

Learning the opportunity cost of time in a patch-foraging task
- PMID: 25917000
- PMCID: PMC4624618
- DOI: 10.3758/s13415-015-0350-y
Learning the opportunity cost of time in a patch-foraging task
Abstract
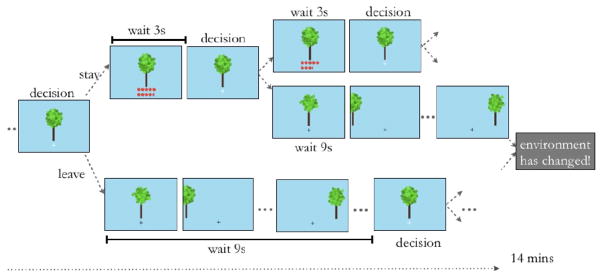
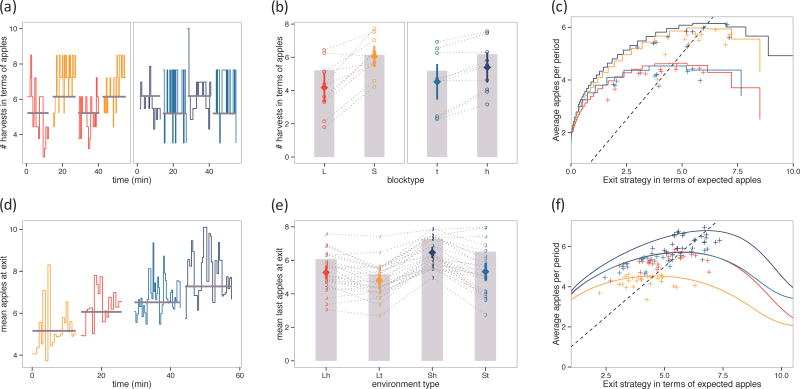
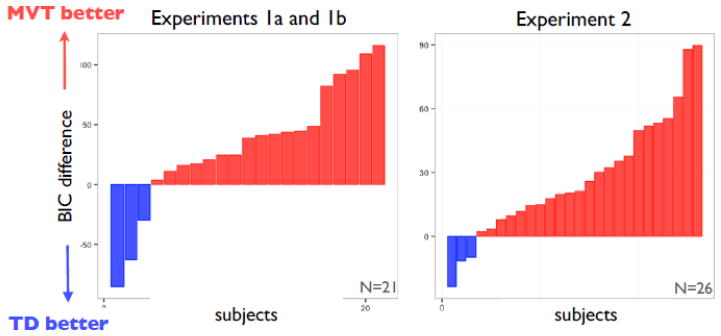
Although most decision research concerns choice between simultaneously presented options, in many situations options are encountered serially, and the decision is whether to exploit an option or search for a better one. Such problems have a rich history in animal foraging, but we know little about the psychological processes involved. In particular, it is unknown whether learning in these problems is supported by the well-studied neurocomputational mechanisms involved in more conventional tasks. We investigated how humans learn in a foraging task, which requires deciding whether to harvest a depleting resource or switch to a replenished one. The optimal choice (given by the marginal value theorem; MVT) requires comparing the immediate return from harvesting to the opportunity cost of time, which is given by the long-run average reward. In two experiments, we varied opportunity cost across blocks, and subjects adjusted their behavior to blockwise changes in environmental characteristics. We examined how subjects learned their choice strategies by comparing choice adjustments to a learning rule suggested by the MVT (in which the opportunity cost threshold is estimated as an average over previous rewards) and to the predominant incremental-learning theory in neuroscience, temporal-difference learning (TD). Trial-by-trial decisions were explained better by the MVT threshold-learning rule. These findings expand on the foraging literature, which has focused on steady-state behavior, by elucidating a computational mechanism for learning in switching tasks that is distinct from those used in traditional tasks, and suggest connections to research on average reward rates in other domains of neuroscience.
Keywords: Computational model; Decision making; Dopamine; Patch foraging; Reinforcement learning; Reward.
Figures
References
-
- Aston-Jones G, Cohen JD. An Integrative theory of locus coeruleus-norepinephrine function: adaptive gain and optimal performance. Annual Review of Neuroscience. 2005;28:403–450. - PubMed
-
- Barraclough DJ, Conroy ML, Lee D. Prefrontal cortex and decision making in a mixed-strategy game. Nature Neuroscience. 2004;7(4):404–10. - PubMed
-
- Baum WM. Choice in free-ranging wild pigeons. Science. 1974;185(4145):78–79. - PubMed
-
- Behrens TEJ, Woolrich MW, Walton ME, Rushworth MFS. Learning the value of information in an uncertain world. Nature Neuroscience. 2007;10(9):1214–1221. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
