

ProtoBug: functional families from the complete proteomes of insects
- PMID: 25911153
- PMCID: PMC4408594
- DOI: 10.1093/database/bau122
ProtoBug: functional families from the complete proteomes of insects
Abstract
ProtoBug (http://www.protobug.cs.huji.ac.il) is a database and resource of protein families in Arthropod genomes. ProtoBug platform presents the relatedness of complete proteomes from 17 insects as well as a proteome of the crustacean, Daphnia pulex. The represented proteomes from insects include louse, bee, beetle, ants, flies and mosquitoes. Based on an unsupervised clustering method, protein sequences were clustered into a hierarchical tree, called ProtoBug. ProtoBug covers about 300,000 sequences that are partitioned to families. At the default setting, all sequences are partitioned to ∼20,000 families (excluding singletons). From the species perspective, each of the 18 analysed proteomes is composed of 5000-8000 families. In the regime of the advanced operational mode, the ProtoBug provides rich navigation capabilities for touring the hierarchy of the families at any selected resolution. A proteome viewer shows the composition of sequences from any of the 18 analysed proteomes. Using functional annotation from an expert system (Pfam) we assigned domains, families and repeats by 4400 keywords that cover 73% of the sequences. A strict inference protocol is applied for expanding the functional knowledge. Consequently, secured annotations were associated with 81% of the proteins, and with 70% of the families (≥10 proteins each). ProtoBug is a database and webtool with rich visualization and navigation tools. The properties of each family in relation to other families in the ProtoBug tree, and in view of the taxonomy composition are reported. Furthermore, the user can paste its own sequences to find relatedness to any of the ProtoBug families. The database and the navigation tools are the basis for functional discoveries that span 350 million years of evolution of Arthropods. ProtoBug is available with no restriction at: www.protobug.cs.huji.ac.il. Database URL: www.protobug.cs.huji.ac.il
© The Author 2015. Published by Oxford University Press.
Figures
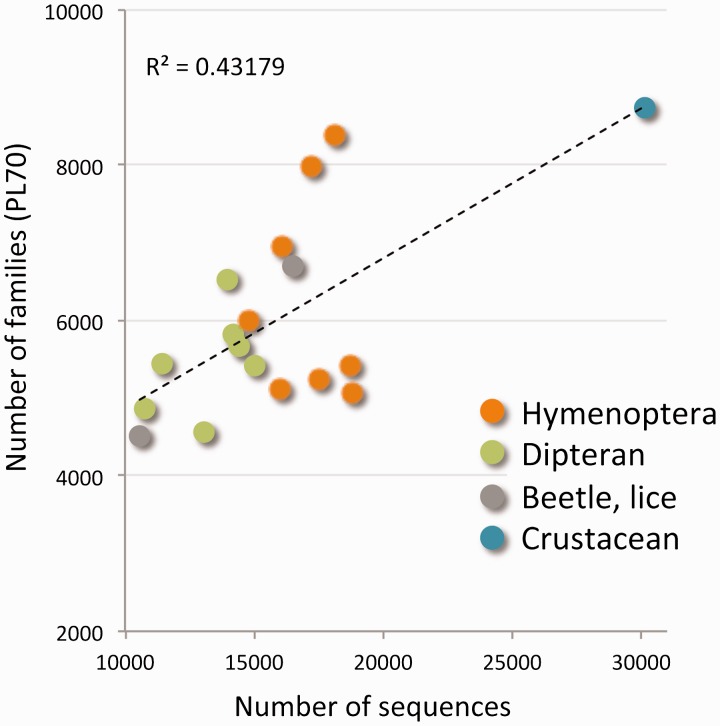
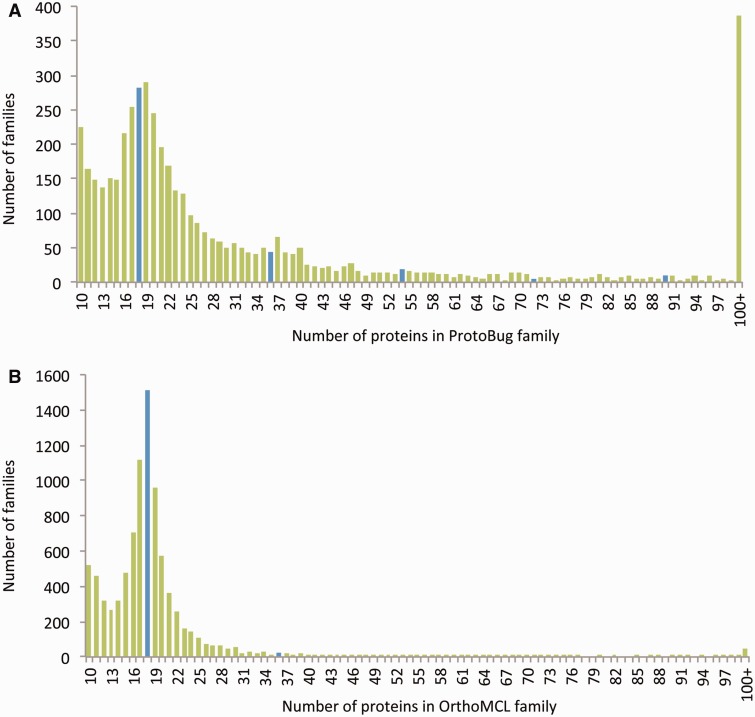
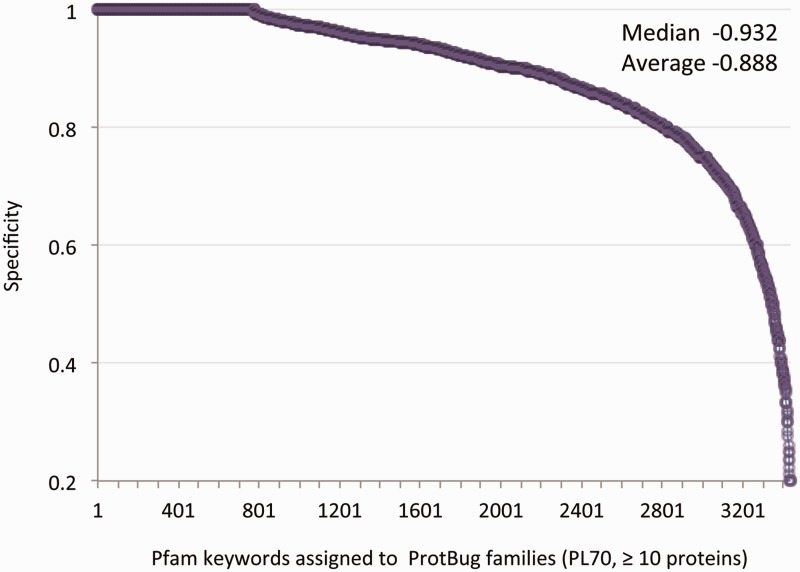
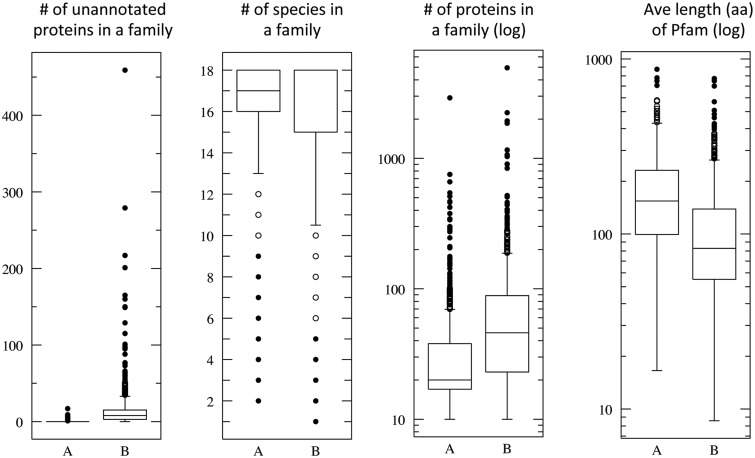
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
