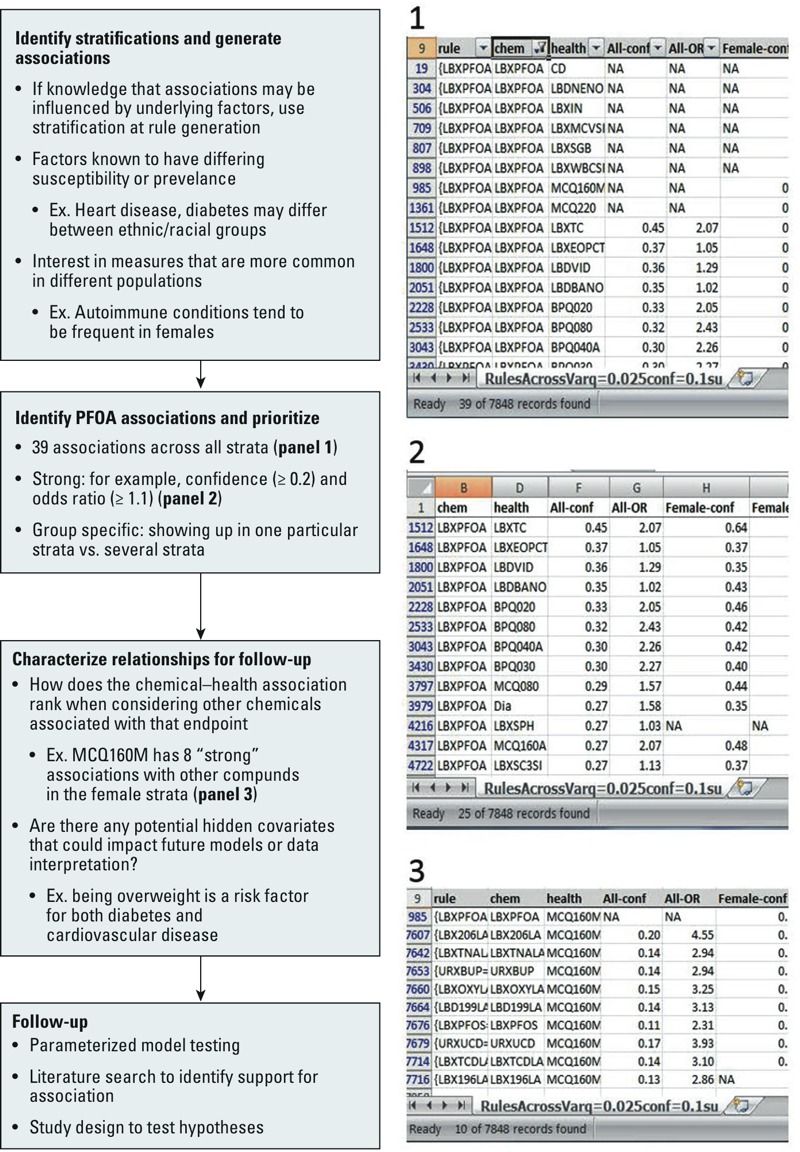
Results: The FIM method identified 7,848 relationships between 219 chemicals and 93 health outcomes/biomarkers. Two case studies used to evaluate the FIM rankings demonstrate that the FIM approach is able to identify published relationships. Because the relationships are derived from the vast majority of the chemicals monitored by NHANES, the resulting list of associations is appropriate for evaluating results from targeted data mining or identifying novel candidate relationships for more detailed investigation.
Conclusions: Because of the computational efficiency of the FIM method, all chemicals and health effects can be considered in a single analysis. The resulting list provides a comprehensive summary of the chemical/health co-occurrences from NHANES that are higher than expected by chance. This information enables ranking and prioritization on chemicals or health effects of interest for evaluation of published results and design of future studies.
Citation: Bell SM, Edwards SW. 2015. Identification and prioritization of relationships between environmental stressors and adverse human health impacts. Environ Health Perspect 123:1193-1199; http://dx.doi.org/10.1289/ehp.1409138.
Conflict of interest statement
This document has been subjected to review by the National Health and Environmental Effects Research Laboratory and approved for publication. Approval does not signify that the contents reflect the views of the U.S. EPA, nor does mention of trade names or commercial products constitute endorsement or recommendation for use.
The authors declare they have no actual or potential competing financial interests.
Figures
References
-
- Agrawal R, Imielinski T, Swami A. Mining association rules between sets of items in large databases. In: Proc ACM SIGMOD Int Conf Manag Data. 1993;22:207–216.
-
- Bell SM, Edwards SW. In: Proceedings of the 2014 SIAM International Conference on Data Mining, 551–559; 2014. Building associations between markers of environmental stressors and adverse human health impacts using frequent itemset mining.
-
- Borgelt C. Efficient implementations of Apriori and Eclat. In: Proc IEEE ICDM Workshop FIMI. 2003. Available: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.162.291 [accessed 15 July 2014]
-
- Borgelt C. Frequent item set mining. Wiley Interdiscip Rev Data Min Knowl Discov. 2012;2:437–456.
-
- Borgelt C, Kruse R. Heidelberg, Germany: Physica, 395–400; 2002. Induction of association rules: Apriori implementation. In: Compstat 2002: Proceedings in Computational Statistics (Härdle W, Rönz B, eds)
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources