

Enzyme Function Initiative-Enzyme Similarity Tool (EFI-EST): A web tool for generating protein sequence similarity networks
- PMID: 25900361
- PMCID: PMC4457552
- DOI: 10.1016/j.bbapap.2015.04.015
Enzyme Function Initiative-Enzyme Similarity Tool (EFI-EST): A web tool for generating protein sequence similarity networks
Abstract
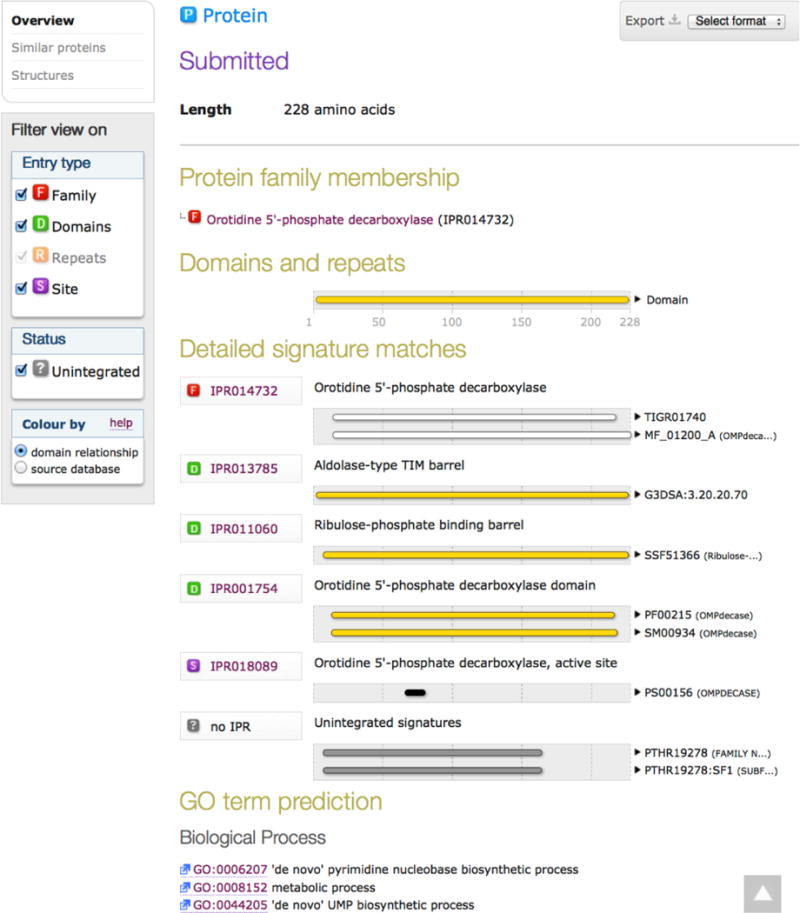
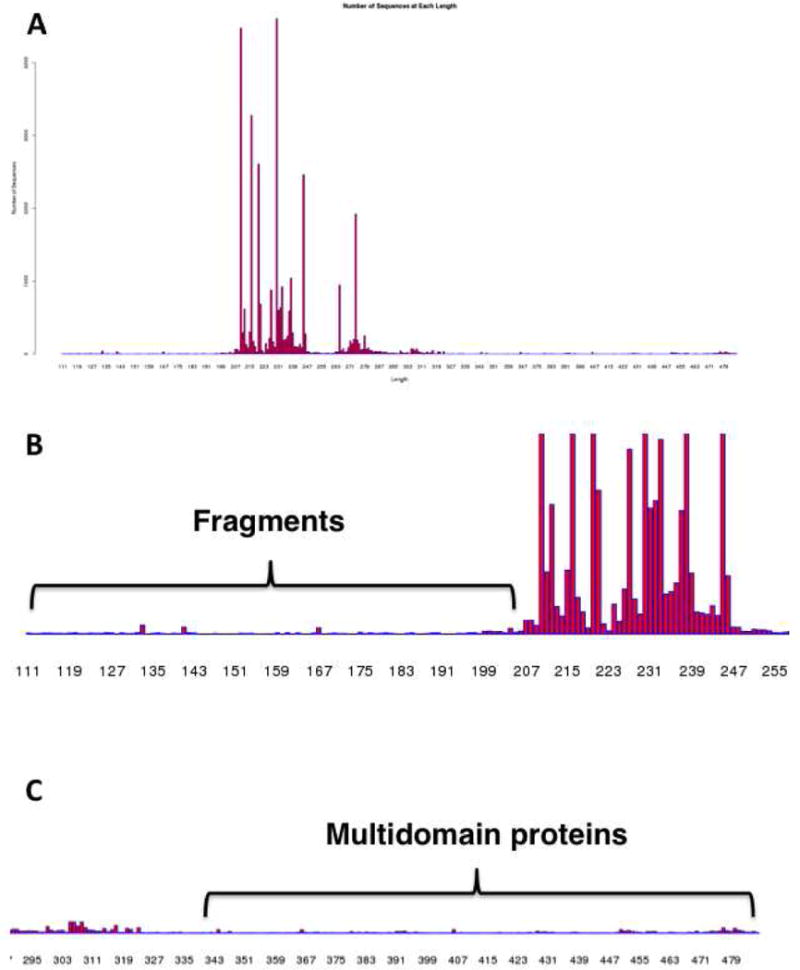
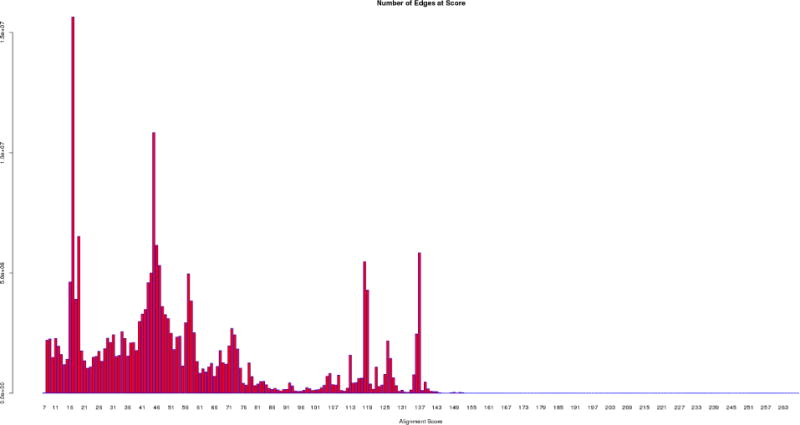
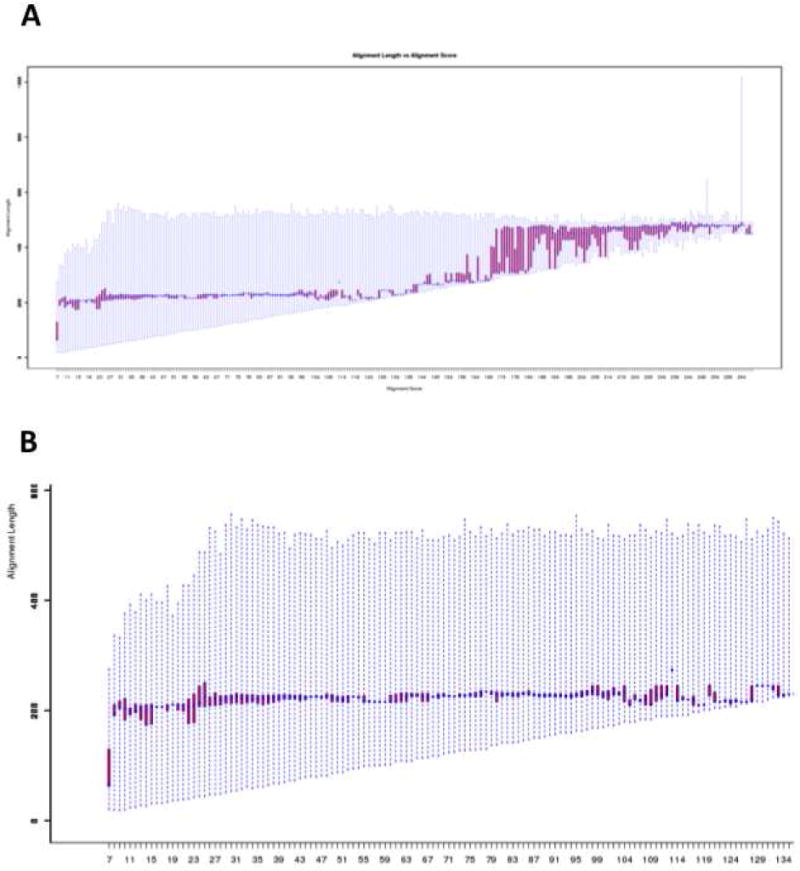
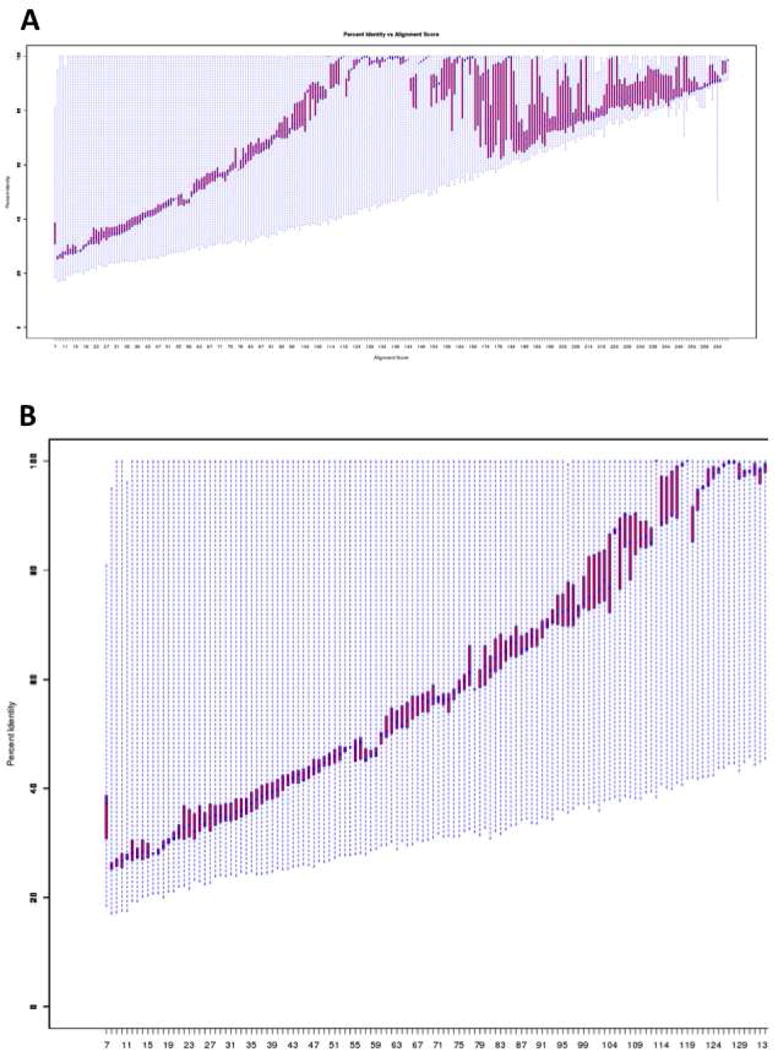
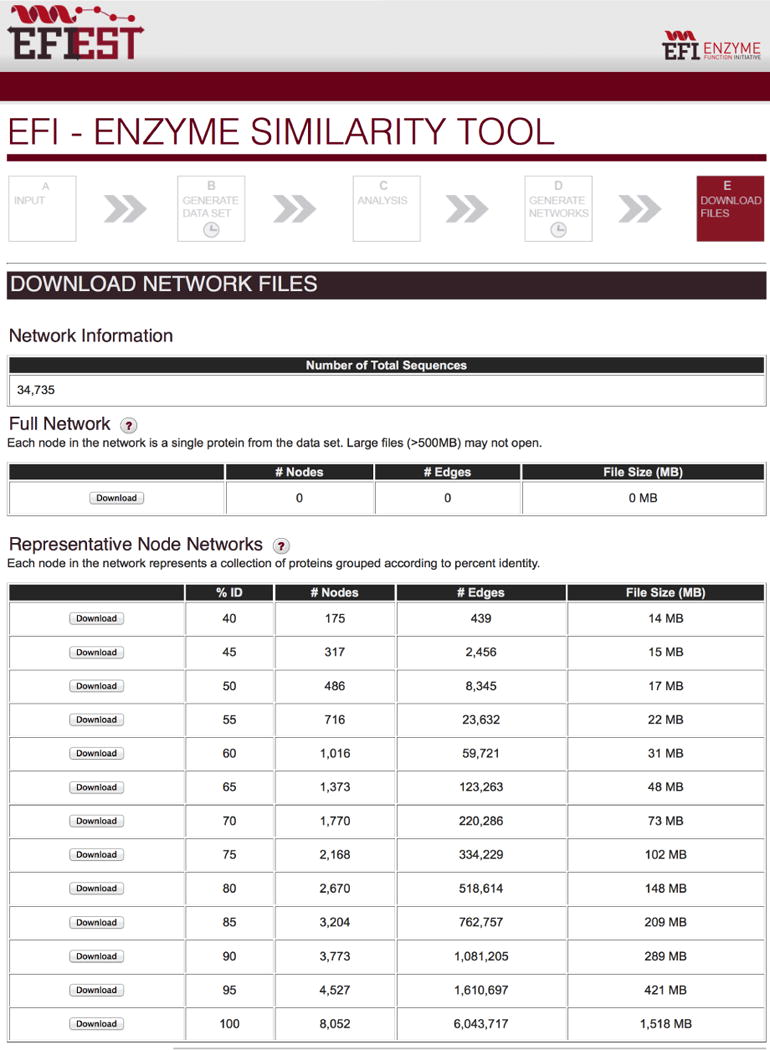
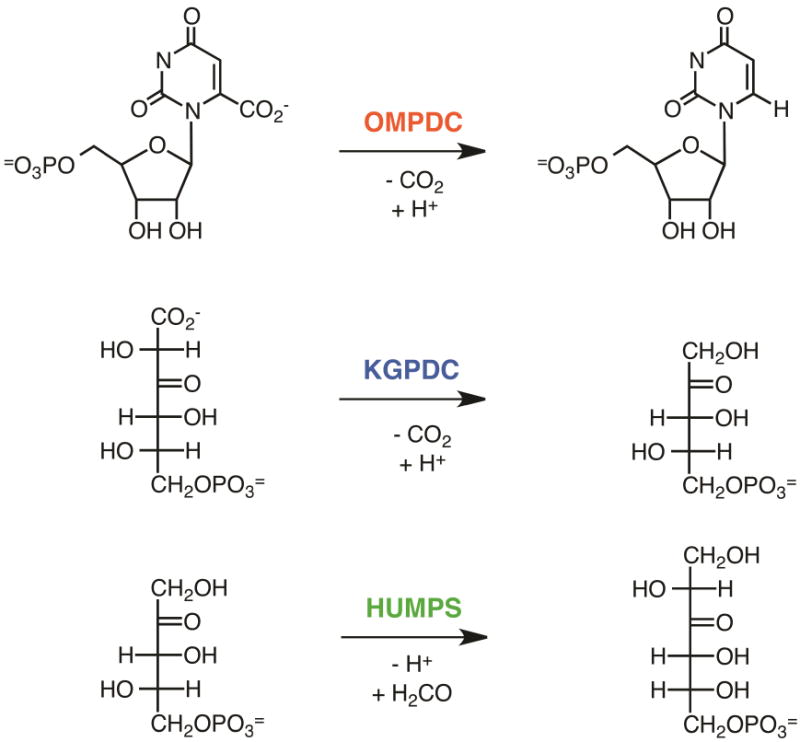
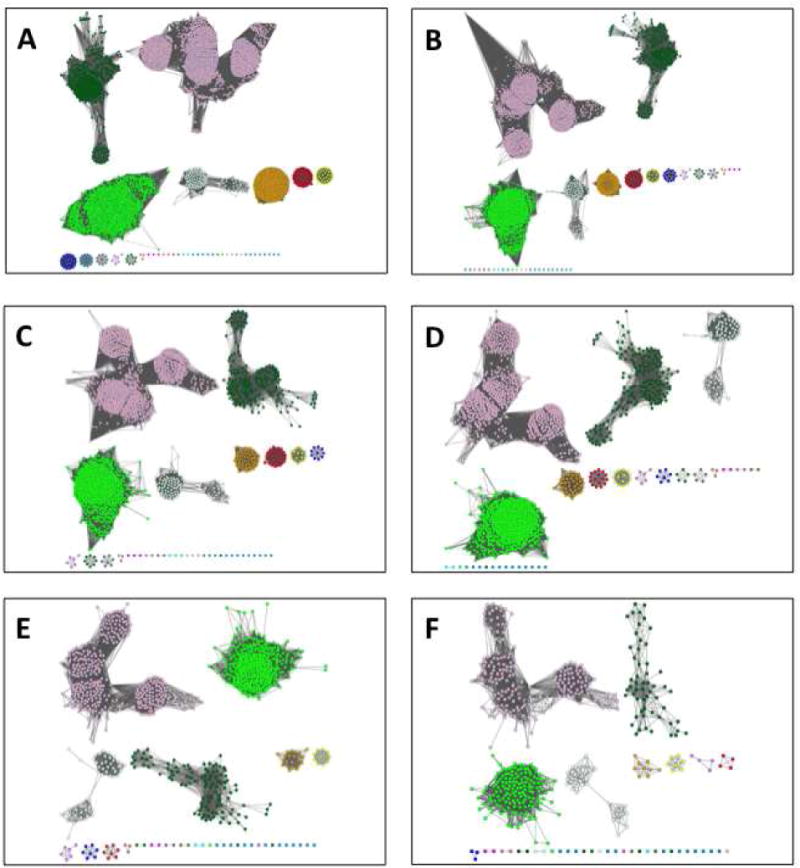
The Enzyme Function Initiative, an NIH/NIGMS-supported Large-Scale Collaborative Project (EFI; U54GM093342; http://enzymefunction.org/), is focused on devising and disseminating bioinformatics and computational tools as well as experimental strategies for the prediction and assignment of functions (in vitro activities and in vivo physiological/metabolic roles) to uncharacterized enzymes discovered in genome projects. Protein sequence similarity networks (SSNs) are visually powerful tools for analyzing sequence relationships in protein families (H.J. Atkinson, J.H. Morris, T.E. Ferrin, and P.C. Babbitt, PLoS One 2009, 4, e4345). However, the members of the biological/biomedical community have not had access to the capability to generate SSNs for their "favorite" protein families. In this article we announce the EFI-EST (Enzyme Function Initiative-Enzyme Similarity Tool) web tool (http://efi.igb.illinois.edu/efi-est/) that is available without cost for the automated generation of SSNs by the community. The tool can create SSNs for the "closest neighbors" of a user-supplied protein sequence from the UniProt database (Option A) or of members of any user-supplied Pfam and/or InterPro family (Option B). We provide an introduction to SSNs, a description of EFI-EST, and a demonstration of the use of EFI-EST to explore sequence-function space in the OMP decarboxylase superfamily (PF00215). This article is designed as a tutorial that will allow members of the community to use the EFI-EST web tool for exploring sequence/function space in protein families.
Keywords: Enzyme; Function discovery; Protein family; Protein sequence analysis; Web tool.
Copyright © 2015 Elsevier B.V. All rights reserved.
Figures



References
-
- Caspi R, Altman T, Billington R, Dreher K, Foerster H, Fulcher CA, Holland TA, Keseler IM, Kothari A, Kubo A, Krummenacker M, Latendresse M, Mueller LA, Ong Q, Paley S, Subhraveti P, Weaver DS, Weerasinghe D, Zhang P, Karp PD. The MetaCyc database of metabolic pathways and enzymes and the BioCyc collection of Pathway/Genome Databases. Nucleic Acids Res. 2014;42:D459–71. - PMC - PubMed
-
- Zhao S, Sakai A, Zhang X, Vetting MW, Kumar R, Hillerich B, San Francisco B, Solbiati J, Steves A, Brown S, Akiva E, Barber A, Seidel RD, Babbitt PC, Almo SC, Gerlt JA, Jacobson MP. Prediction and characterization of enzymatic activities guided by sequence similarity and genome neighborhood networks. Elife. 2014:3. - PMC - PubMed
-
- Hermann JC, Ghanem E, Li Y, Raushel FM, Irwin JJ, Shoichet BK. Predicting substrates by docking high-energy intermediates to enzyme structures. J Am Chem Soc. 2006;128:15882–91. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
